

Datawhale分享
CV大牛:何恺明,整理:Datawhale
Datawhale分享
CV大牛:何恺明,整理:Datawhale
来源:新智元、机器之心
就在刚刚,CV大牛何恺明正式官宣入职谷歌!
已更新的个人主页上,明确写着:兼职谷歌DeepMind杰出科学家。
与此同时,他依然保留MIT EECS终身教授的身份。

个人主页:https://people.csail.mit.edu/kaiming/
这位CV领域的传奇人物,因提出ResNet而名震江湖,彻底改变了深度学习的发展轨迹,成为现代AI模型的基石。
如今,这位「学界+业界」双轨并行的跨界大神,再次用行动证明了他的无限可能!
对于谷歌DeepMind而言,何恺明的加入更是如虎添翼。
他的技术专长,涵盖了计算机视觉、深度学习等核心领域,学术影响力在全球范围内有目共睹。
Demis Hassabis曾公开表示,AGI可能在未来5-10年内实现。
何恺明的到来,无疑将助力这一终极目标的加速实现。
2003 年,何恺明以标准分 900 分获得广东省高考总分第一,被清华大学物理系基础科学班录取。在清华物理系基础科学班毕业后,他进入香港中文大学多媒体实验室攻读博士学位,师从汤晓鸥。何恺明曾于 2007 年进入微软亚洲研究院视觉计算组实习,实习导师为孙剑博士。
2011 年博士毕业后,何恺明加入微软亚洲研究院工作任研究员。2016 年,何恺明加入 Facebook 人工智能实验室,任研究科学家。2024 年,何恺明加入 MIT,成为该校一名副教授。

何恺明的研究曾数次得奖。2009 年,当时博士研究生在读的何恺明参与的论文《基于暗原色的单一图像去雾技术》拿到了国际计算机视觉顶会 CVPR 的最佳论文奖。
2016 年,何恺明凭借 ResNet 再获 CVPR 最佳论文奖,此外,他还有一篇论文进入了 CVPR 2021 最佳论文的候选。何恺明还因为 Mask R-CNN 获得过 ICCV 2017 的最佳论文(Marr Prize),同时也参与了当年最佳学生论文的研究。
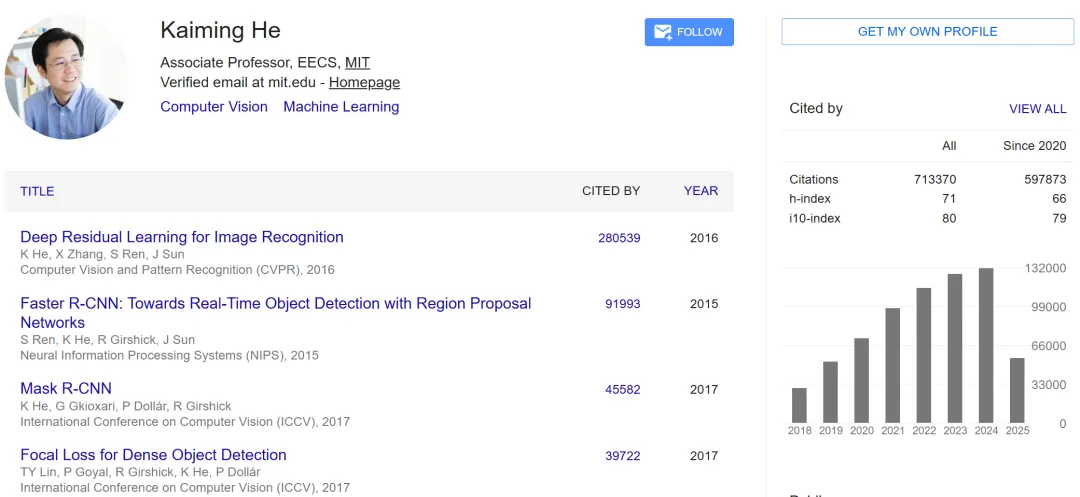
根据 Google Scholar 的统计,截至今天,何恺明的研究引用次数超过 71 万次。
此外,加入 MIT 后,何恺明开设的课程广受学生欢迎,可参考:
教授何恺明在MIT的第一堂课
教授何恺明在MIT的第二门课!
教授何恺明在MIT的最新讲座!
那些年,恺明发表过的「神作」
说起恺明大神的作品,最有名的就是 ResNet 了。这篇论文发表于 2016 年,迄今引用已经超过 28 万多。根据 《自然》 杂志的一篇文章,这是二十一世纪被引用次数最多的论文。

《Deep Residual Learning for Image Recognition》在 2016 年拿下了计算机视觉顶级会议 CVPR 的最佳论文奖。

同样是大神级别的学者李沐曾经说过,假设你在使用卷积神经网络,有一半的可能性就是在使用 ResNet 或它的变种。
何恺明有关残差网络(ResNet)的论文解决了深度网络的梯度传递问题。这篇论文是 2019 年、2020 年和 2021 年 Google Scholar Metrics 中所有研究领域被引用次数最多的论文,并建立了现代深度学习模型的基本组成部分(例如在 Transformers、AlphaGo Zero、AlphaFold 中) )。
如今大模型都在使用的 transformer 的编码器和解码器,里面都有源自 ResNet 的残差链接。
2021 年 11 月,何恺明以一作身份发表论文《Masked Autoencoders Are Scalable Vision Learners》,提出了一种泛化性能良好的计算机视觉识别模型,同样是刚刚发表就成为了计算机视觉圈的热门话题。

一个初入 AI 领域的新人,在探索的过程中看到很多重要研究主要作者都是何恺明,经常会不由得感到惊讶。何恺明虽然长期身处业界,但科研态度一直被视为标杆 —— 他每年只产出少量一作文章,但一定会是重量级的,几乎没有例外。
我们也经常赞叹于何恺明工作的风格:即使是具有开创性的论文,其内容经常也是简明易读的,他会使用最直观的方式解释自己「简单」的想法,不使用 trick,也没有不必要的证明。这或许也将成为他在教学领域独特的优势。
前段时间,何恺明还联手Yann LeCun共同发现了一种没有归一化层的Transformer,仅用9行代码就实现了。
值得一提的是,这篇研究还被CVPR 2025录用。

论文地址:https://arxiv.org/abs/2503.10622
项目地址:https://github.com/jiachenzhu/DyT
今年2月,他带队将大自然中的「分形」概念注入AI,提出了「分形生成模型」(fractal generative models)。
并且,在像素级图像生成上,团队验证了新方法的强大——
首次将逐像素建模的精细分辨率的计算效率,提升了4000倍。

论文地址:https://arxiv.org/abs/2502.17437
上个月,何恺明又联手CMU团队,提出了系统且高效的一步生成建模框架MeanFlow,无需预训练就能让AI生图一步到位。

论文地址:https://arxiv.org/abs/2505.13447
他的研究经验的创新能力,将为谷歌DeepMind未来大模型研发注入更多的可能和动力。

(文:Datawhale)