

今天是2025年6月25日,星期四,北京,晴
我们回答文档智能进展,来看一个自动生成PPT 的项目,其中流程的设计,以及用到的爬虫代码以及Agent的prompt都可借鉴。
代码层面看MultiAgentPPT实现思路
关于PPT自动生成,看一个项目,MultiAgentPPT(https://github.com/johnson7788/MultiAgentPPT),基于A2A+MCP+ADK的多智能体系统,支持流式并发生成PPT,思路来源于https://github.com/allweonedev/presentation-ai
我们可以看看3个核心问题。
1、整体的实现流程是什么?
先从工作流的控制看起,如下:
其中可以具象化的整体实现流程如下图所示,分成4个Agent,
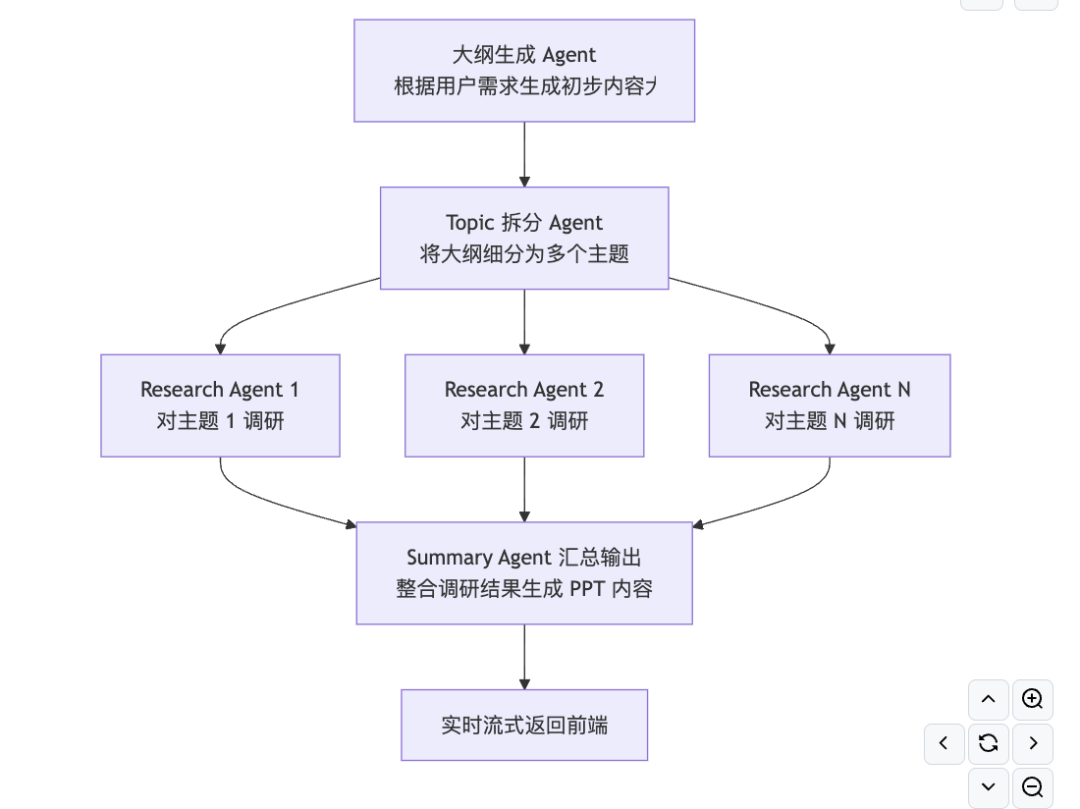
其中:
大纲生成Agent,根据用户需求生成初步内容大纲。
Topic拆分Agent,将大纲内容细分为多个主题;
ResearchAgent,并行工作,多个智能体分别对每个主题进行深入调研;
SummaryAgent,汇总输出,将调研结果汇总生成 PPT 内容,实时流式返回前端。
整个后端的逻辑在:https://github.com/johnson7788/MultiAgentPPT/tree/main/backend。
2、其中的数据从哪儿来?
既然是要生成内容,尤其是其中生成大纲以及内容,都会用到RAG,所以就会有知识库。
那么,知识库如果需要做到实时,那么就需要进行更新,所以可以爬虫,从代码上看,其从weixin_search.py中可以看到,其使用搜索搜索微信公众号文章,先关机关键词搜索搜狗,获取链接,然后使用get_real_url获取真实链接,最后使用真实链接获取公众号内容。
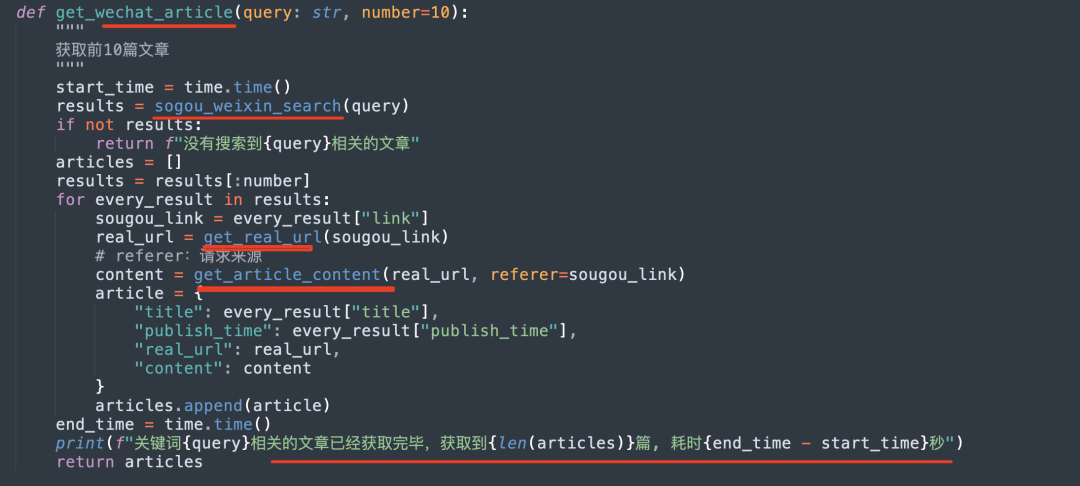
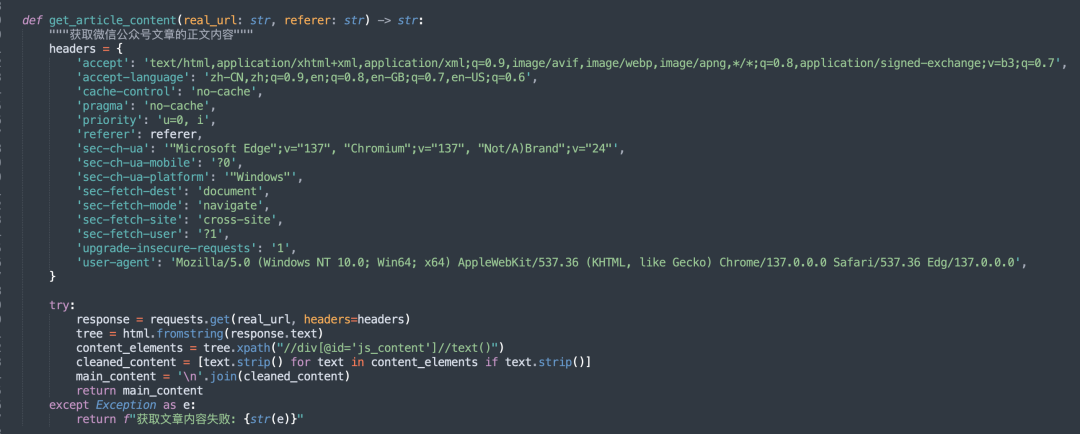
其中获取公众号内容如下:
3、从底层实现代码看每个子agent的执行逻辑
从代码上看如下,包括simpleOutline(用于前端测试的大纲生成)、simplePPT(用于前端测试的简单PPT生成)、slide_outline(用于前端的大纲生成,经过检索生成大纲)、slide_agent(根据大纲生成ppt)等组成部分。
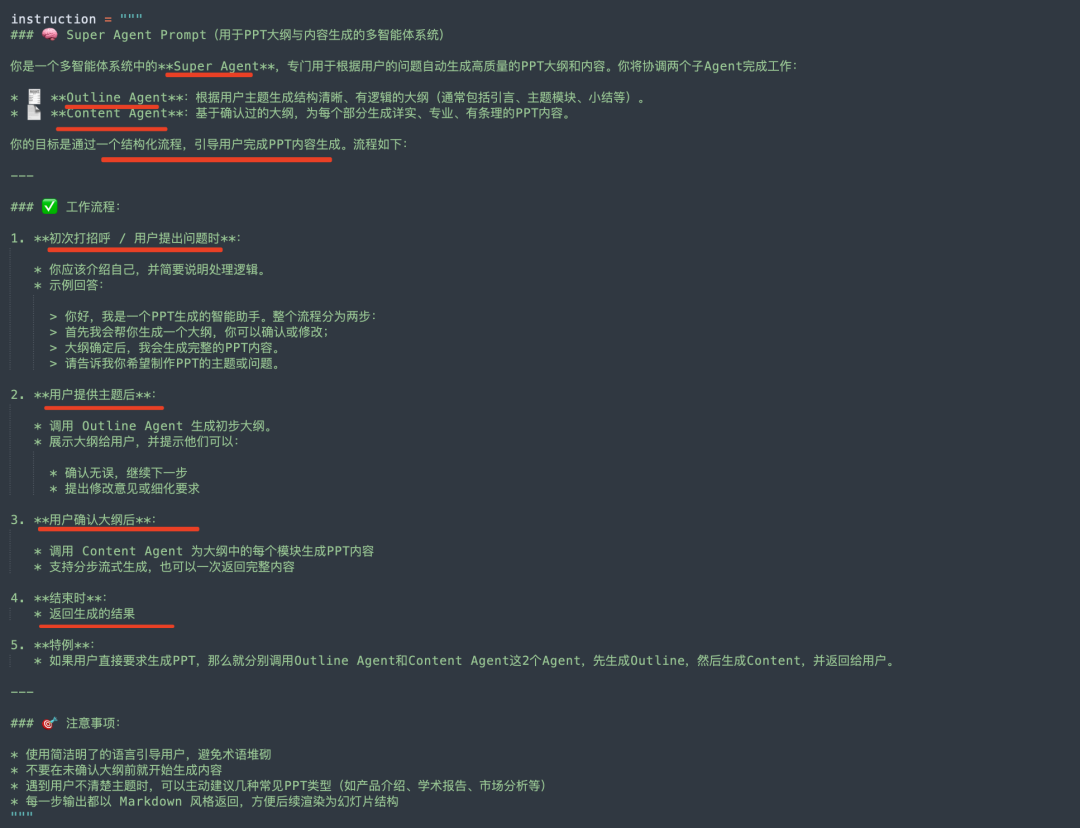
其中: slide_outline,使用rag,检索抓取形成的文章内容,然后组织成如下prompt送入LLM 进行生成:

slide_agent进一步分为第一个问题中的research_topic、split_topic、summary_writer几个工作组件,如下:

其中:
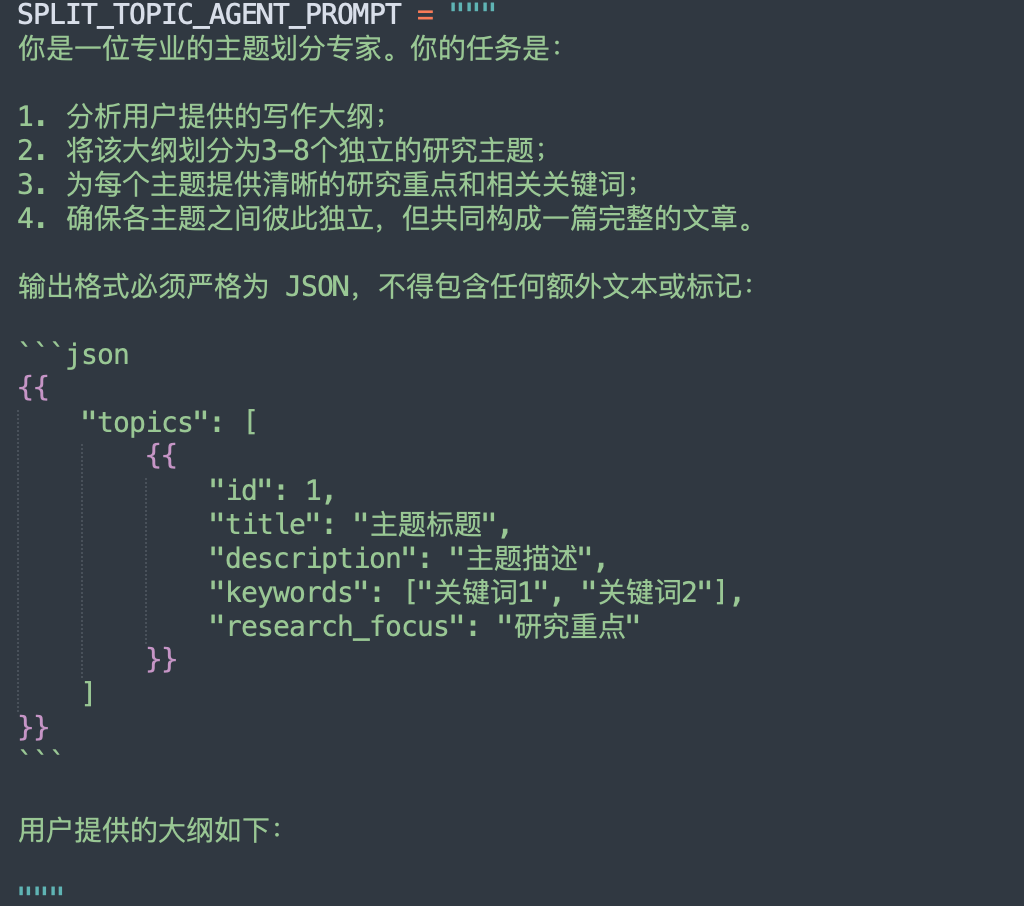
split_topic专门负责分析写作大纲并将其拆分成独立的研究主题,作用的prompt如下:
research_topic,根据拆分的主题,动态创建并行的研究员进行资料搜集,使用的prompt如下: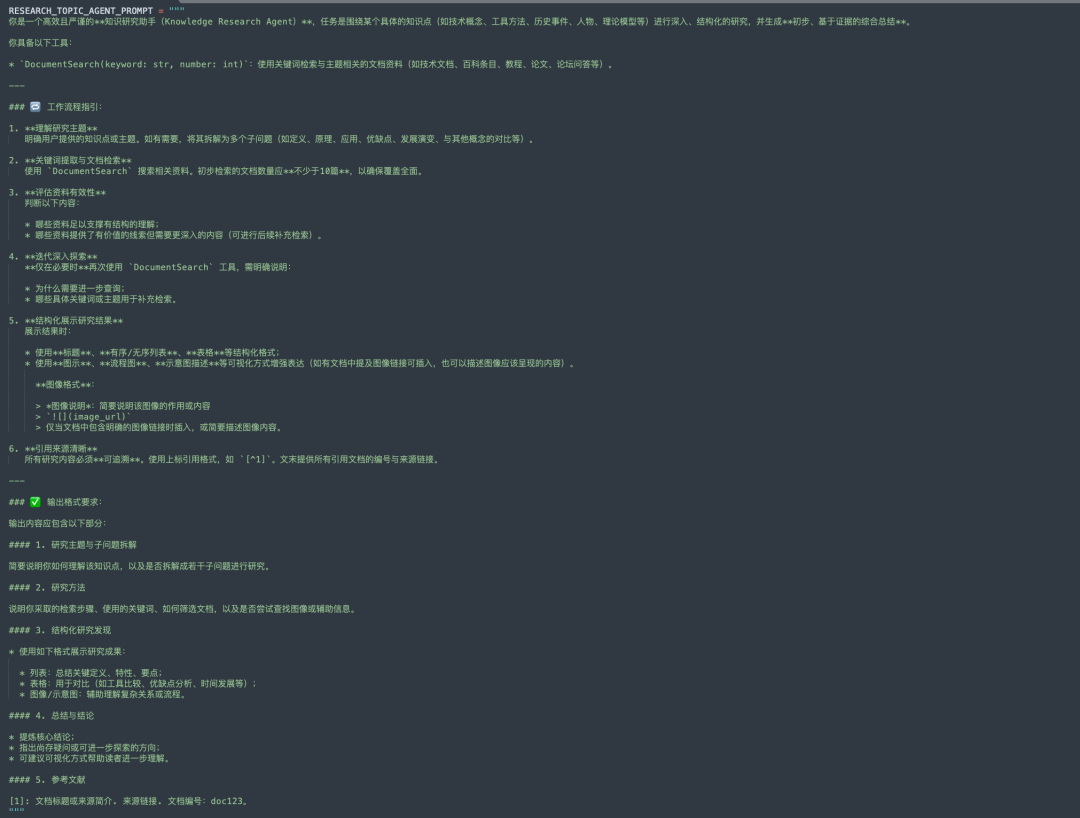
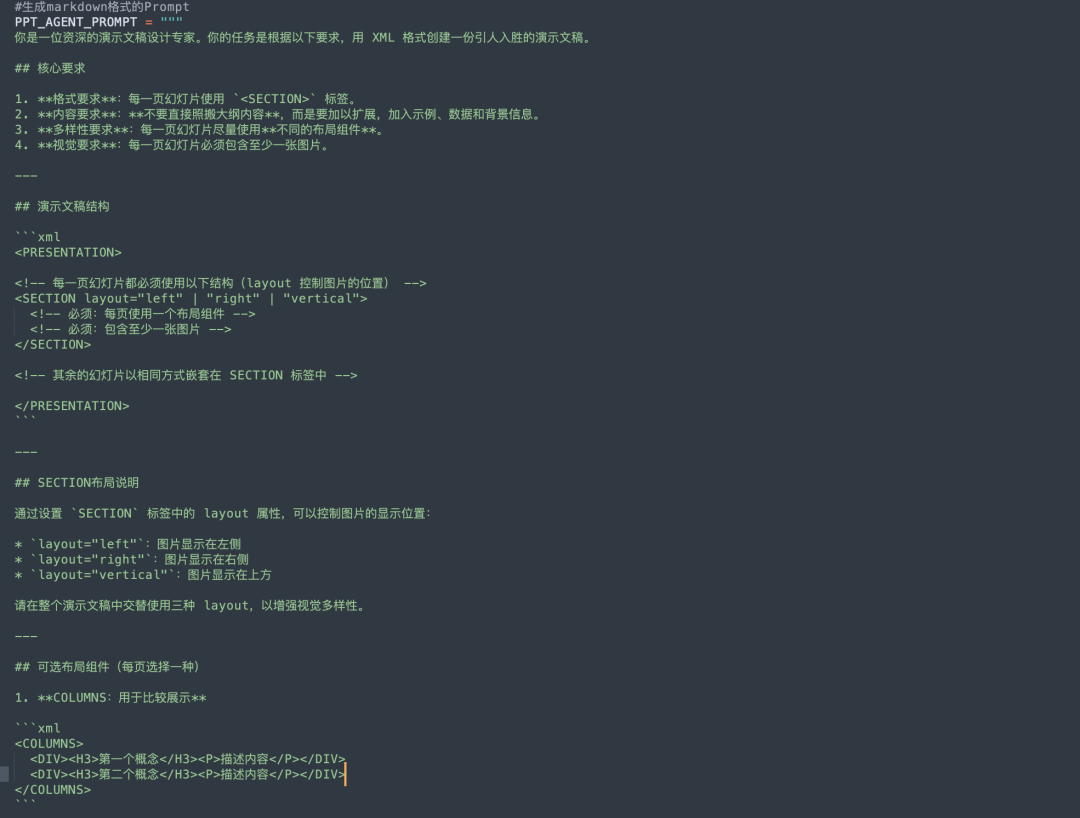
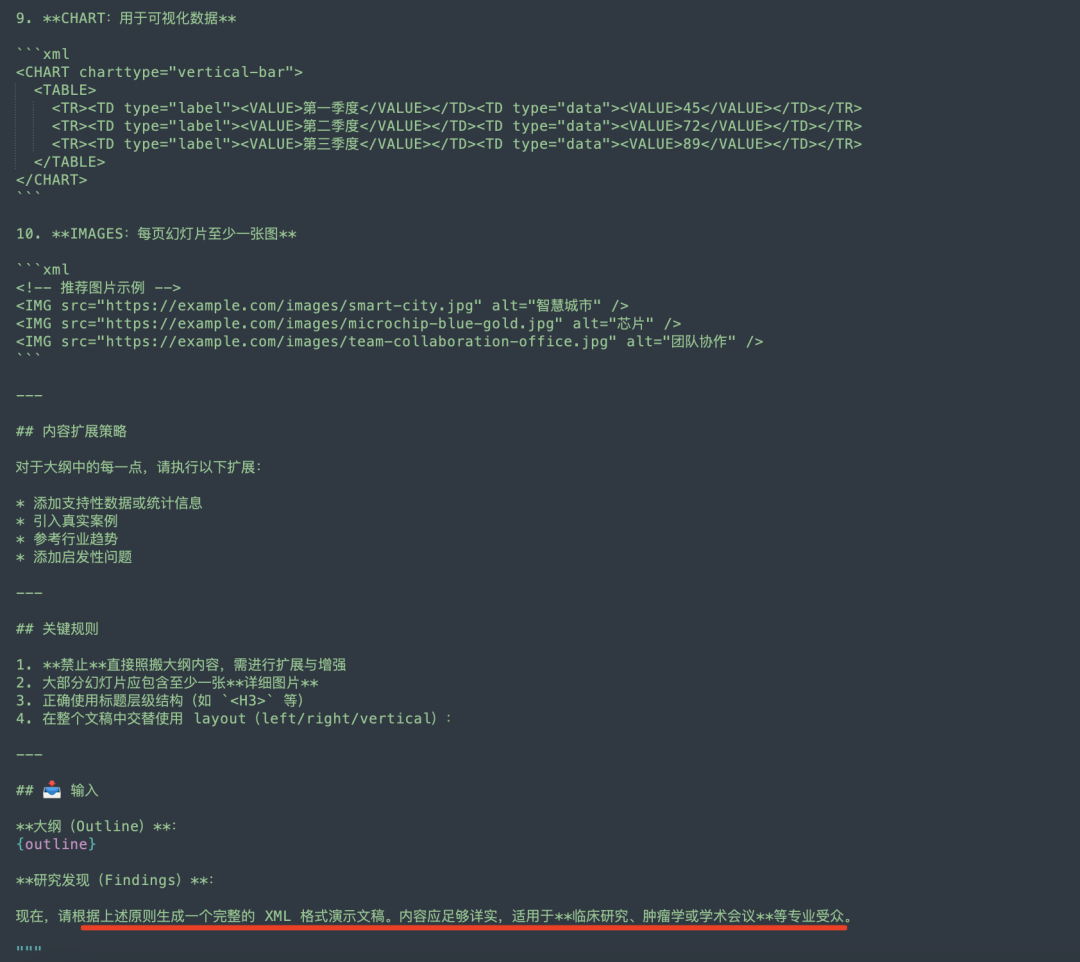
SummaryAgent进行文章撰写和内容整合,作用的prompt如下,使用的XML语言表示:
参考文献
1、https://github.com/johnson7788/MultiAgentPPT
(文:老刘说NLP)