跳至内容
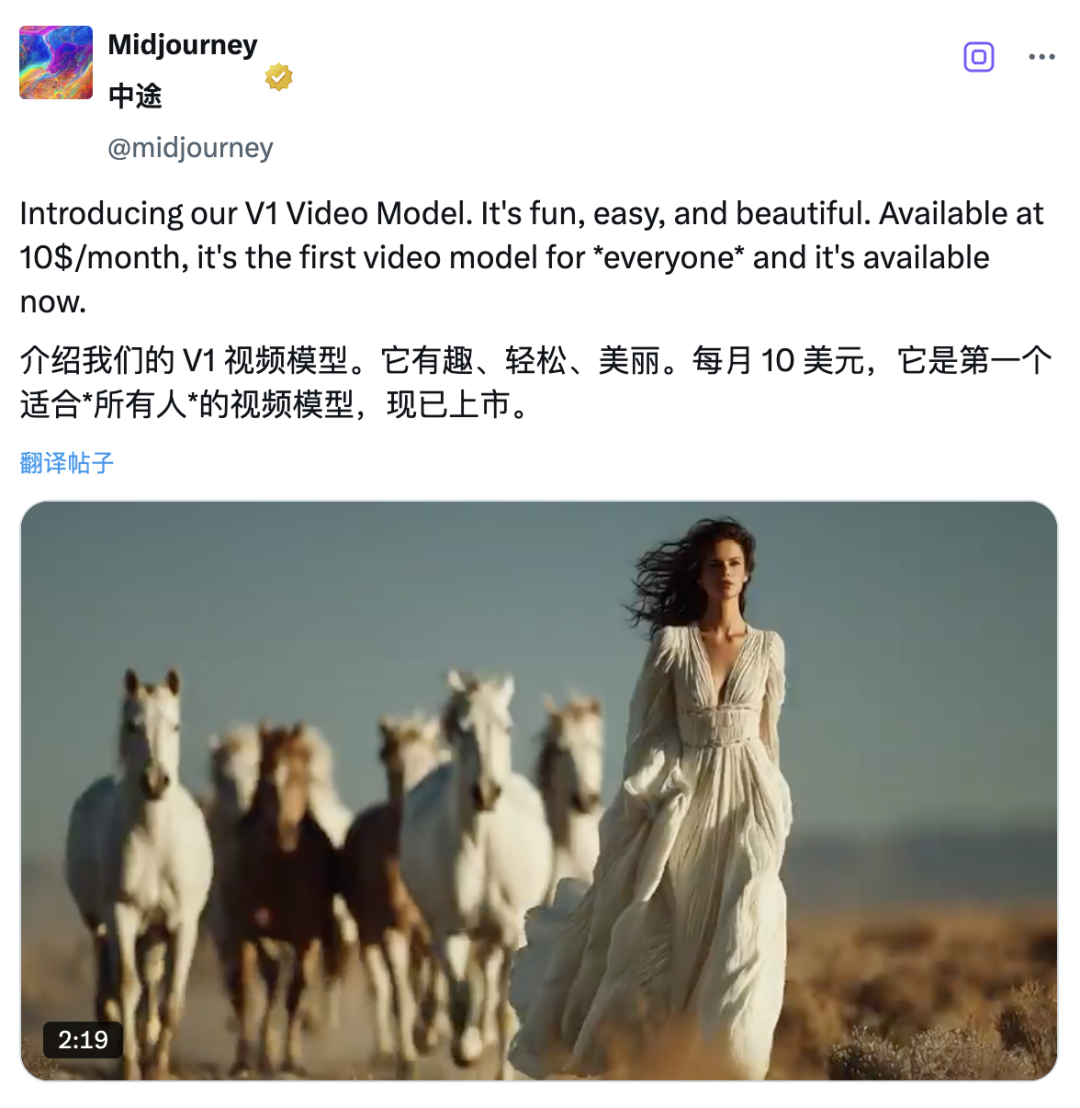
面对迪士尼和环球影业的版权诉讼,老牌文生图「独角兽」Midjourney 没有放慢节奏,反而于今天凌晨顶着压力推出了首个视频模型 V1。
不卷分辨率、不卷长镜头、Midjourney 卷的,是一股独有的氛围感和审美辨识度。Midjourney 是有野心的,目标剑指「世界模型」,但目前略显「粗糙」的功能设计,能否让其走得更远,恐怕还是一个未知数。
上传或生成图像后点击「Animate」即可,单次任务默认输出 4 段 5 秒视频,最长可扩展至 21 秒
支持手动和自动两种模式,用户可通过提示词设定画面生成效果;提供低运动和高运动选项,分别适合静态氛围或强动态场景
视频功能包含在现有订阅中(10 美元/月),GPU 资源消耗为图像任务的 8 倍
不支持添加音效、时间轴编辑、片段过渡或 API 接入,分辨率仅为 480p,长宽比自动适配图像,仍属早期版本
视频模型是阶段成果,未来将继续推出 3D 模型与实时系统,最终剑指世界模型
开卷氛围感,Midjourney 视频模型正式上线
Midjourney 一直以奇幻、超现实的视觉风格见长,而从目前用户实测的效果来看,其视频模型也延续了这一美学方向,风格稳定,辨识度高。
在 @EccentrismArt 博主分享的视频中,一个少年少年从高空垂直坠落。人物造型简洁,动态感强,像是跳跃、坠落或在梦境中自由落体,运动路径流畅,人物重心相对自然。
城市街区密集、灯光密布,建筑仿佛在空间中倾斜、旋转,形成一种空间扭曲的视觉错觉,但整体建筑动态无明显抖动或 AI 生成拼接断层。
在这段日式电车站场景视频中,电车离站,太阳将落未落,色温控制到位,光源自然,营造出一种静中带动、动中藏静的节奏。
Prompt: The train passing through the station. | @PJaccetturo
一位身穿衬衫、手抱文件或书本的女性剪影,在她背后,是一幅巨大的人类头部侧影,可以看到,多重曝光/层叠构图处理得非常干净,光晕勾边自然,没有过曝。也难怪 Perplexity AI 设计师 Phi Hoang 直呼画面超出预期。
知名 X 博主 @nickfloats 分享了一个女生走在一个光线明亮的火车站台上的视频,背景中有一列高速驶过的火车,光影分区明显,立体感强。
夜晚、极光、雪地、车灯、运动模糊等要素并存,对视频生成模型提出了极高挑战。但模型成功处理多重光源干扰;雪地粒子、车速模糊、轨迹光效一致性强。
Prompt:2022 World Rally blue Subaru, racing through snowy Finland at night, dramatic action shot, dynamic motion blur, snow flying, Northern lights in the sky, headlights illuminating the snow, high contrast, cinematic lighting | @JamianGerard
身穿经典的太空服,航天员身后延伸出大量彩色的光线轨迹,呈现出一种「穿越」或「高速运动」的错觉,视觉节奏感强。
Prompt:「Live a little, dropping acid, and I’m flying away I’m feeling like an astronaut in space I don’t think that it’ll do the damage they say Feeling like an astronaut in space」 | @JamianGerard
高光、材质、液体运动等要素都是检测 AI 模型对静物表现力的重要试金石,而这则视频中,奶油动态自然,杯体旋转过程中标签未发生明显扭曲。
Prompt:A Starbucks drink, classic tall cup, iced caramel macchiato, swirling caramel drizzle, whipped cream on top, condensation on the cup, vibrant and appetizing, high-quality beverage photography, 1:1 aspect ratio. | @JamianGerard
写实风格表现中规中矩,孩童左手多出来的部分看着就有些不太协调。
Prompt:Sitting in the middle of the jungle with lots of wild animals moving around S | @JamianGerard
在末日感拉满的纽约街头,火光、残垣断壁等细节充足,根据提示词的要求,生成的视频需要以 35mm 胶片质感推进,整体来看也略带颗粒感。
Prompt:A city street in the early morning, with burning cars and debris scattered everywhere. The scene evokes 1990s New York, captured in the style of photographer Jeff Wall, with the grainy texture of 35mm film. | @JamianGerard
水晶球悬停缓旋,考验场景稳定性,好在摄像机运动也相当平稳。
Prompt:crystalline sphere hovering and spinning slowly above a calm colorful field, steady cam shot | @JamianGerard
值得注意的是,以上展示的案例生成结果可能经过多轮「抽卡」,但就最终效果来看,视觉完成度已经相当可观。
有野心的 Midjourney,正在搭建「世界模型」的第二块积木
从今天起,Midjourney 用户可以在官网(Midjourney.com)上传图像,或直接使用平台生成的图像,点击「Animate」按钮,即可将图像转为视频。
每次任务会生成 4 段 5 秒的视频,用户可对任意一段进行最多 4 次扩展,每次增加 4 秒,总时长最多 21 秒。当然,万步开头难,官方表示未来将在时长和功能方面进一步扩展。
操作逻辑门槛其实并不高,你可以像往常一样在 Midjourney 创建图像,只是现在多了一个画面动起来的步骤,此外,你还可以上传外部图片作为「起始帧」,再通过提示词描述希望呈现的动态效果。
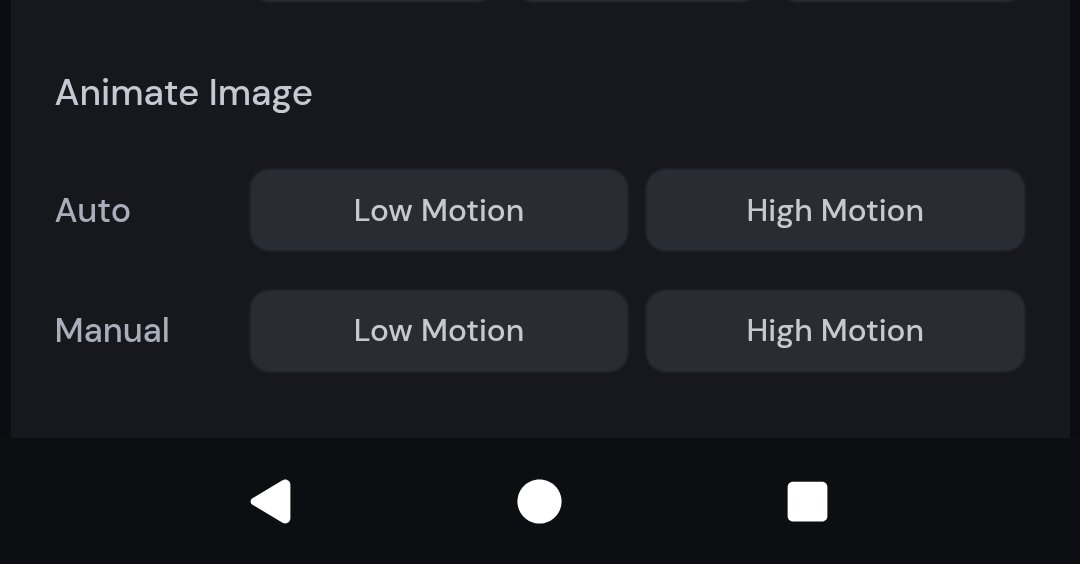
V1 提供了一些可调节的自定义设置,便于用户对画面内容做出更细致的控制。
在「手动模式」(Manual)下,你可以输入具体提示词,自动设定视频中元素的移动方式和场景,但如果你暂时对提示词没有头绪,可以选择「自动模式」(Auto),它会为你自动生成运动提示词,并让图像动起来。
低运动模式(Low motion):适合大多保持静止的镜头,如人物眨眼、微风吹动景物等氛围感场景,缺点是,有时效果并不明显;
高运动模式(High motion):适合需要镜头和主体都大量移动的场景,但缺点是,强烈的运动有时可能会导致画面错误或不稳定;
价格方面,视频功能被直接纳入 Midjourney 的订阅体系,起价依旧是每月 10 美元。
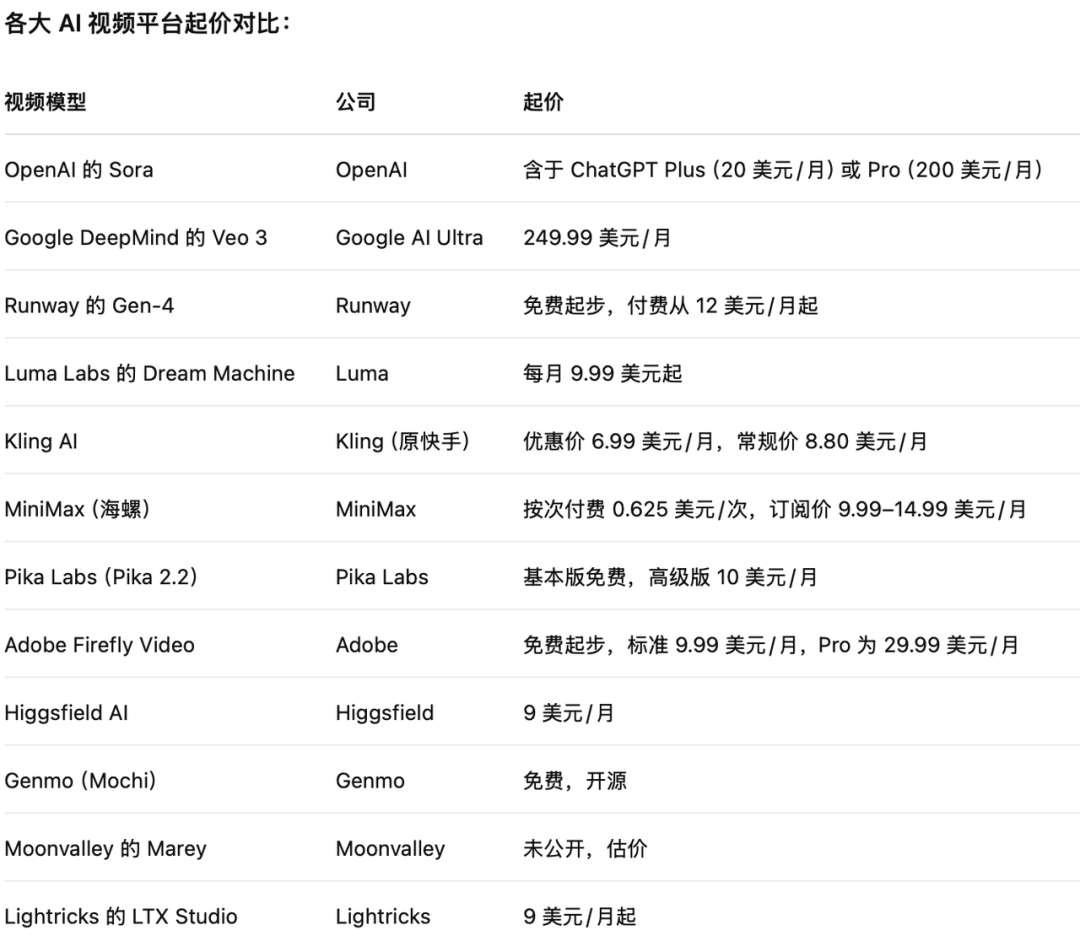
根据官方博客的说法,Midjourney 每段视频的 GPU 耗时约为图像任务的 8 倍,但在生成长视频的情况下,平均每秒的成本几乎与图像生成持平。相较竞品,性价比可以排进第一梯队。
我们也用 AI 搜索引擎简单梳理了一些主流视频模型的订阅费用,供大家参考👇
另外,Midjourney 正在面向 Pro 及以上等级的订阅者测试「Relax Mode」模式,该模式将会以较慢的速度完成生成任务,从而降低对算力资源的消耗。至于其他等级的用户,依然按照 GPU 时间和会员等级计费。
目前来看,Midjourney 视频模型存在不少值得吐槽的点,最典型的特征就是缺乏一些面向专业创作的关键能力。
首先,Midjourney 视频模型只能生成「哑剧」,暂不支持自动添加背景音乐或环境音效。若需音频,仍需使用其他第三方工具手动添加。
其次,Midjourney 视频模型不支持编辑时间轴、生成的视频片段之间是「跳切」的,无法做到故事连续、画面自然衔接,也就很难控制剧情节奏或情绪铺垫。
再者,Midjourney 视频模型暂时也不提供 API。
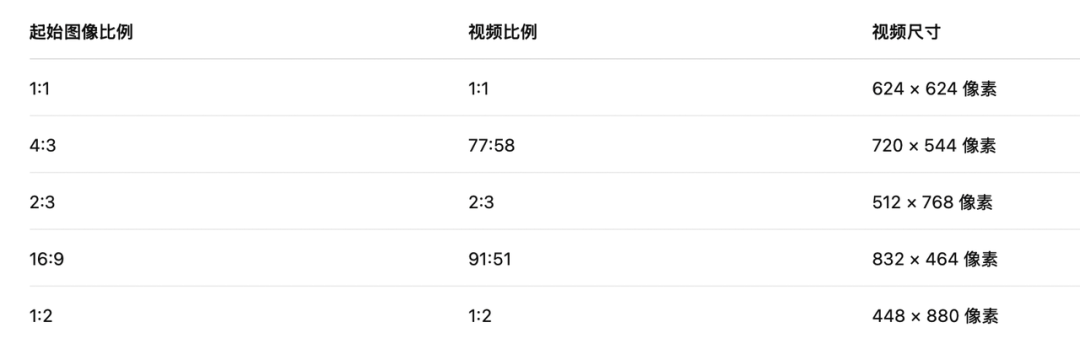
更重要的是,Midjourney 默认输出 24fps、480p 的视频,视频长宽比会自动适配图像原尺寸,上传至其他平台时也会标注为 480p。
注:Midjourney 可能会对长宽比稍作调整,最终输出视频的比例可能与起始图像略有不同。
Midjourney 官方也坦言,当前版本仍属早期探索阶段,重在可访问、易上手、可扩展。
视频模型只是切口,Midjourney 想要的,是更完整的内容生产体系。
其最终目标是构建一个「世界模型」,也就是将图像生成、动画控制、三维空间导航和实时渲染整合为一体。
你可以理解为,在一个能够实时生成画面的 AI 系统中,输入一句话,可以命令 AI 主角在 3D 空间中移动,环境场景也会随之变化,而且你可以与一切进行互动。
如同搭积木,要实现这个目标,就需要图像模型(生成静态画面)→视频模型(让画面动起来)→ 3D 模型(实现空间导航与镜头运动)→ 实时模型(保证每一帧都能同步响应)。
按照 Midjourney 的产品规划,这四块技术「积木」将陆续交付,最终整合成一个统一的系统。而作为阶段性成果的 V1 视频模型,是这个终极目标的第二步。
欢迎加入 APPSO AI 社群,一起畅聊 AI 产品,获取#AI有用功,解锁更多 AI 新知👇
✉️ 邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
(文:APPSO)