


随着信息检索和大语言模型(Large Language Models, LLMs)的高速发展,检索增强生成技术(Retrieval-Augmented Generation, RAG)已在文本知识库问答场景有了较为成熟的运用,RAG 系统能够根据用户提出的问题,快速从知识库中检索相关内容,并由大模型进行理解与总结,生成准确而丰富的答案。
然而,随着RAG系统的广泛使用,用户对问答场景的多样性也提出了新的需求。表格类的结构化数据是信息存储的常见形式,例如,一个企业的内部知识库中,既包含技术文档、管理制度等非结构化文本数据,也涵盖员工信息、财务报表等结构化表格内容。面对如此异构、复杂的多源知识,现有的 RAG 系统在处理涉及表格的问题时,常常无法给出令人满意的回答。大量实验结果表明,当大模型面对大量以 Markdown 或其他文本格式存储的表格数据时,在执行提取、筛选、计算和统计等较复杂的操作任务时,表现效果不佳。
为了解决这一难题,华为云信息检索团队提出了TableRAG 解决方案,它能够灵活应对包含文本和表格的异构文档问答任务,既轻量高效,又易于部署,具备良好的工业应用价值。

论文链接:https://arxiv.org/abs/2506.10380
传统RAG方法有什么缺陷?
目前主流的问答系统通常采用“检索增强生成”(Retrieval-Augmented Generation, RAG)技术[1,2],仅针对单一的非关系型数据库。针对包含表格信息的文档,传统做法通常会:
1.先将表格转化为 Markdown 格式的文本;
2.然后将整份文档进行分块(chunking);
3.再通过 embedding 模型将每个片段编码为向量;
4.最后在问答时检索出前 n 个相关片段,交由大模型生成答案。
但在这个“把表格序列化的过程中,带来了两个致命问题:
·结构化信息严重丢失:表格在转化为文本后,行列之间的原始结构被“压扁”了,导致关键的关系线索丢失。文本片段中还可能混入无关信息,使模型在推理时产生偏差。
·缺乏全局推理视角:文档被切割为多个局部片段后,模型往往只能“盲人摸象”,难以应对需要整合全局信息的多跳推理问题。
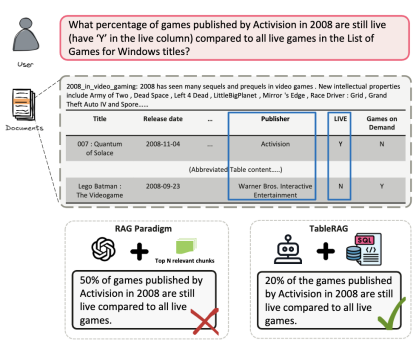
在上图示的例子中,由于表格在chunking过程中被从中间截断,RAG解决方案只选择了其中部分内容进行回答,所以计算错误了比例。
TableRAG 是如何解决的?
TableRAG 是一个混合推理框架,结合了“文本检索 + SQL 数据库操作”两种能力。它像一位专家一样思考,一方面理解复杂的文本语义,另一方面通过结构化数据库执行精准高效的表格推理。
TableRAG 包含离线建模与在线推理两个核心工作流:
·在离线阶段,不再将表格简单“压平”处理,而是保留其原始结构,构建为真正可查询的数据库表。
·在在线阶段,TableRAG 依次执行四个模块:上下文感知的问题拆解,文本检索,基于SQL的表格查询,中间结果整合与推理,逐步构建最终答案。
为全面评估 TableRAG 的推理能力,研究团队还构建了一个全新的评测集HeteQA,涵盖财经、医疗、科研等多个复杂领域,测试模型是否能解决异构文档中的深层逻辑关系。
接下来的章节将详细介绍TableRAG的架构设计和技术细节:
任务定义
对于异构文档问答(Heterogeneous Document Question Answering)任务,任务输入是异构的长文档(D, T),其中既包括非结构化的文本数据(记作T),也包含结构化的表格数据(记作D)。对于用户提出的问题(记作q),任务目标是设计一个函数F,让它能够理解这些文本和表格输入信息,并准确给出答案(记作A):F(D, T, q) → A
TableRAG
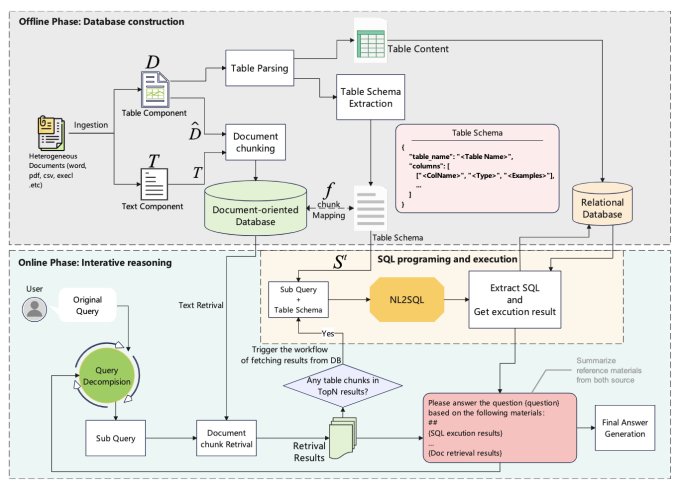
离线阶段,知识库构建
系统的离线阶段负责构建非结构化的文本向量数据库和结构化的关系型数据库。
对于异构的文档,先将其中的表格提取出来。当构建文本向量库时,表格序列化为markdown格式和其他文本内容一样切分为chunks入库;构建关系型数据库时,表格数据会保留原有的结构化形式存储在关系型数据库表中。
文本知识库
这个知识库不仅包括文档原始的文本内容,还包含将表格转化为Markdown格式后的序列化形式。这些文本和表格内容会被切分成chunks,然后利用预训练的大模型(如 BGE 模型)将它们转化为可用于搜索的向量表示。
表格数据库
Schema提取&建表
提取表格的Schema信息,主要包括表名(Table Name)、列名(ColName)、列类型(Type)等信息,并基于提取的Schema信息完成建表。
同时Schema信息还会被改造为该表的标准化描述,也就是“表格schema模板”(Table Schema Template),包括表格名称、每一列的名字、数据类型和示例数据。这种结构可以用类似 JSON 的格式表示:

建立映射关系
每一个含有表格内容的chunk都会与它所属的“表格schema”建立映射关系,这样就能确保系统在处理某段信息时,始终知道它来自哪个表、哪个列,不会“迷路”。
数据库接入
将所有表格数据导入到关系型数据库中(比如 MySQL),这样在后续的在线问答过程中,系统可以像执行 SQL 指令一样对表格进行查询和推理,实现复杂的数据逻辑处理
在线阶段,迭代式推理
为了应对那些需要跨多步、多种数据源(如文本和表格)进行复杂推理的查询,研究团队提出了一种“迭代式推理流程”。这个流程由四个关键步骤组成:
l上下文感知的查询拆解:将一个复杂问题合理拆解为更小、更容易处理的子问题;
l文本检索:从大规模文档中查找相关信息;
l基于SQL的表格查询:对表格数据执行结构化查询;
l中间答案组合:将不同来源的信息整合成最终答案。
查询拆解:
传统方法只是机械地切分问题,而TableRAG更聪明:它会结合数据的结构特征来判断哪些子问题该通过查表解决,哪些需要查文档。具体做法是:系统先从文本数据库中找出最相关的表格内容,并将其链接到对应的表结构描述。基于此,系统生成当前步骤(第t步)要解决的子问题。
文本检索
文本检索模块向量召回和重排序构成,挑出最相关的前k条内容用于后续推理。
表格推理:自动写 SQL,直接执行
当子问题涉及表格信息时,系统会自动编写 SQL 程序来查询数据库。具体地说,系统会检查检索到的内容中是否包含表格数据,如果有,就提取出其对应的表结构信息。然后根据表格schema信息和当前问题借助NL2SQL能力(可以由大模型驱动)以生成SQL查询语句,并直接在预先构建的关系型数据库中运行,获取查询结果。
答案组合:融合多源信息,智能判断
每个子问题的答案可能来源于两类信息:SQL 查询结果:结构化、精确,但可能出错;文本检索结果:上下文丰富,但可能不完整或误导。
这两类信息可能互相印证,也可能相互矛盾。为了得到更稳妥的答案,在此引入了一种组合式推理机制:系统会对比分析 SQL 结果和文本片段的一致性,并根据每种来源的可靠程度动态调整权重,得出最终的子答案。
当系统已经搜集够足以回答问题的信息后,迭代过程结束,输出整合后的最终答案。
Benchmark构建
研究团队从维基百科中挑选了结构丰富的大型表格,并结合一些复杂的逻辑操作(比如条件筛选、统计运算等),通过Claude 3.7辅助人工标注的方式构建了HeteQA数据集。这些问题不仅涉及表格理解,还需合文字信息,模拟真实复杂的查询需求。
第一步,自动生成问题:AI根据表格内容设计出复杂问题,同时生成可执行的SQL和Python代码计算答案。
第二步,人工校验答案:执行代码获取答案后,每个问题和答案都由人工审核,确保准确无误,如有问题会人工修改代码和答案。
第三步,添加文本指代:加入相关维基百科文章中的文字描述来替代某些实体,让问题能结合“表格+文本”两种信息来源。
HeteQA总共包括304个高质量问题,涵盖9大领域和5类核心表格推理方式。整个数据集来自136张维基表格,涉及5314个知识实体,兼具深度与广度。
实验结果
主要评测结果
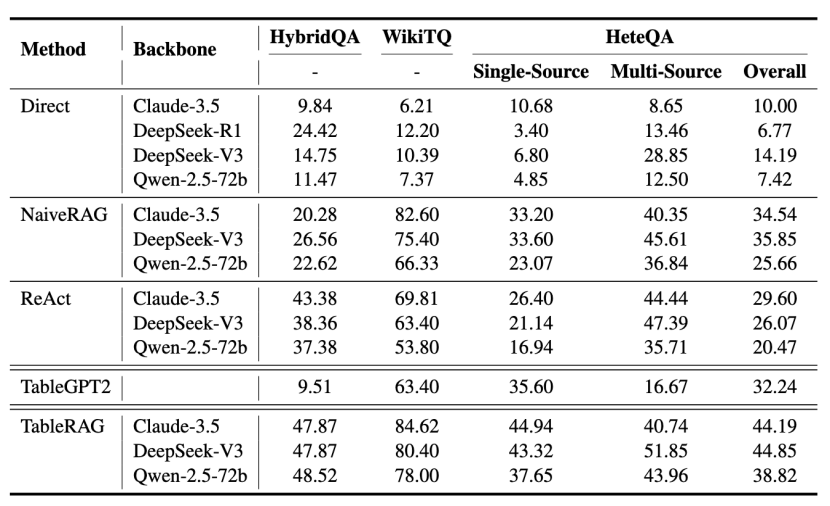
研究团队在开源基准[3,4]和HeteQA上进行了评测,TableRAG在所有基准数据集上展现出了巨大的效果优势,同时可以观察到以下结论。
1.ReAct 框架在处理多源混合信息时比普通的RAG效果更好,但在只涉及表格的问答任务中表现较差。TableGPT2 仅在单一来源的问题上表现还可以,比如 WikiTQ 数据集,但在面对多源问题时力不从心,说明它在处理复杂信息环境下的泛化能力有限。
2.TableRAG整体比现有最强方法还提升了至少10%。不管是处理单一表格,还是融合多个文本和表格,它都能稳定发挥。这得益于它结合了数据库查询(SQL)的能力,能利用SQL查询的优势,轻松并且可靠地解决全局过滤和复杂计算等问题。同时,TableRAG 对不同LLMs的适配性也很强,具有良好的通用性和扩展性。
深入分析结果
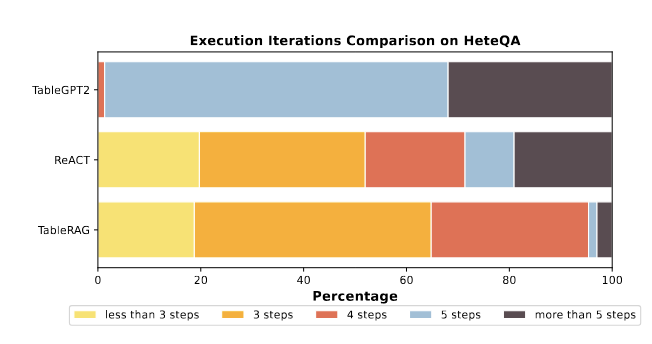
研究团队专门评估了 TableRAG 的推理效率,也就是它完成一个任务需要“几个步骤”。从实验结果来看,大多数情况下,TableRAG 在 5 步之内就能完成任务,其中约 63% 的问题在 5 步以内解决,另外 30% 正好用 5 步完成,几乎没有卡住的情况。
相比之下,其他方法比如 TableGPT2 动作就多,经常要用上五六步甚至更多。而 ReAct 虽然步数分布差不多,但表现远远不如 TableRAG。这说明 TableRAG 不仅思路更清晰、效率更高,而且推理能力也更强,处理表格问题时更像一个真正的专家。
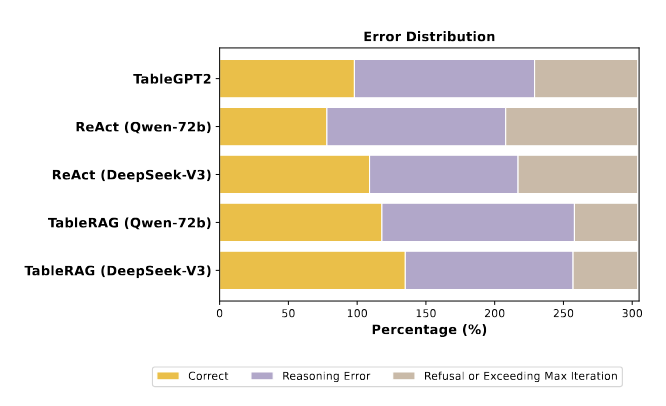
研究团队还对TableRAG模型进行了详细的错误分析,看看它在哪些情况下会出错。总体来看,错误主要分为两类:第一类是“推理失败”,比如执行SQL时出错,或者中间的问题分解不准确;第二类是“任务未完成”,比如模型拒绝回答,或者超过步骤限制后提前停止。
从图中可以看出,TableGPT2出错最多,原因是它不太擅长结合Wiki文档里的上下文信息,常常会说“我不会”或“无法回答”。ReAct虽然能做推理,但缺少模拟执行能力,常常会把简单问题搞得很复杂。
相比之下,TableRAG出错率是最低的,它在五步内就能稳定输出有效答案,得益于它能够根据上下文聪明地拆分问题,并选择合适的数据库操作策略。
局限性与未来展望
尽管TableRAG在异构问答任务中展现出明显优势,但仍存在以下局限与未来发展方向:
1.覆盖场景扩展:表格的形式多种多样,一些复杂结构如层级表头、单元格合并等特殊形式需要做额外兼容和处理。
2.复杂查询能力提升:面对多表联合查询和嵌套查询等复杂场景时,系统的推理准确性仍有待提升。可通过模型微调、Schema检索等方式提高。
3.模型增强:当前框架未涉及模型微调,若结合高质量数据进行端到端优化,有望进一步增强系统性能与泛化能力。
4.回答场景扩展:当前TableRAG应用场景尚以问答为主,未来可扩展为基于非结构化文本和结构化表格的更层次理解和推理任务,例如自动报表生成、趋势分析等多样化任务。
总结
在对多源异构知识库问答场景日益增长的需求下,传统RAG系统难以高效处理结构化表格与非结构化文本混合的信息。TableRAG应运而生,作为一种新型混合推理框架,它融合文本检索与SQL数据库查询两种能力,突破了“表格序列化”导致的信息丢失和推理偏差问题。配套构建的HeteQA评测集涵盖财经、医疗等多个领域,包含304个融合文本与结构化推理的复杂问答任务。设计的多组实验验证了TableRAG在准确率、效率与通用性上的显著优势,为RAG系统在异构多源等场景中提供了新范式。
引用
[1] Ziqi Jin and Wei Lu. 2023. Tab-cot: Zero-shot tabular chain of thought. arXiv preprint arXiv:2305.17812.
[2] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
[3] Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan Xiong, Hong Wang, and William Yang Wang. 2020. HybridQA: A dataset of multi-hop question answering over tabular and textual data. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1026–1036, Online. Association for Computational Linguistics.
[4] Panupong Pasupat and Percy Liang. 2015b. Compositional semantic parsing on semi-structured tables. arXiv preprint arXiv:1508.00305.
关于我们
MLNLP 社区是由国内外机器学习与自然语言处理学者联合构建的民间学术社区,目前已经发展为国内外知名的机器学习与自然语言处理社区,旨在促进机器学习,自然语言处理学术界、产业界和广大爱好者之间的进步。
社区可以为相关从业者的深造、就业及研究等方面提供开放交流平台。欢迎大家关注和加入我们。

关于我们
MLNLP 社区是由国内外机器学习与自然语言处理学者联合构建的民间学术社区,目前已经发展为国内外知名的机器学习与自然语言处理社区,旨在促进机器学习,自然语言处理学术界、产业界和广大爱好者之间的进步。
社区可以为相关从业者的深造、就业及研究等方面提供开放交流平台。欢迎大家关注和加入我们。
关于我们
(文:机器学习算法与自然语言处理)