

为什么要构建一个通用型代理?因为它不仅是一个强大的原型工具,更是开启无限可能的关键一步。
通过通用代理,您可以快速搭建属于自己的智能代理架构,实现高度定制化的功能和应用场景,为解决复杂问题提供了灵活而高效的解决方案。
什么是LLM代理?


这张图展示了三种不同的基于大型语言模型(LLM)的处理方式:
-
零/少样本提示(Zero/Few-shot Prompting):直接将用户的查询输入到LLM中,LLM直接返回答案,无需复杂的逻辑流程。
-
固定LLM流程(Fixed LLM Flow,例如RAG):引入了固定的步骤,比如先通过向量检索获取相关信息(Step 1),再由LLM生成答案(Step 2)。
-
LLM智能体(LLM Agent):采用动态的工作流。LLM不仅回答问题,还能够定义并更新任务执行的步骤,循环处理直到完成最终答案的生成。
这张图逐步说明了从简单到复杂的LLM应用演进过程,体现了智能代理的灵活性与扩展性。

LLM代理与少样本提示或固定工作流程的主要区别在于其动态决策与自适应能力。在获得一组工具(如代码执行、网络搜索等)访问权限后,LLM代理能够自主决定:
- 使用哪个工具:根据用户查询选择最相关的工具。
- 如何使用工具:灵活定义操作步骤,适配不同场景。
- 迭代优化结果:通过分析输出,不断调整和改进步骤直至生成满意答案。
这种适应性让LLM代理能够以最小的配置应对多样化用例,显著提升了系统的灵活性和实用性。
第一步:选择正确的LLM。
选择合适的模型对于实现您期望的性能至关重要。需要考虑的因素包括许可、成本和语言支持等。构建一个LLM代理最重要的考虑因素是模型在编码、工具调用和推理等关键任务上的性能。评估的基准包括:

另一个关键因素是模型的上下文窗口。代理工作流程可能会消耗大量标记——有时多达10万个或更多——更大的上下文窗口非常有帮助。

通常来说,更大的模型能够提供更强的性能和更复杂的能力,但较小的模型在本地运行时也有其独特优势。使用较小模型时,尽管功能有限,但它更适合资源受限的环境。
你可能需要聚焦于更简单的用例,并将代理连接到一到两个基本工具,以保持性能的平衡和高效运行。这种方法特别适合对延迟、成本或隐私有高要求的场景。
第二步:定义代理的控制逻辑(即通信结构)。

简单LLM与智能体之间的主要区别在于系统提示。

预期的LLM代理行为可以通过系统提示进行编码,以实现具体的功能和目标。
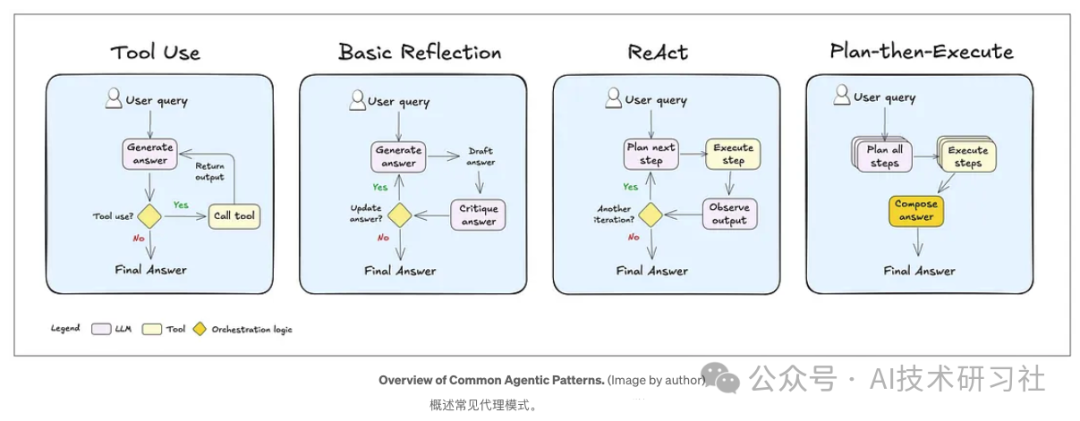
常见的代理模式可以根据需求进行定制。
工具使用是其中一种模式,代理能够判断何时将查询路由到合适的工具,或者依赖其自身的知识处理问题。
另一个模式是反思,代理在回复用户之前会审查并纠正自己的答案。这种反思步骤还可以被添加到大多数LLM系统中,提升回答的准确性。
原因-行动(ReAct)模式中,代理通过迭代推理解决问题,执行动作,观察结果,并根据需要决定是采取进一步行动还是直接提供响应。
最后,计划-执行模式让代理能够预先规划,将任务分解为子步骤(如有必要),并逐步完成每个步骤,从而实现更复杂的任务。
第三步: 定义代理的核心指令。
我们常常认为LLMs自带许多功能,但其中有些可能并不完全适合你的需求。为了实现理想的性能,关键是在系统提示中明确列出所需的功能以及不需要的功能。
这包括指令的具体设计。例如,可以定义代理的名称和角色,即它的身份以及具体任务。还可以指定语调和简洁度,决定代理是正式还是随意的风格,以及回答的简洁程度。
指令还可以明确何时使用工具,帮助代理判断何时依赖外部工具,何时依赖自身知识。对于处理错误的场景,也可以提供具体指示,明确代理在工具或流程出错时的应对策略。
通过定制这些功能,能够更好地适配具体需求,优化LLM的表现。
第四步:定义和优化您的核心工具。
工具赋予你的智能体超级能力。通过一组定义明确的工具,你可以实现广泛的功能。应包括的关键工具有代码执行、网络搜索、文件读取和数据分析。
以下是一个来自 Langchain 社区的 Arxiv 工具实现的摘录。此实现需要 ArxivAPIWrapper 的实现。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}p.p2 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'; min-height: 15.0px}class ArxivInput(BaseModel):"""Input for the Arxiv tool."""query: str = Field(description="search query to look up")class ArxivQueryRun(BaseTool): # type: ignore[override, override]"""Tool that searches the Arxiv API."""name: str = "arxiv"description: str = ("A wrapper around Arxiv.org ""Useful for when you need to answer questions about Physics, Mathematics, ""Computer Science, Quantitative Biology, Quantitative Finance, Statistics, ""Electrical Engineering, and Economics ""from scientific articles on arxiv.org. ""Input should be a search query.")api_wrapper: ArxivAPIWrapper = Field(default_factory=ArxivAPIWrapper) # type: ignore[arg-type]args_schema: Type[BaseModel] = ArxivInputdef _run(self,query: str,run_manager: Optional[CallbackManagerForToolRun] = None,) -> str:"""Use the Arxiv tool."""return self.api_wrapper.run(query)p
第 5五步:确定内存处理策略。

常见的内存处理策略包括多种方式,适应不同的对话需求和系统限制。
滑动记忆是一种方法,通过保留最后k 轮对话内容并丢弃较旧内容,确保内存容量有限时仍能处理最近的上下文。
令牌内存则专注于保留最近的n 个令牌,从而以更精细的粒度控制内存占用。
摘要记忆利用LLM在每轮对话中生成对话摘要,替代存储具体的消息。这种方式能有效减少存储负担,同时保留对话的关键内容。
此外,还可以通过LLM检测并存储关键时刻到长期记忆中,让代理能够“记住”用户的重要信息。这种个性化记忆提升了用户体验,使对话更加智能化和贴合需求。

第六步:解析代理的原始输出。

最后一步是设置编排逻辑,决定LLM生成输出后的具体操作。根据输出结果,可以采取以下两种行动:
- 执行工具调用:根据需求调用合适的工具,完成特定任务。
- 返回答案:这可以是对用户查询的最终响应,或者是向用户发出的后续请求,以获取更多信息。
通过合理设计编排逻辑,能够确保代理在每个步骤中高效执行任务并与用户保持流畅的交互。

p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}p.p2 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'; min-height: 15.0px}def orchestrator(llm_agent, llm_output, tools, user_query):"""Orchestrates the response based on LLM output and iterates if necessary.Parameters:- llm_agent (callable): The LLM agent function for processing tool outputs.- llm_output (dict): Initial output from the LLM, specifying the next action.- tools (dict): Dictionary of available tools with their execution methods.- user_query (str): The original user query.Returns:- str: The final response to the user."""while True:action = llm_output.get("action")if action == "tool_call":# Extract tool name and parameterstool_name = llm_output.get("tool_name")tool_params = llm_output.get("tool_params", {})if tool_name in tools:try:# Execute the tooltool_result = tools[tool_name](**tool_params)# Send tool output back to the LLM agent for further processingllm_output = llm_agent({"tool_output": tool_result})except Exception as e:return f"Error executing tool '{tool_name}': {str(e)}"else:return f"Error: Tool '{tool_name}' not found."elif action == "return_answer":# Return the final answer to the userreturn llm_output.get("answer", "No answer provided.")else:return "Error: Unrecognized action type from LLM output."恭喜你!现在,你已经拥有了一个能够应对各种用例的强大系统——从竞争分析和高级研究,到自动化复杂工作流程,通通不在话下!无论是提升工作效率,还是解锁更多创新机会,这个系统都能为你带来前所未有的助力。你准备好开始探索它的无限潜力了吗?在实现目标的过程中,你最期待的是什么呢?欢迎在评论区分享你的想法和体验,让我们一起讨论如何更好地利用这一强大工具!
(文:AI技术研习社)