



今天给大家带来北京大学彭宇新团队教授的最新工作,一种训练无关的动态聚焦视觉搜索方法,论文已被 CVPR 2025 接收为 Highlight(前 13.5%)并完全开源。
论文标题:
DyFo: A Training-Free Dynamic Focus Visual Search for Enhancing LMMs in Fine-Grained Visual Understanding
论文链接:
https://arxiv.org/abs/2504.14920
开源代码:
https://github.com/PKU-ICST-MIPL/DyFo_CVPR2025
实验室网站:
https://www.wict.pku.edu.cn/mipl

摘要
随着 OpenAI O3 等模型实现“图像思考(thinking with images)”能力,多模态大模型(LMMs)正加速迈向更深层次的视觉推理。
然而,当前开源主流 LMMs 仍采用“看图回答”的范式,在处理高分辨率图像、复杂场景或仅涉及图像局部的细粒度理解任务时,容易产生幻觉、被大量无关视觉输入干扰,难以满足实际应用需求。
为此,本文提出 DyFo(Dynamic Focus),一种训练无关、即插即用的动态聚焦视觉搜索方法。
DyFo 模拟人类视觉搜索行为,结合蒙特卡洛树搜索(MCTS),在多模态大模型与视觉专家模型间实现高效协作,逐步聚焦关键区域,有效过滤无关信息,提升细粒度理解能力。
DyFo 具备良好兼容性,可直接增强任意 LMMs,无需模型改动或额外训练,且采用异步推理架构,支持自定义推理策略的高效执行和验证。
在 POPE(幻觉检测)与 V* Bench(细粒度理解)等基准上,DyFo 实现了稳健性能提升,作为“图像思考”理念的实用补充,为多模态模型在高复杂度视觉任务中的落地提供了新路径。

背景与动机
多模态大模型(LMMs)近年来在通用视觉理解任务中取得了长足进展。2025 年 4 月,OpenAI 发布了 O3 模型,在“图像思考(thinking with images)”方面实现重要突破:模型能够在推理链中主动处理图像内容,并借助图像缩放、裁剪等操作完成更深入的视觉推理。
这标志着多模态推理正从“看图回答”迈向“基于图像思考”的新阶段。然而现有开源主流多模态模型仍主要采取“看图回答”方式,并面临两类实际问题:
1. 固定分辨率模型(如 LLaVA-1.5)难以处理超高分辨率图像或密集信息区域;
2. 动态分辨率模型(如 Qwen2-VL)容易受到图像中无关内容的干扰,难以精确聚焦用户关注区域。
现有方法尝试通过引入额外模块或监督信号(如 SEAL 的显著性建模)提升聚焦能力,但往往依赖额外训练,缺乏通用性,且性能仍受限于基础模型本身的表征能力。
为此,我们提出了 DyFo(Dynamic Focus),一种训练无关的动态聚焦视觉搜索方法。
DyFo 模拟人类视觉搜索策略,基于蒙特卡洛树搜索(MCTS)在多模态大模型与视觉专家之间实现高效协作,引导模型在多轮交互中动态调整关注区域,从而更准确地理解图像中的关键细节,显著提升模型在细粒度视觉任务中的表现。
与 OpenAI O3 所代表的前沿视觉推理思路相呼应,DyFo 同样强调“逐步思考”的重要性,但区别在于:
-
DyFo 无需额外训练,可直接接入任意现有 LMMs,带来性能增强;
-
完整开源,具备异步推理架构,支持推理策略灵活扩展和高效执行;
-
在 POPE(幻觉测试基准)和 V* Bench(细粒度视觉理解)上验证可获得稳定性能增强。
我们相信,DyFo 的提出为“思考图像”这一理念提供了一种更具实用性的路径补充,有望拓展多模态模型在更高分辨率、更高复杂度任务下的适用范围,推动通用 LMMs 在细粒度理解方向的能力边界。

技术方案
DyFo 框架由两个核心组件构成:聚焦调节器(Focus Adjuster)和聚焦树搜索(Focus Tree Search)。
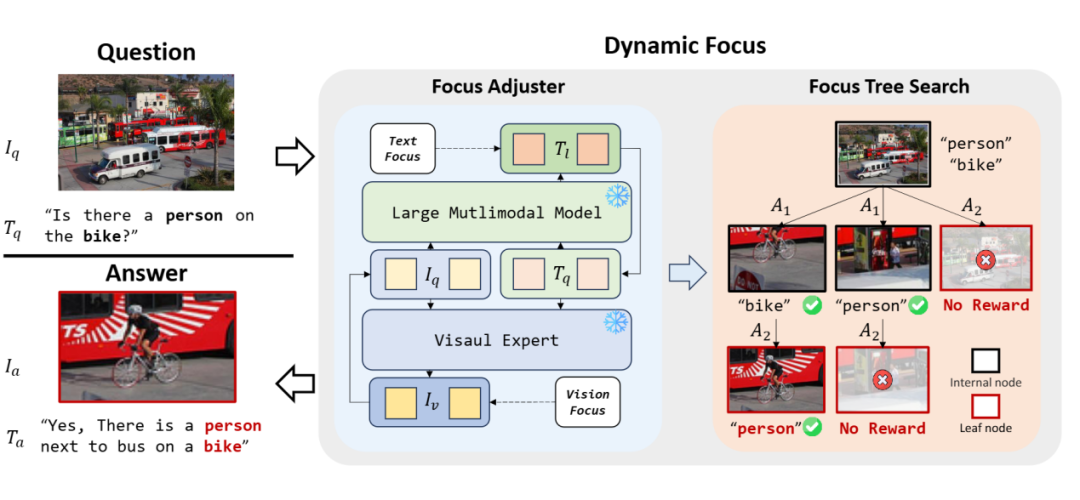
▲ 图1. DyFo 框架主要包括聚焦调节器和聚焦树搜索两大模块
3.1 聚焦调节器(Focus Adjuster)
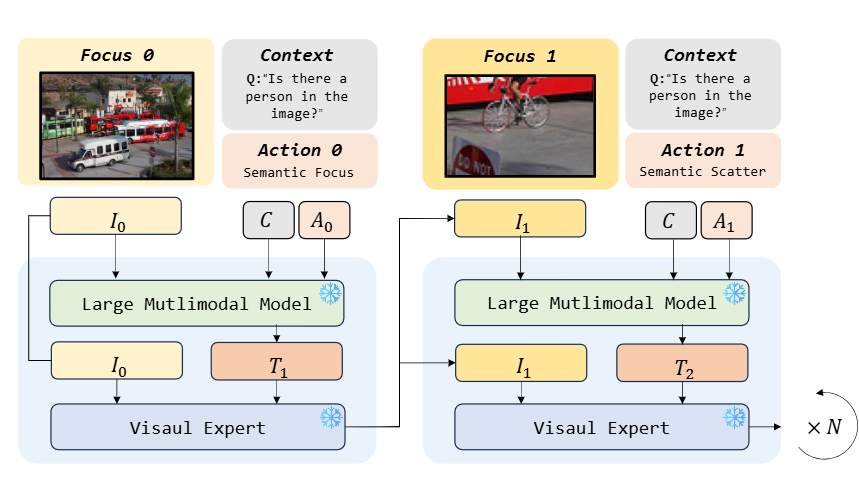
▲ 图2. 聚焦调节器执行过程
聚焦调节器是一种协同机制,融合了 LMM 的多模态语义理解能力与视觉专家模型的精细感知能力。
我们设计了具有可解释性的动作空间(Action Space),用于模拟人类视觉聚焦行为,指导 LMM 与视觉专家高效互动,动态调整关注区域。
具体包括以下两类核心动作:
-
语义聚焦(Semantic Focus):该动作基于当前对语义内容的理解(如问题相关目标、上下文关键词等),引导视觉专家在图像中定位最具语义关联的区域,模拟人类视觉中的联合搜索与内源性注意机制。
-
语义发散(Semantic Scatter):该动作扩展当前关注区域的范围,防止因过度聚焦而遗漏关键信息,模拟人眼聚焦过程中的发散行为,提高模型对潜在目标的全局感知能力。
在执行过程中:
-
LMM 根据当前聚焦区域的语义上下文提供文本线索;
-
视觉专家依据线索对图像进行精确感知与定位;
-
双方通过动作序列迭代执行,实现动态、可控的聚焦路径优化。
该机制显著提升了模型在细粒度视觉搜索中的性能,使其能够在复杂图像场景中有效识别和聚焦语义关键区域。
3.2 聚焦树搜索(Focus Tree Search)
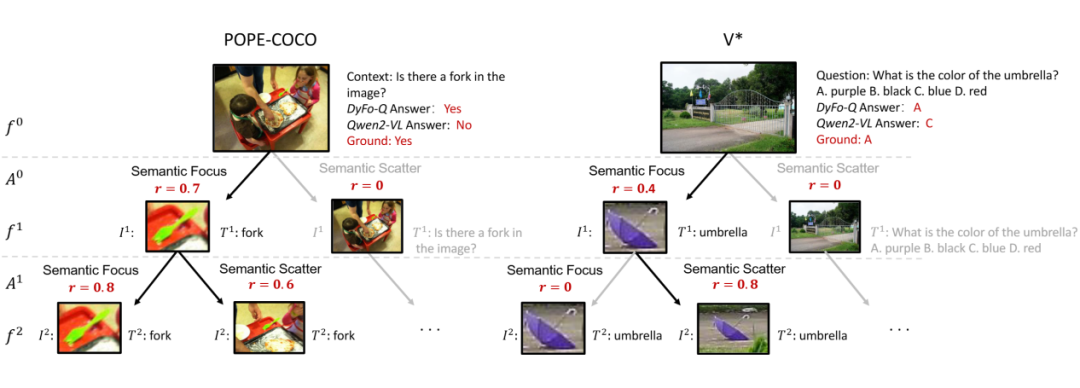
▲ 图3. 聚焦树搜索过程
聚焦树搜索采用蒙特卡洛树搜索(MCTS)算法,通过构建聚焦树来高效导航视觉空间。每个节点代表一个聚焦状态,每条边对应一个聚焦转换动作。该算法通过三个关键阶段实现高效搜索:
1. 选择阶段:平衡探索与利用,选择最有潜力的聚焦节点(图-文对);
2. 扩展阶段:在叶节点选择动作生成新的子节点,扩展搜索空间;
3. 反向传播阶段:更新节点价值,优化搜索策略。
为了模拟人类视觉行为,DyFo 设计了一个动作空间,包括语义聚焦和语义扩散等操作,使模型能够像人类一样灵活调整注意力焦点。
与现有大量的依赖 LMMs 基于文本的推理方法不同,DyFo 的动作设计模拟人类视觉行为而非纯粹的语义推理,提供了更自然、更有效的视觉搜索体验。
最后,DyFo 采用多节点投票机制整合搜索树中的信息,确保模型既能捕捉关键细节,又不会过度关注局部而忽略全局信息。

实验结果
研究团队在多个权威基准测试上评估了 DyFo 的性能,包括 POPE(基于对象探测的幻觉评估)和 V* Bench(细粒度视觉语言理解)。
4.1 POPE基准测试结果
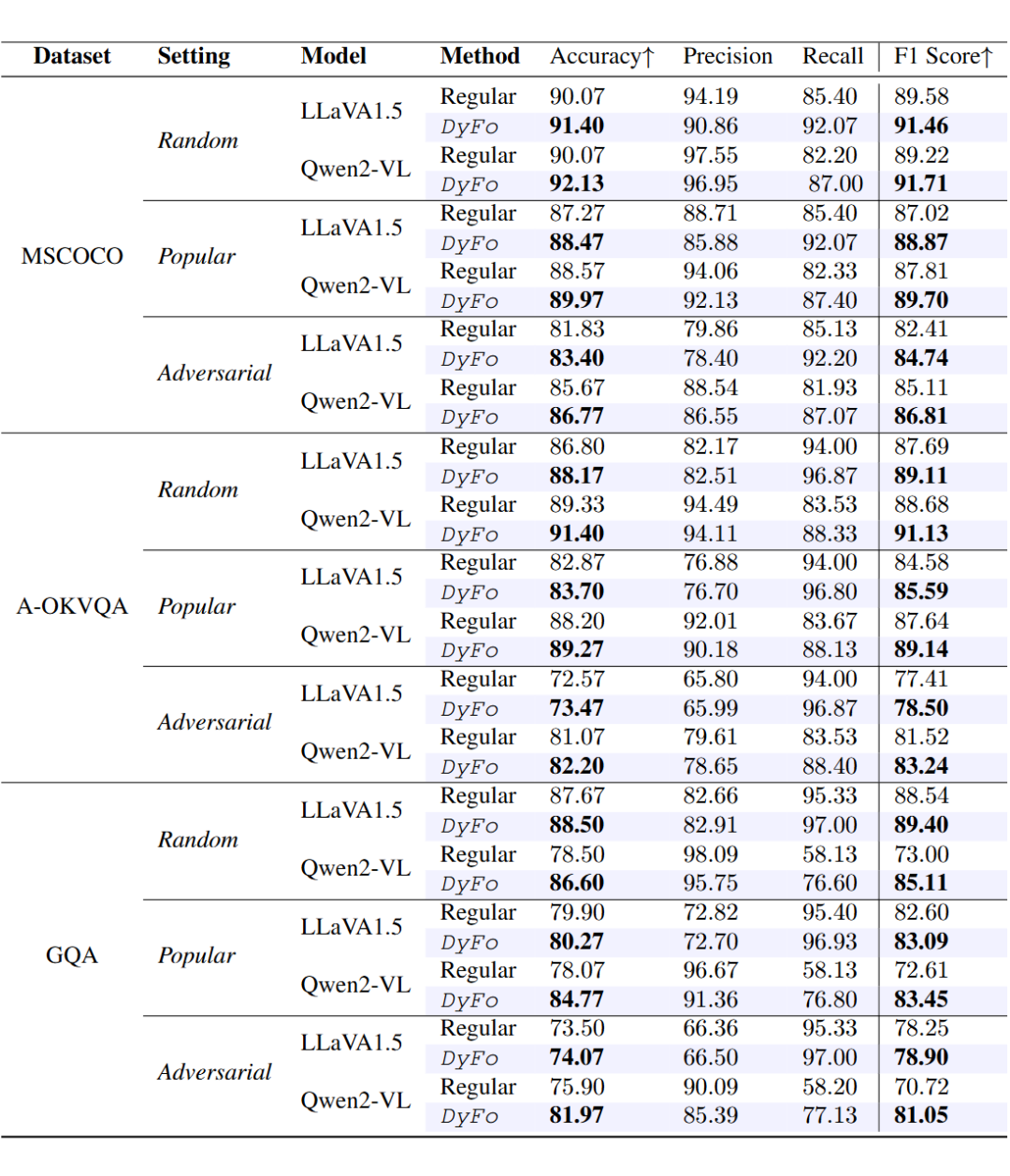
▲ 表1. POPE-(COCO, A-OKVQA, GQA)数据集上 DyFo 和对应多模态大模型效果对比
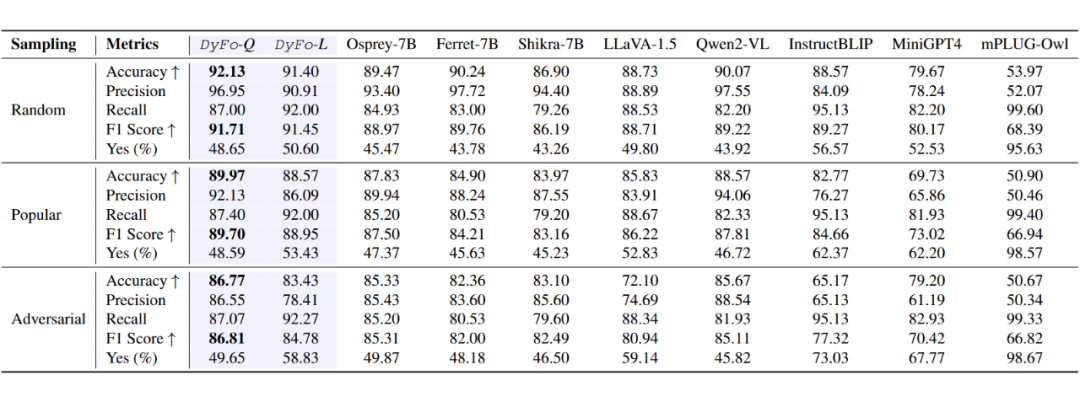
▲ 表2. POPE-COCO 数据集上 DyFo 和现有多种视觉增强大模型效果对比
在 POPE 基准测试中,DyFo 在三个数据集(COCO、AOKVQA、GQA)和三种采样策略(随机、流行、对抗)下均取得了显著性能提升。
与 LLaVA-1.5 和 Qwen2-VL 等固定分辨率和动态分辨率模型相比,DyFo 在准确率和 F1 分数等指标上均实现了一致提升。
实验结果表明,DyFo 通过结合聚焦树搜索和专家协作,能够有效过滤无关或误导性视觉内容,减少幻觉,增强细粒度视觉理解能力。在随机采样策略下,DyFo-Q(与 Qwen2-VL 结合)的准确率达到 92.13%,F1 分数达到 91.71%,显著优于基线模型。
4.2 V* Bench测试结果
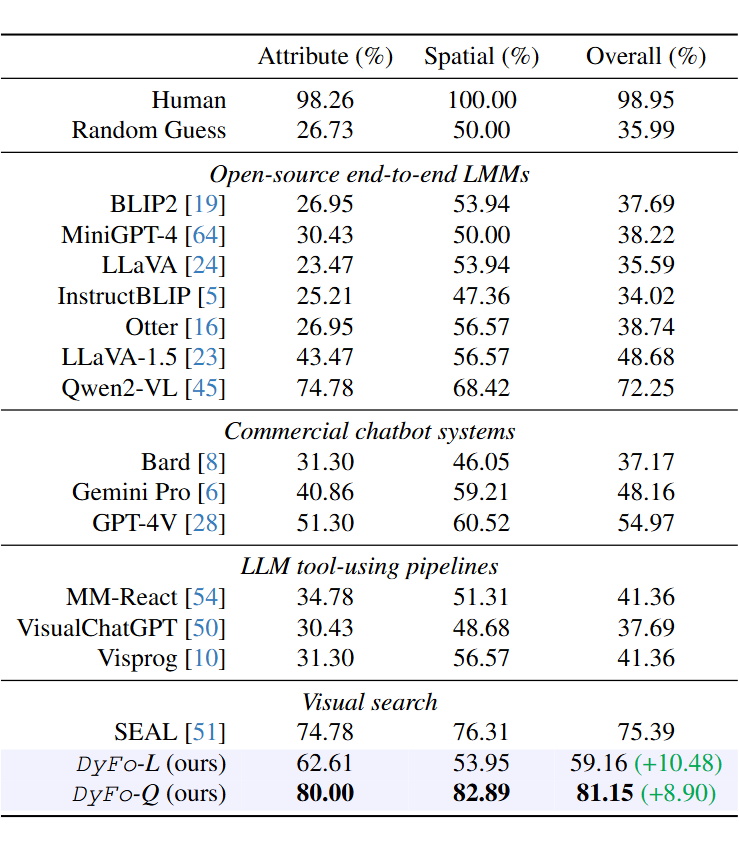
▲ 表3. V* Bench 数据集上 DyFo 和现有多种方法(开源、闭源、视觉搜索)效果对比
V* Bench 专注于高分辨率图像中的细粒度视觉理解任务,对模型聚焦细节的能力提出了更高挑战。实验结果显示,大多数多模态大模型在此测试中表现接近随机水平,而现有工具型方法也难以取得有意义的结果。
作为一种无需额外适应或训练的视觉搜索方法,DyFo 在属性识别和空间关系推理任务上均超越了 SEAL 等专门为细粒度视觉搜索设计的模型。这证明了灵活视觉搜索方法与多模态大模型集成的巨大潜力。
4.3 消融研究
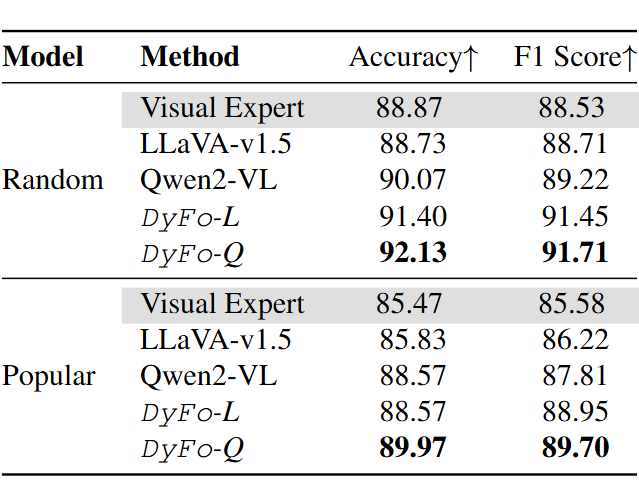
▲ 表4. POPE-COCO 数据集上对比视觉专家、原始模型和 DyFo 效果
研究团队进一步分析了动作空间设计对视觉定位的影响,发现结合多种动作能带来显著性能提升。与视觉专家的对比实验表明,DyFo 不仅从专家的视觉能力中获益,还能通过 LMMs 的参与弥补专家的局限性,实现互补增强。

▲ 图4. POPE 数据集上多种模型的案例对比(红框为 DyFo 最终关注区域)

▲ 图5. V* Bench 数据集上多种模型的案例对比(红框为 DyFo 最终关注区域)
案例研究展示了 DyFo 在低分辨率和高分辨率场景中的表现。在低分辨率示例中,DyFo 能够动态调整焦点区域(通过红框标示),使 LMMs 过滤无关内容并缓解幻觉问题。在高分辨率示例中,DyFo 成功聚焦占图像面积不到 1/50 的关键对象,证明了其处理复杂视觉任务的卓越能力。

结论
本文提出 DyFo(Dynamic Focus),一种训练无关、即插即用的动态聚焦视觉搜索方法。通过模拟人类视觉搜索行为并引入蒙特卡洛树搜索(MCTS)策略,DyFo 能够引导多模态大模型逐步聚焦关键视觉区域,显著缓解幻觉问题,提升在高分辨率与复杂场景下的细粒度理解能力。
作为对 OpenAI O3 所代表的“图像思考”范式的实用补充,DyFo 不依赖额外训练或模型修改,具备良好的通用性与工程可复用性。其异步推理架构为多策略开发与高效执行提供支持,有望为多模态系统提供更灵活可靠的视觉推理方案。
未来工作将进一步探索 DyFo 在开放环境、多模态链式推理等更广泛任务中的应用潜力,并研究其与不同类型视觉专家模型的协同机制,推动通用 LMMs 在高复杂度场景下的能力边界持续扩展。
(文:PaperWeekly)