


近日,MiniMax 正式开启 #MiniMaxWeek 技术周,第一弹重磅发布全新 M1 模型!
M1 模型在训练与推理效率方面实现了显著提升。RL训练成本仅需 53.3 万美元,推理效率提升至 DeepSeek R1 的 4 倍。
此外,模型增强了对超长文本的理解能力,最大可支持 100 万个 token 输入与 8 万个 token 输出,成为目前业内支持最长上下文的推理模型。
尤其值得关注的是,M1 在 Agent 工具调用任务中表现优异,堪称“Agent 好搭档”。
根据权威的 Artificial Analysis 机构排名,MiniMax M1超越了 Qwen3-235B,已经成为全球前二的开源模型:
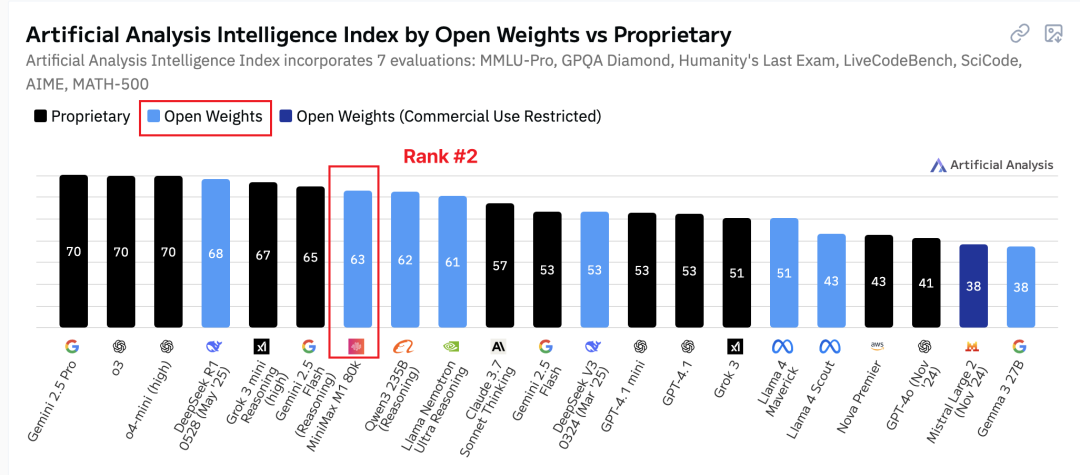
本次 MiniMax 秉承一贯的开源理念,将 M1 模型的技术报告与权重完全开源。
技术报告:
https://www.arxiv.org/pdf/2506.13585
开源仓库:
https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
线上体验:
https://chat.minimaxi.com/
接下来,就让我们一起揭开 M1 模型如此高效的神秘面纱!

核心技术揭秘:混合注意力架构与CISPO算法
架构层面,M1 模型以 MiniMax 此前开源的 MiniMax-Text-01 模型为基座,沿袭了高效的混合注意力架构,实现了近乎线性的注意力复杂度,在计算效率层面遥遥领先。
具体来说,相较于传统的平方复杂度的 Softmax 注意力,MiniMax-Text-01 引入了线性复杂度的 Lightning 模块。实现了计算效率的大提升。
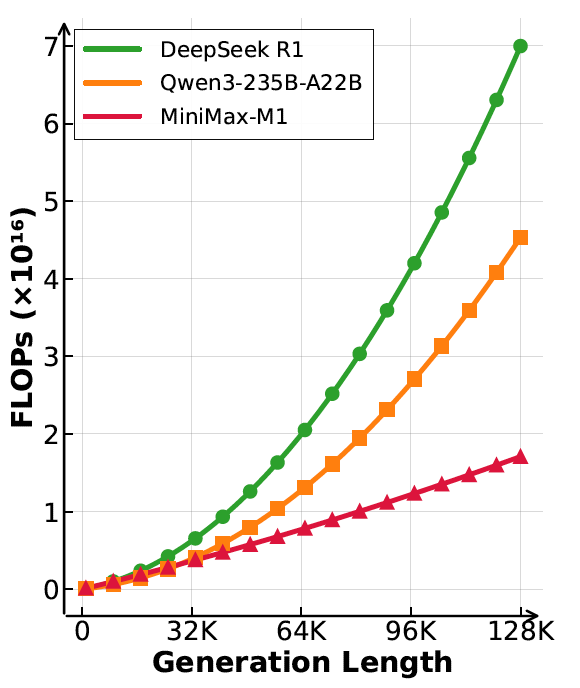
如图所示,同样都是生成 128K,MiniMax M1 的计算代价,也就是 FLOPs,显著低于 DeepSeek R1 模型与 Qwen3-235B-A22B 模型。
M1 模型基于 MiniMax-Text-01 进一步训练获得。主要分为三个阶段:
1. 构建了包含 7.5T token 的语料库,并进行了增量预训练;
2. 进行监督微调(SFT)注入 CoT 能力;
3. 进行强化学习,激活模型的 Reasoning 能力。
最核心的步骤,莫过于最后一步的强化学习阶段。线性注意力结构带来了计算效率的提升,但是也给 RL 带来了对应的挑战。
首先是训练推理两阶段 token 精度不对齐问题,也就是训练阶段和推理阶段下,token 精度没有很好地对齐。团队定位发现,该问题源于 LM 输出层的量化误差。因此,将该模块的计算精度提升到 FP32。
如下图所示,处理后 token 精度的相关系数从 0.98 提升至 0.99。
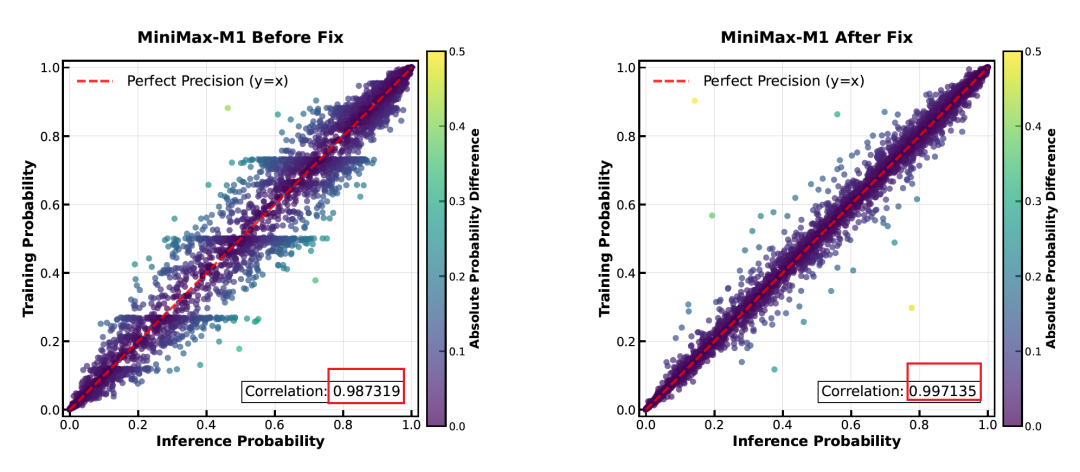
此外,MiniMax 团队,还对 AdamW 的超参数进行了细致调整,并设计了提前终止生成的策略来避免过长的病态输出。
在 RL 的算法角度,MiniMax 提出了 CISPO (Clipped IS-weight Policy Optimization) 算法来提升模型 Reasoning 能力的学习效率与最终效果。 CISPO 的学习目标如下:
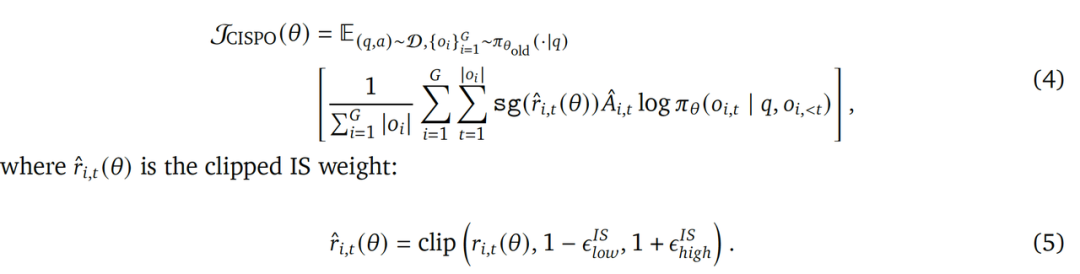
相较于 DeepSeek 提出的 GRPO 算法,CISPO 既能显式避免部分token因为 ratio 太大被截断,同时也能保持Entropy 在一定的范围内确保模型稳步收敛。在主流的 AIME 数据集上效果如下:
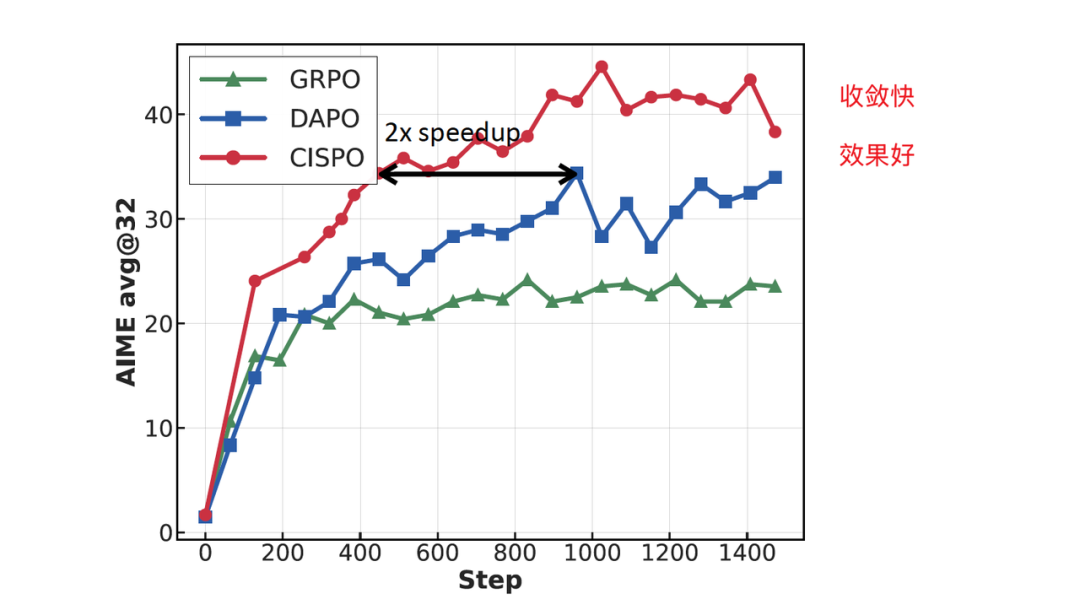
可以看出,CISPO 算法收敛更快,且效果更好。

再长文本也不怕,Agent Tool调用就用它
得益于优质的数据,先进的架构,强大的算法,MiniMax M1 模型面对超长文本性能优秀。
相对主流模型,M1 能够支持最高 1M token 的输入与 80K token 的输出。为了面对不同长度的任务,MiniMax 训练并开源了两个版本的 M1 模型,分别支持 40K 和 80K 的思考预算。

在业界主流的评测集上,M1 表现优异,在 OpenAI-MRCR 评测集上效果仅次于闭源模型 Gemini 2.5 Pro,位列全球第二。
在经典的数学与代码任务,如 AIME 2024 和 Live Codebench,M1 的效果追平 DeepSeek-R1 与 Qwen3-235B-A22B。
在复杂软件工程任务 SWE-Bench Verified 及 Agent 工具任务 TAU-Bench 上表现突出。
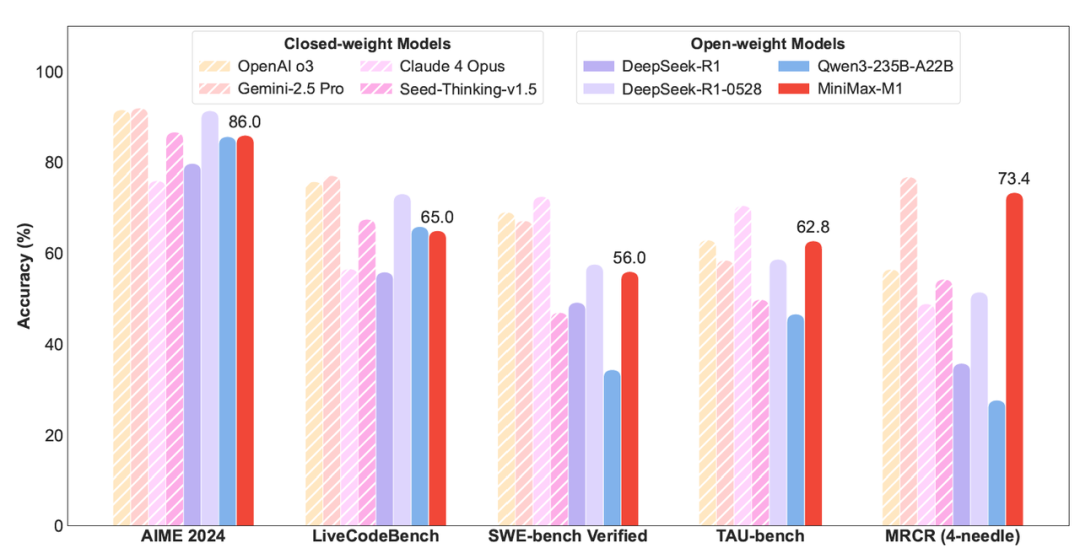
值得一提的是,TAU-Bench 是业内公认的多轮工具调用挑战性数据集。在该任务上,MiniMax-M1 取得了 62.8 分的成绩,力压 Gemini-2.5 Pro 和 OpenAI o3。面对多轮(超过30轮)长链路思考工具调用的复杂场景,M1 表现优异且稳定,展现极强的工具调用能力与稳定性。
值得一提的是,M1 还支持 agent 开发者以简单的 XML 格式工具结构来调用模型,且也可以泛化到未训练过的工具。
我们进行了实测,要求 M1 模型实现鼠标点击任意位置时屏幕出现烟花特效的功能,并指定模型使用 canvas 和 JavaScript 实现这个任务。M1 模型出色完成了该指令,具体演示如下:

MiniMax 秉承一贯的开源精神,将MiniMax M1权重完全开源,技术普惠。社区对此也是反响热烈,海内外多位知名开发者纷纷推荐转发,社区反响热烈。
国际科技媒体 VentureBeat 对此进行了专题报道:

多位海外研究者在 Twitter 上分享了对 M1 的看法,相关动态发布后一天内阅读量接近 2 万次,如:
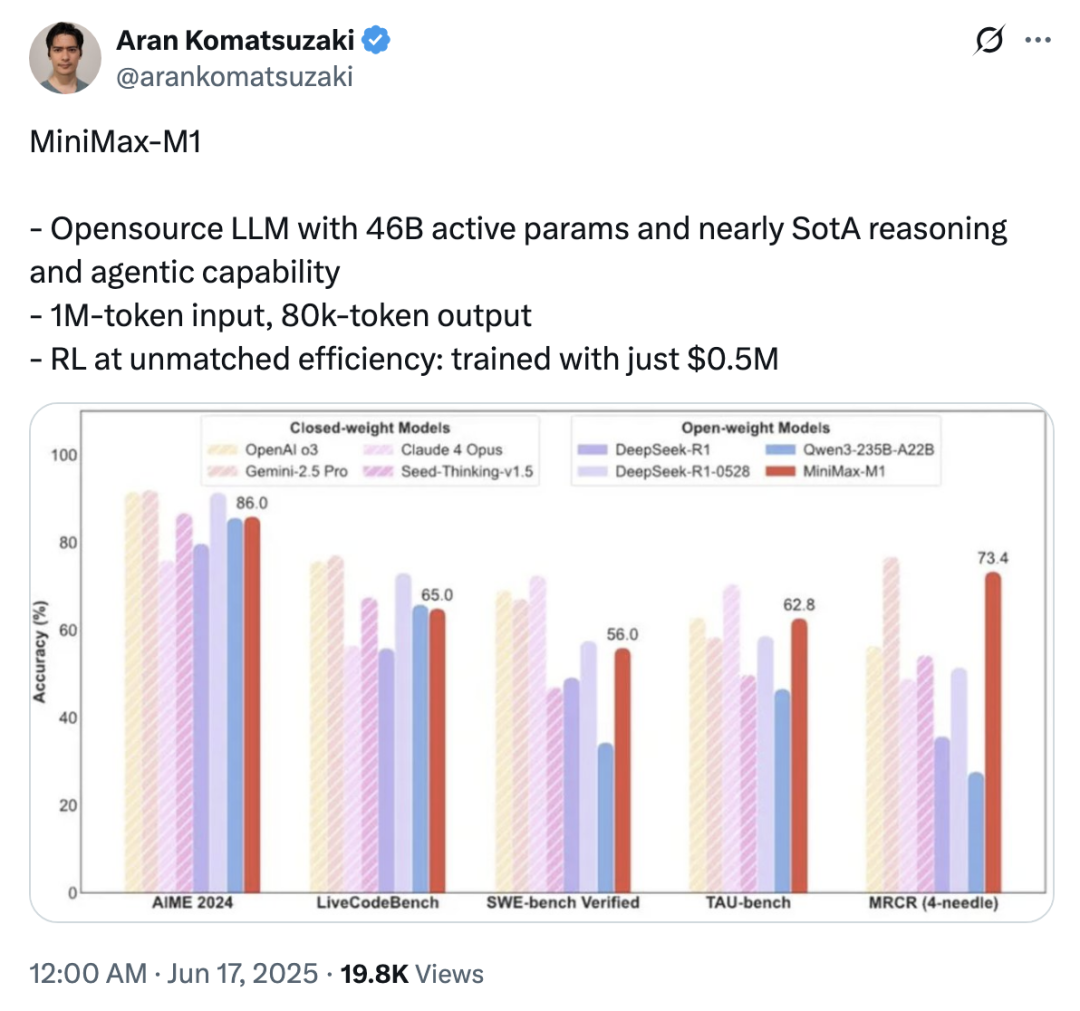
大家纷纷赞叹极低的训练成本与超长的思维链能力,这得益于MiniMax的混合注意力架构路线,更是得益于 MiniMax 强大的研发能力。
想要亲自体验这款训推成本低,文本长度极限突破的 MiniMax M1 模型?
点击阅读原文访问 MiniMax 官网,轻松调用,立即体验!
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

(文:PaperWeekly)