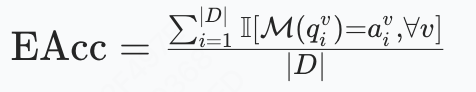![]()
数学推理能力作为衡量模型智能水平的关键指标,需对其进行全面公平的评估。然而,现有的 GSM8K、MATH 数学基准因覆盖不足和易被数据污染饱受诟病,要么缺乏对本科水平数学问题的广泛覆盖,要么可能受到测试集的污染。
为了填补这些空白,来自香港科技大学的研究团队近日发表在 ICLR 2025的最新研究 UGMathBench——首个针对本科数学的多元化动态评测体系,专为评估 LLM 在本科阶段各类数学主题下的推理能力而设计。它提供了动态多样的评估工具,首次将数学推理评测带入「动态污染防控」时代,标志着 LLMs 数学推理评估从“浅层解题”迈向“深层理解”。
论文地址:https://arxiv.org/pdf/2501.13766
该基准测试已经与 AGI-Eval 大模型评测社区达成合作,可至社区查看 UGMathBench 的所有子集!
数学推理对于评估 LLM 的基本推理能力越来越重要,随着现代 LLM 变得越来越强大,已有的基准测试对最新的 LLM 缺乏足够的挑战。在该领域现有数据集如 GSM8K(小学)、MATH(竞赛),大多聚焦中小学或竞赛数学,已逐渐被 LLM “攻克”,缺乏本科 level 的深度与广度。
UGMathBench 包含更广泛的主题、答案类型和测试示例,还有几个跨模态数学相关的数据集,以填补本科数学评估的空白。与常用数学基准相比,UGMathBench 被证明更具挑战性。例如,OpenAI-o1-mini 在 MATH 上 达到了94.8%的准确率,相比之下在 UGMathBench 上只达到了 56.3%。大多数开源 LLM(包括大多数专业的数学模型),在 UGMathBench 中都难以达到 30% 的 EAcc。
由于预训练数据通常从网上抓取大型语料库,任何静态基准都有数据污染的“记忆风险”—— 模型可能通过训练数据接触过测试题。数学推理的基准测试数据出现在新模型的训练集中,通过人为夸大性能,严重挑战公平的 LLM 评估。
一是维护私有测试集,要求希望评估其模型的人在排行榜发布结果之前提交预测以供集中处理,但这个过程可能效率低下,并且缺乏错误分析的透明度。其二是发布定期更新的动态基准。 UGMathBench 就是一个动态基准测试,通过设置不同的随机种子来为变量提供不同的采样值。
总之,UGMathBench 与其他数学基准的核心区别在于现有基准如 GSM8K(小学)、MATH(竞赛)层次较低,为静态基准,有数据污染的风险;UGMathBench 专注于本科数学推理,用动态随机化题目检测模型真实推理能力,其创新指标 EAcc 和 Δ 可有效衡量模型对变量扰动的真实推理能力,避免测试集污染。
UGMathBench 的构建是从在线作业评分系统中精心收集、整理和格式化本科水平的数学问题,核心优势体现在其全面性与动态性。
-
超全学科覆盖:UGMathBench 涵盖本科阶段数学的 16 个核心学科领域,包括单变量微积分、多变量微积分、微分方程、概率等,从而有111 个细分主题及 583 个子主题,包含 5062 个问题。
-
答案类型多元:分为 8 种原子答案类型和 2 种复合答案类型,答案类型范围从原子类型(例如,数值、表达式)到复合类型(例如,有序或无序列表中的多个答案),使 UGMathBench 与许多其他主要关注具有原子类型的单个答案的数学相关基准区分开来。
-
动态评估体系:每个问题包括 3 个随机版本,未来计划随模型性能提升而增加版本数。通过变量扰动(如系数、边界条件变化)创建多版本试题,确保模型依靠推理,进而真正理解阶梯逻辑,而非依靠记忆生成答案。
平均准确率(Acc):的准确率定义为模型在版本题集上的平均准确率,来评估该版本的平均性能。
鲁棒效率(RE):Δ与EAcc的比值,表示为 RE=Δ/EAcc,反映推理差距的相对大小。
传统准确率(Acc)难以揭示模型在问题变体中的稳定性。UGMathBench 引入两项创新指标:
-
平均准确率(AAcc):定义为所有 Acc 的平均值,
-
有效准确率(EAcc):衡量模型在所有随机化版本中均能正确解决问题的比例,量化真实推理。
若模型仅靠记忆特定数值,EAcc 会显著低于单一版本准确率。
-
推理差距(Δ):计算平均准确率与有效准确率的差值。
公式:Δ=AAcc−EAcc,衡量模型在面对问题变体时的推理鲁棒性,用来评估推理的稳健性,Δ=0表示完美鲁棒性。
研究团队对 OpenAI、Meta、Anthropic 等机构的23 个 LLMs进行了全面测试,结果揭示当前模型的短板。参测模型共23个,含 4 个闭源模型(如 OpenAI-o1-mini、GPT-4o)和 19 个开源模型(如 LLaMA-3、Qwen2-Math)。
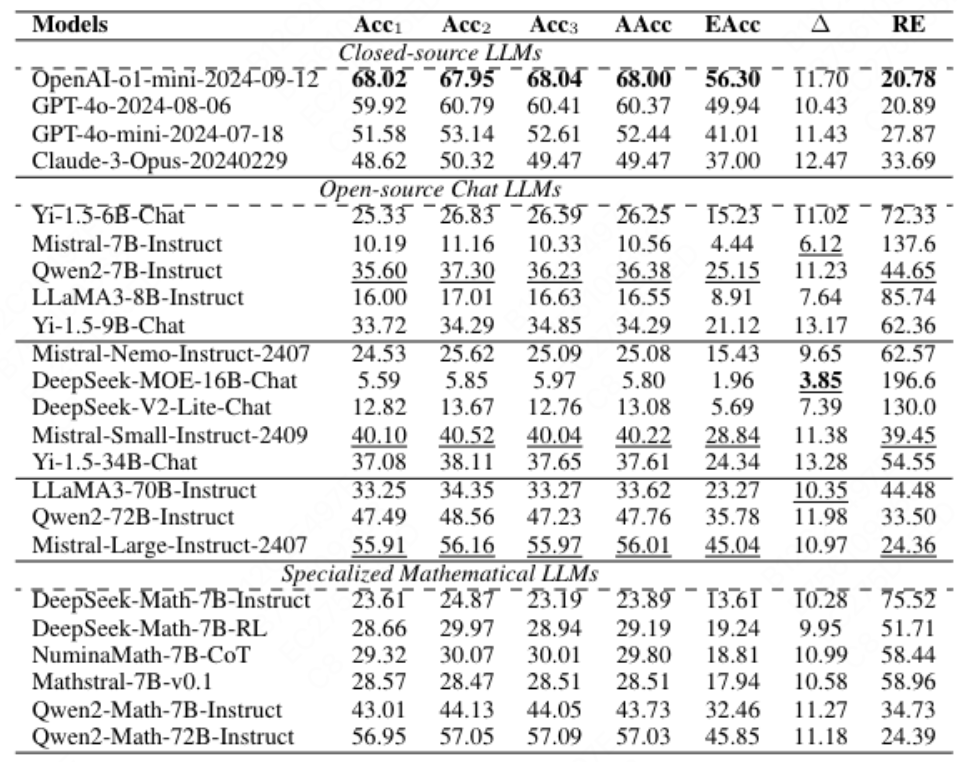
△UGMathBench 上的主要结果(所有数字均以 % 为单位)。模型根据其用途和来源分为三类。每列中的最佳结果以粗体显示,类似参数大小组中开源 Chat LLM 的最佳结果以下划线显示。
所有模型 Δ>10%,鲁棒效率最高达 196.6%(DeepSeek-MOE-16B-Chat),当前模型对变量扰动敏感,在问题变体上的推理一致性不足。所有 LLM 在 UGMathBench 上都表现出极高的鲁棒效率,值从 20.78% 到 196.6% 不等。在鲁棒效率最低的 5 款车型中,其中 3 款来自 OpenAI (OpenAI-o1-mini:20.78%;GPT-4o:20.89%;Mistral-Large-Instruct:24.36%;Qwen2-Math-72B-Instruct:24.39%;GPT-4o-mini:27.87%)。这些结果指出了当前 LLM 的局限性,并敦促我们开发具有高有效准确率和 Δ=0 的 “大型推理模型”。
在经研究团队测试推出的榜单中,前 5 名有 4 个为闭源模型,OpenAI-o1-mini 在平均准确率 、i=1,2,3 和有效准确率中取得了最佳结果,有效准确率仅为56.3%,且 Δ 为 11.7%,表明其在约 1/5 的问题变体中出错。
开源模型中, Qwen2-Math-72B-Instruct 表现最佳,有效准确率达到 45.85% ,接近 GPT-4o。然而,其仍与闭源模型存在显著差距,与 OpenAI-o1-mini 相比,它的平均准确率降低了 10.97%,有效准确率降低了 10.45%。此外,超过一半的开源模型(19 个中的 10 个)的有效准确率小于 20%。
算数、代数等基础学科:LLM 在算术问题方面很有效,有效准确率达到 62.8%,模型表现相对较好。在代数上达到了58.3%。LLM 还擅长组合学和复分析(超过 30% 的平均 有效准确率)。
抽象代数、微分方程和金融数学:平均有效准确率不到 10%,抽象代数仅约 5%,凸显高阶概念推理的不足。这些领域需深度逻辑推导与领域知识整合,现有 LLMs 缺乏足够训练数据与结构化推理能力。
-
计算错误:(如数值积分误差、矩阵运算错误)占比最高,反映模型在符号运算中的不稳定性。
-
推理不一致:同一问题的不同版本中,模型可能给出矛盾答案,其依赖表面特征而非深层逻辑。
UGMathBench 是一个多样且动态的基准测试,它的发布旨在全面评估 LLMs 在本科生水平的数学推理能力,不仅提供了评估工具,还指明了研究方向。UGMathBench 仅支持文本问题,当前的 LLMs 在这一领域仍有很大的改进空间。
UGMathBench 未来预计开发多模态版本,支持多语言数学问题评估,以及更多学科的问题数量,以更贴近真实学术场景。开发“大型推理模型”,目标是实现高有效准确率(EAcc 接近 100%)和 Δ→0 的模型,探索模型自适应训练以缩小推理差距,提升推理稳定性。优化评估代码,结合更优的提示策略和模型架构改进,持续更新数据集以提升质量。
UGMathBench 基准既是一面镜子,映照出当前 AI 的能力边界,更如一把钥匙,开启通往更具鲁棒性、可解释性 AI 的大门。
UGMathBench 已开源评估代码和数据集,期待学界利用这一工具,推动 LLMs 从“文字游戏”走向“真正的数学理解”!
-
GitHub:https://github.com/YangLabHKUST/UGMathBench
-
论文地址:https://arxiv.org/pdf/2501.13766
-
UGMathBench 评测集地址:https://agi-eval.cn/evaluation/detail?id=61
(文:AI科技大本营)