

大家好我是歸藏(guizang),今天给大家带来 Midjourney 视频模型的测试。
昨天晚上 Midjourney 在测试了几次后终于发布了自己的第一个视频模型 Video V1。
先来看一下藏师傅的测试视频混剪,我起了个名字叫《精骛八极,心游万仞》,来自陆机的《文赋》。
后面我会解释为什么叫这个,以及在文章最后我会跟你说为什么我觉得这个“480P”的视频模型这么重要。
这次视频模型测试,由于 Midjouney 这家公司本身的特殊性,我不会只说视频模型的部分,会结合产品能力上的更新一起讨论。
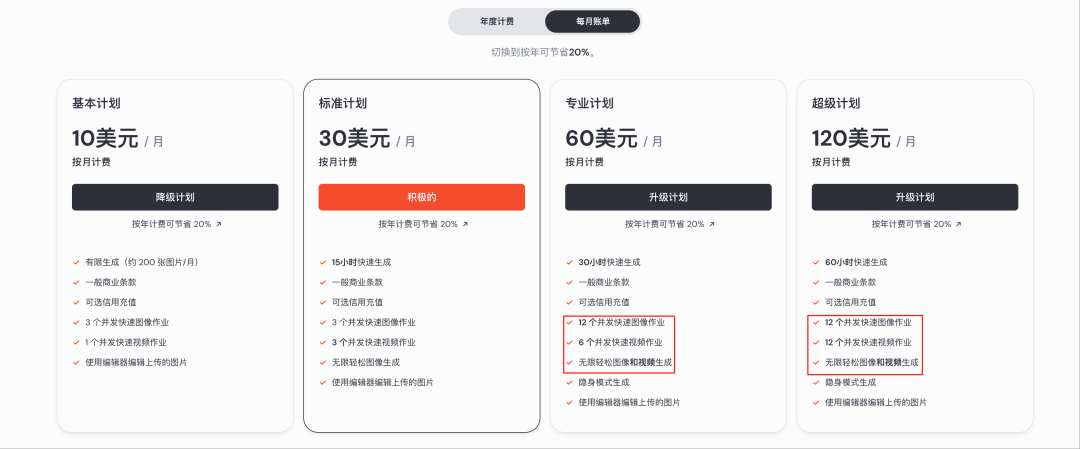
首先我们先看一下产品和定价方面的内容。
跟其他视频生成软件和模型设计不同,Midjourney 干脆不支持文生视频,只能通过图生生成。
而且视频生成也没有单独的入口,你只需要在自己生成的图片上面点击“Animate”按钮就会开始基于这张图片生成视频,不需要输入提示词。
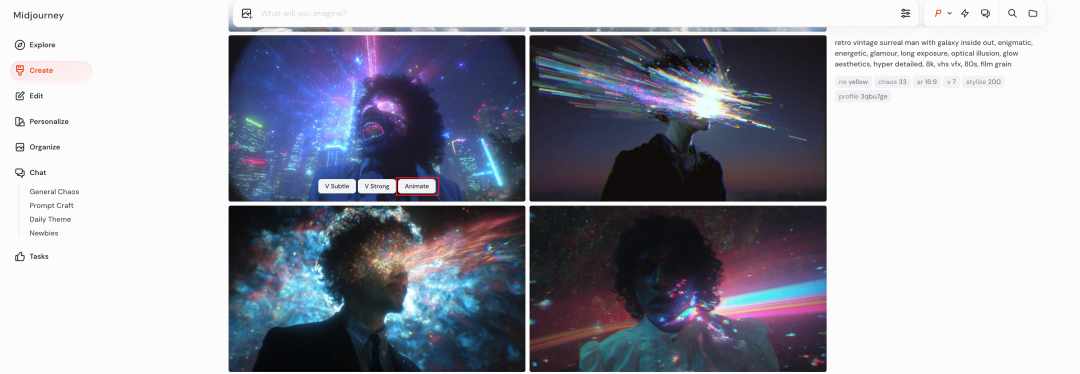
跟图片一样一次会生成 4 个视频,鼠标 Hover 对应的视频会有两个按钮,一个是自动延长视频,另一个是自定义提示词的延长视频。
每次延长的时间是 4 秒,最多支持延长四次,也就是说你最多可以生成 20 秒连续的视频。
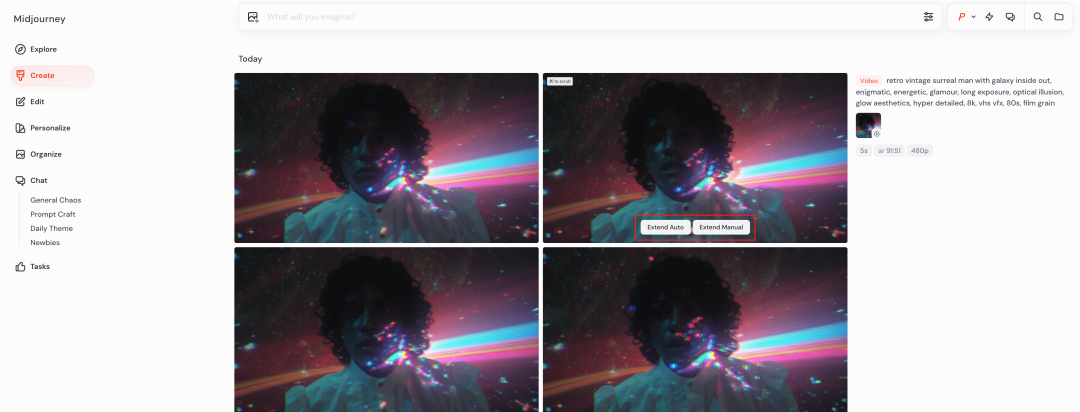
在延长视频和生成的时候有两个选项第一个是低动态幅度,另一个是高动态幅度。
低动态模式更适合环境氛围场景,此时摄像机基本保持静止,被摄对象以缓慢或刻意的方式移动。
高动态模式最适用于需要所有元素(包括被摄主体和摄像机)都动起来的场景。

V1 生成的视频只有 480P 一个分辨率,但是不要把他当做你认为的 480P,整个采样率相当高,甚至比一些 720P 的视频模型看着清晰。
而且他的长边超过了 720P,在一些视频模型可能就已经被叫做720P 了,他们太实诚了。
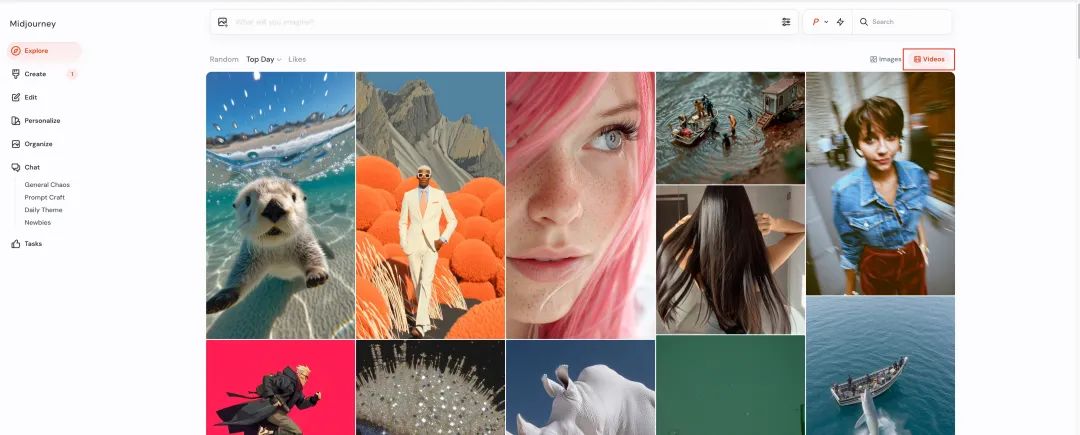
Midjourney 最重要的部分探索页面现在也支持展示大家生成的视频。
视频和图像一样除非你买 60 美元的会员否则也是默认公开的。
可惜的是喜欢列表的视频和图片是混合展示的,本来就不好找的收藏现在估计更不好找了。
最后就是定价了,Midjourney 视频模型的使用不需要单独付费,你只要是会员就可以使用。
跟图像一样也是扣快速生成的时间,另外 V1 的生成成本极低,基本消耗的金额跟超分图片差不多。
如果你购买了 60 美元计划的话,更是有无限的慢速生成额度,相当划算了。
然后来看一下模型本身的生成结果。
Midjourney Video 第一个长处是美学表现相当顶级,这是 Midjourney 的看家本领,在色彩表现、氛围营造上无可挑剔,可以看下面两个片段。
然后是高风格化视频的表现,图像和视频的风格是非常多的,不只是所谓的写实和动漫,尤其是MJ 生成的图片。
大部分视频模型在图生的时候碰见一些不常见的风格图片在视频经过一两秒之后都会被掰成模型擅长的风格。
得益于MJ 本身的图片数据,导致 V1 模型在处理罕见的高风格化视频的时候非常稳,色彩、笔触、氛围都能保持得住。
而且即使是运动中新出现的部分也可以维持住原有的风格,比如下面这里的剑身反光。
另外他们的生成速度也非常快,我自己开秒表试了一下,一次生成 4 个视频只需要 65 秒的时间。
这在现在 1080P 动辄十几二十分钟的生成时间上可以说是清流了,普通用户完全没办法等这么长时间。
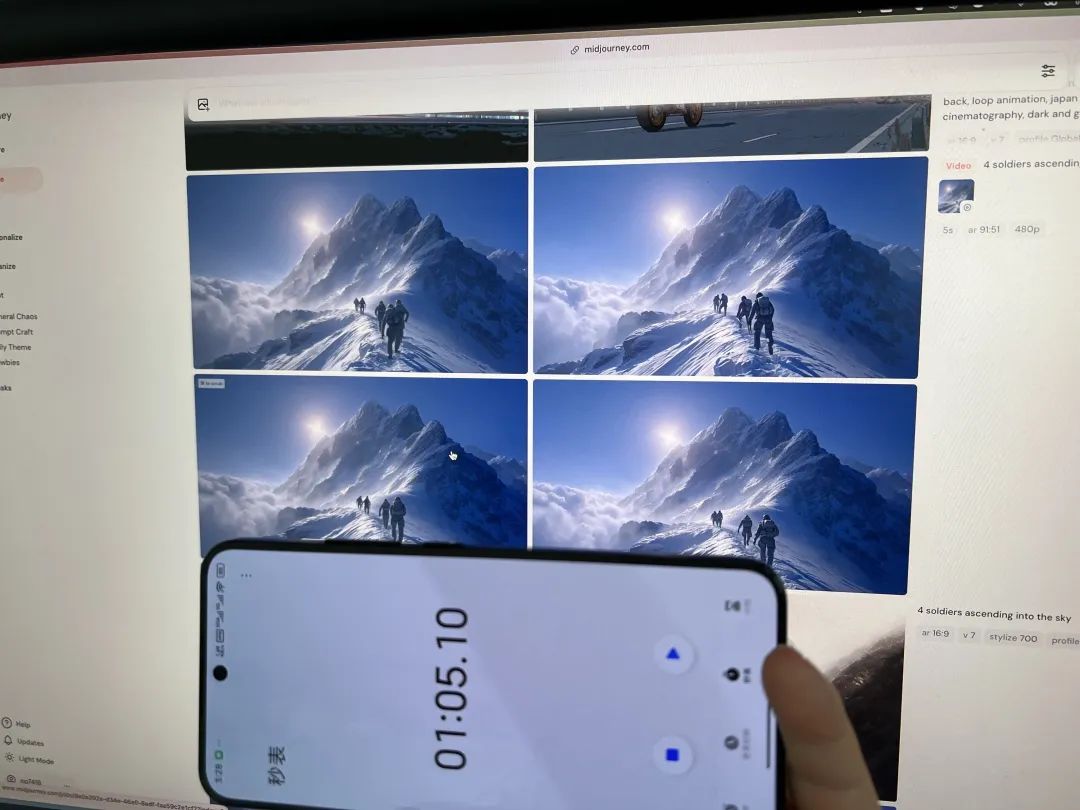
视频延长的稳定性也很好,基本上延长最后一次到第 17 秒的时候,视频依然没有崩溃,即使是复杂场景,这个在其他模型上是很难见到的。
下面第一个视频延长了 4 次,第二个视频延长了一次。
说完了好的再说不行的。在现在视频模型经常考核的,提示词理解、复杂运动稳定性和物理特性上,基本处于二流模型水平。
与现在第一梯队的hailuo2、Kling 2.1、Seeddance 1.0 Pro、Veo 3 没法比,而且这些大部分默认分辨率都已经是 1080P 了,他还 480P。
比如下面第一个案例这里女生虚空穿过了车门上车这种物理问题,第二个案例脖子的肢体异常在高运动模式下会经常出现。
看到这里你肯定也像大部分人认为的一样,觉得 Midjourney 视频模型这也太拉了,怎么跟其他模型竞争。
我不这么认为。
我觉得 Midjourney 很清楚他们模型的问题也清楚现在的视频模型竞争格局,但他们选择不去管这些,选择不去跟其他视频模型设定好的框架竞争。
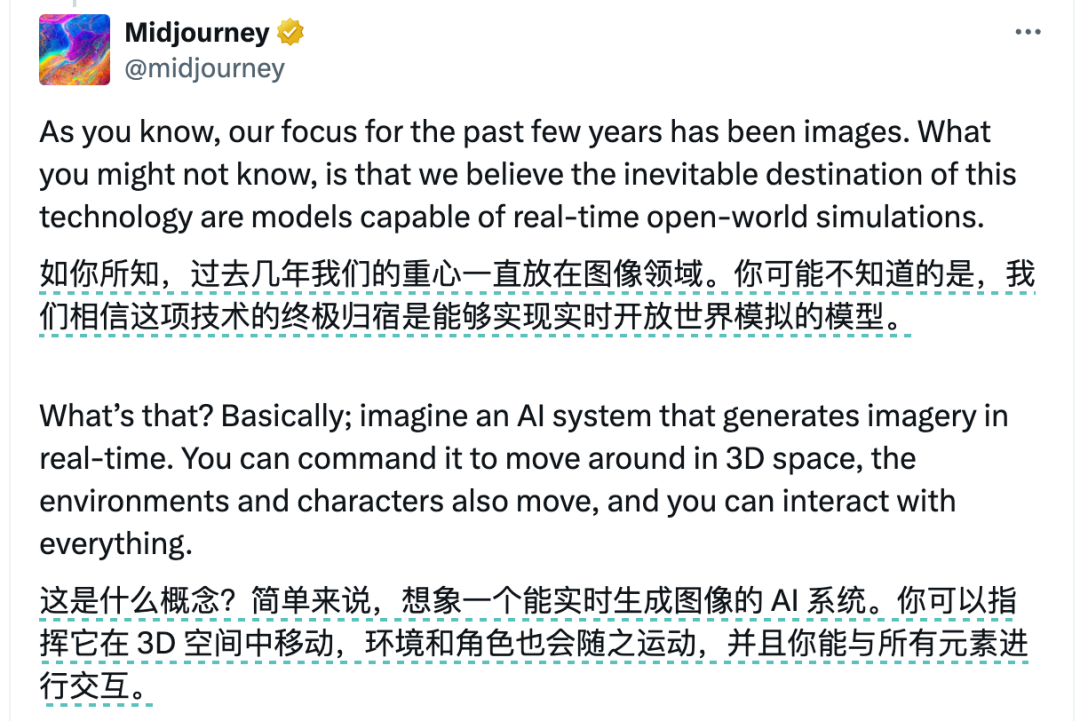
在发布 V1 视频模型的时候他们重申了一下自己的愿景,他们长期目标是构建一个实时图像生成的 AI 系统。
你可以进入到图像所在的时间进行移动和游览,图像中的其他角色和环境也会随着你的移动变化,你可以跟所有的元素交互。实现这个方案需要四个部分:
- 视觉呈现,也就是现在 MJ 的图片模型
- 然后要让图像动起来,就是现在发布的 V1 视频模型
- 之后如果需要跟环境交互的话需要赋予内容实体,一个 3D 模型
- 最后生成速度要跟的上你的移动速度,也就是实时生成模型
看到这里你也许就能理解为什么他们不在乎现在其他视频模型在乎的那些东西,他们唯二在技术上在意和下功夫的地方就是两个,生成速度和长时间一致性。
这两个是实现他们愿景中视频模型负责的最关键的部分,物理的部分会交由 3D 模型完成。
可能有人说之前 Runway 也说过类似的话,但他们现在没声音了。
这个就要说到 Midjourney 的另一个优势了,他们没有融资压力,完全是自给自足,所以与需要频繁融资续命的公司不同,他们可以慢下来,可以与主流不同。
其实这个愿景实现之后的场景现在已经可以一窥究竟了,你可以去 Midjourney 的视频探索页面看看。
昨晚模型发布之后我刷了这个页面一个小时,困的不行了才恋恋不舍的去睡觉。
他们好像展示在我面前的真是一个个的异次元世界入口,每个世界的画面风格和物产都不同。
看着这些视频的时候我会不自觉的开始想想每个画面后的世界跟我产生的故事。
现在是不是知道为啥我要给模型测试视频起这个《精骛八极,心游万仞》的名字了。
这句话是陆机描述在进行艺术构思、艺术创作时需要做到的事情,思想纵横驰骋而不受时空的限制,就像骏马驰骋于天地四方,又像心灵畅游于万仞天空,是不是很像 Midjourney 的愿景。
看到这里,我想很多AI领域的朋友可能会重新思考一个问题:在这场AI视频模型的军备竞赛中,什么才是真正重要的?
当所有人都在追逐1080P、4K分辨率,追求物理准确性和提示词理解精度时,Midjourney选择了一条看似”落后”的道路。
Midjourney提醒我们:真正的创新往往来自于重新定义问题本身。当别人在问”如何生成更真实的视频”时,他们在问”如何让人类的想象力具象化并可交互”。
“精骛八极,心游万仞”——这不仅是对Midjourney愿景的诠释,也应该是我们每一个AI探索者的追求。在技术的汪洋中,我们需要的不只是更快的船,更需要知道自己要航向何方。
也许多年后回望,我们可能会发现,2025年Midjourney发布的这个”只有480P”的视频模型,其实是通向未来元宇宙的第一扇门。
(文:归藏的AI工具箱)