


前言
书接上回,Bruce 仗剑走天涯:sglang 源码学习笔记(一)- Cache、Req与Scheduler (https://zhuanlan.zhihu.com/p/17186885141)在上一篇文章中,我们介绍了sglang forward前的行为。本次我们详细解析forward 这个核心实现的全流程。
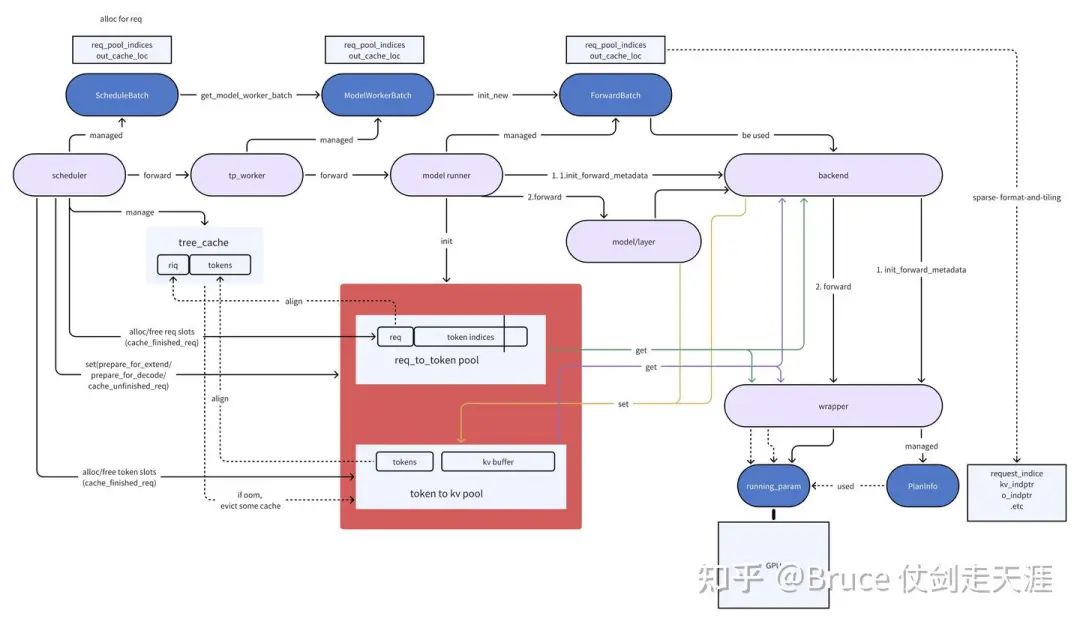
但首先我们回顾一下forward 的传递过程,也就是下面这张图。
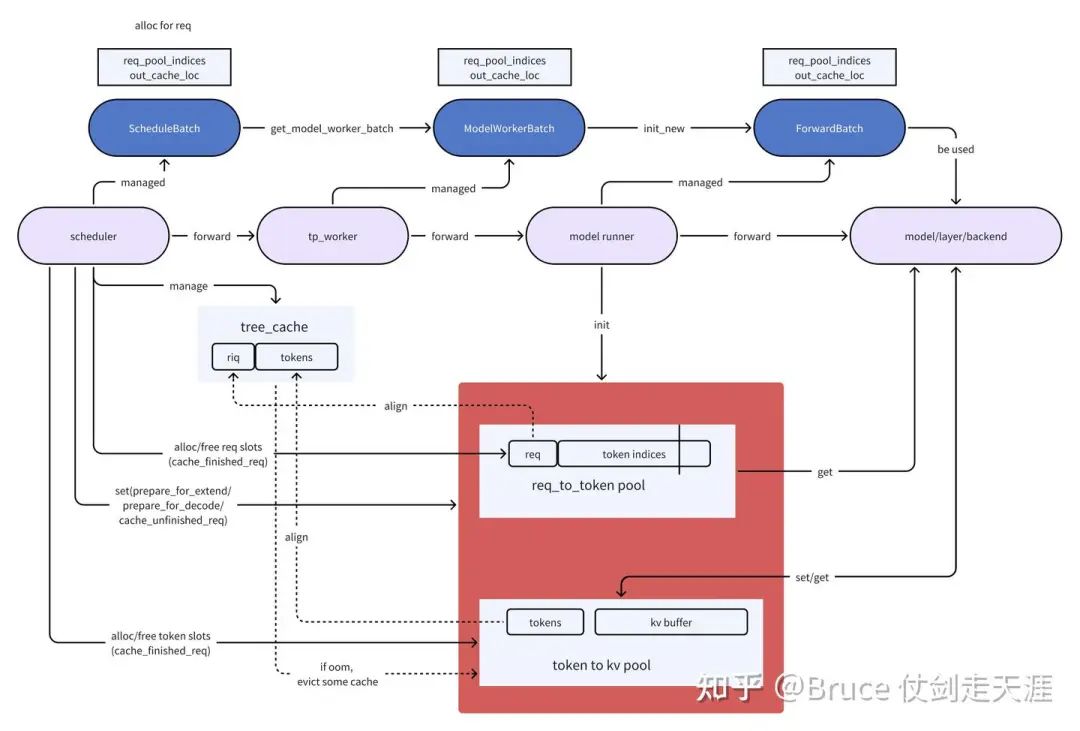
从这里,我们可以看到关键的推理过程,batch 是怎么传导进backend的,kvcache 是在哪里分配的以及如何被使用,这里我们需要记住req_pool_indice和out_cache_loc 这两个关键参数,他们是backend访问kvcache(memory_pool)的关键。

结合社区画的全流程图,我想读者对于sglang 推理的大体流程栈,已经有了一定的认识。
一句话,scheduler 为每个到来的请求,分配req_to_token_pool的slot和token_to_kv_pool的slot,随后由于不同请求的prefix cache匹配情况和推理类型,设置cache的相关字段(prefix tokens,extend tokens,等等),这些信息跟随batch 流入attentionbackend进行真正的forward。
这里为了方便理解,我们选择最常用的组合(MHA,decode-only,autogressive decoding),backend 选择flashinfer。
这一部分的代码主要位于python/sglang/srt/layers(https://github.com/sgl-project/sglang/tree/b5fb4ef58a6bbe6c105d533b69e8e8bc2bf4fc3c/python/sglang/srt/layers)和flahsinfer(https://github.com/flashinfer-ai/flashinfer/tree/9f5fbee3230136b0ccf4a88938d0e244dcaf4b26)(没错,我要补上一篇留下的坑了)。
为了解释逻辑更加清晰,我会先讲attentionBackend的部分,再去讲cudaGraphRunner的部分,cudaGraph 本身是个异步overlap cpu的策略,与主体推理逻辑基本正交,而且确实比较复杂。
接下来进入正文。
AttentionBackend
forward 的推理堆栈上文已经提过,穿过ModelRunner 后,基本是如下的过程,其中attentionBackend是其中的关键角色。
ModelRunner->Model->layer->attentionBackend通用数据结构
首先,我们仔细看看attentionBackend的数据结构。我们选择flashinferBackend 作为example。
# AttentionBackend 是所有具体backend 实现的基类, 这里可以观察到sglang 的attention对cuda graph 有比较强的依赖
# 这也是sglang overlap cpu & gpu excution的策略之一
class AttentionBackend(ABC):
def init_forward_metadata(self, forward_batch: ForwardBatch):
"""Init the metadata for a forward pass."""
def init_cuda_graph_state(self, max_bs: int):
"""Init the global shared states for cuda graph."""
def init_forward_metadata_capture_cuda_graph(....):
"""Init the metadata for a forward pass for capturing a cuda graph."""
def init_forward_metadata_replay_cuda_graph(....):
"""Init the metadata for a forward pass for replying a cuda graph."""
def get_cuda_graph_seq_len_fill_value(self):
"""Get the fill value for padded seq lens. Typically, it is 0 or 1."""
def forward(...):
"""Run forward on an attention layer."""
if forward_batch.forward_mode.is_decode():
return self.forward_decode(q, k, v, layer, forward_batch, save_kv_cache)
else:
return self.forward_extend()cuda graph的部分,我们下个部分再看,去掉cuda graph的部分,一个attentionBackend 需要至少两个接口:
init_forward_metadata与 forward。而这俩接口就是实现一个forward 最基本的接口,一个设置控制信息,一个进行推理。上篇我们介绍过一个decode forward函数,再看一遍。
def forward_decode(self, forward_batch: ForwardBatch):
self.attn_backend.init_forward_metadata(forward_batch)
return self.model.forward(
forward_batch.input_ids, forward_batch.positions, forward_batch
)一目了然。介绍完了基类,具体类,比如flashinferBackend 是怎么样呢?
flashinfer 是什么
下图是flashinfer paper中给的系统框架图,实际上实现比这个复杂,但是我们依旧可以获得一些总体的组件。
左半部分主要是sglang中的实现,有关pagtable和radix tree读过上文有关cache和scheduler的部分,相信大家有所理解了,这里的pagetable 和 pageattention 比较像,但是实际上sglang的实现是token-table和token attention的方式。radix tree 就是用于prefix match以方便共享cache,减少计算量。最后是block-sparse,将kvcache 表示成稀疏的格式表达。这就是进推理前,flashinfer & sglang 对kvcache的操作。右边,我们主要关心runtime scheduler,其实主要是tiling 过程,将当前batch tile到最佳CTA 配置上执行。JIT compiler 用于客制化,不用JIT 也有prebuilt的ops。
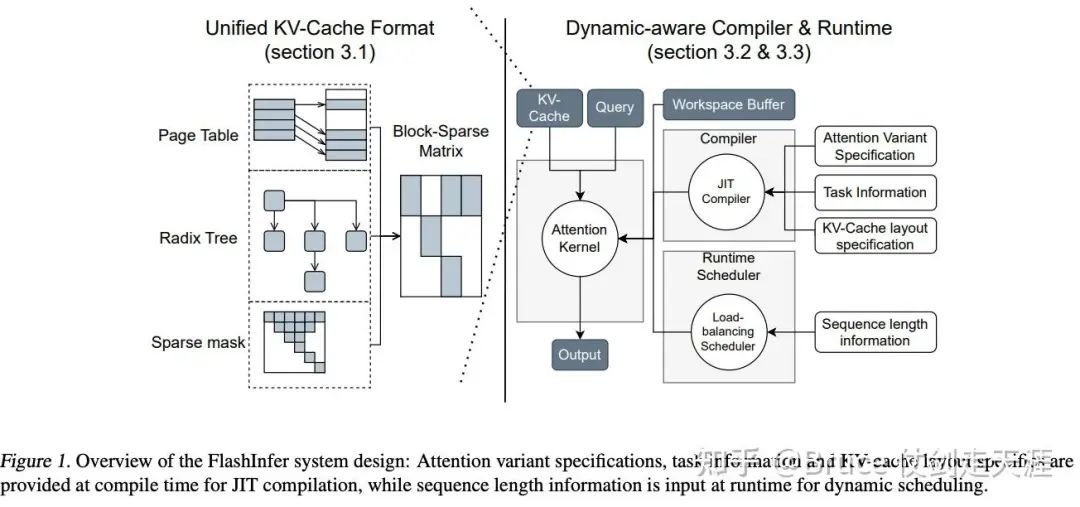
好,接下来让我们深入实现细节,看看flashinfer 内部实现。
Wrapper 是什么
让我们先介绍wrapper。
看过flashinfer 代码的朋友都会留意到wrapper 这个结构,我们可以简单认为是子任务的调度器/执行器,是flashinfer 对底层的封装。先来两张图,这里简单说明了一个forward 中flashbackend的内部结构和互动关系。整体来说,wrapper 是flashinfer 对底层执行的封装,与forward mode 对应,分为decode和prefill wrapper 两大类。与传统的执行流程不同,flashinfer 将配置和执行分成了两个步骤,先通过init_forward_metadata 配置硬件需要的参数(k,v cache的indice,query的indice),而后调用forward 接口进行正式推理。注意这两个步骤目前没有明显的overlap,所以应该是工程上拆成的两份,目前唯有一些很轻的memcpy(host to device)在这里overlap 了起来。
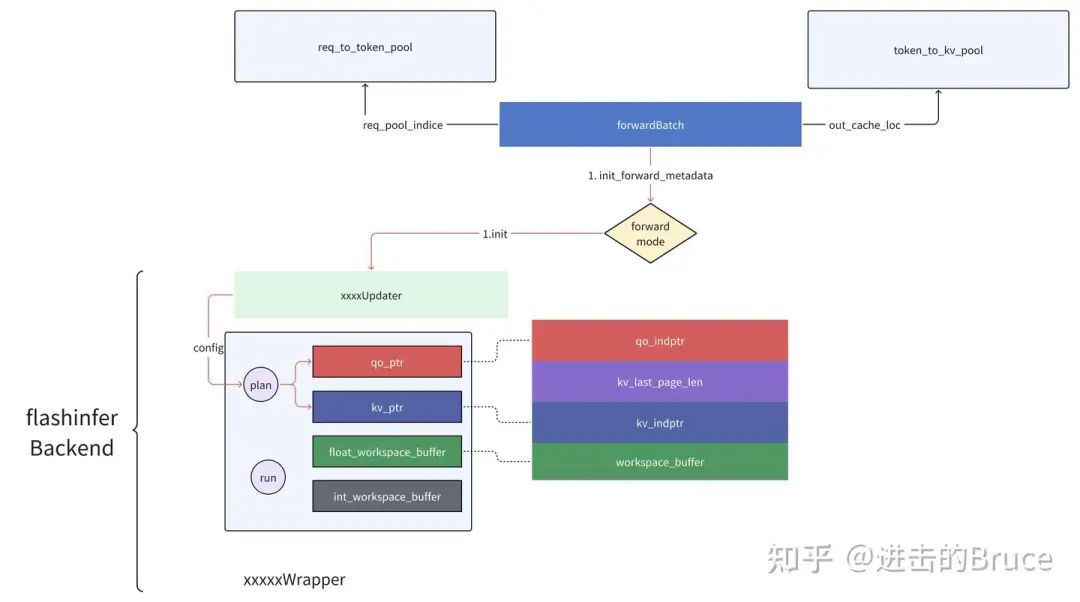
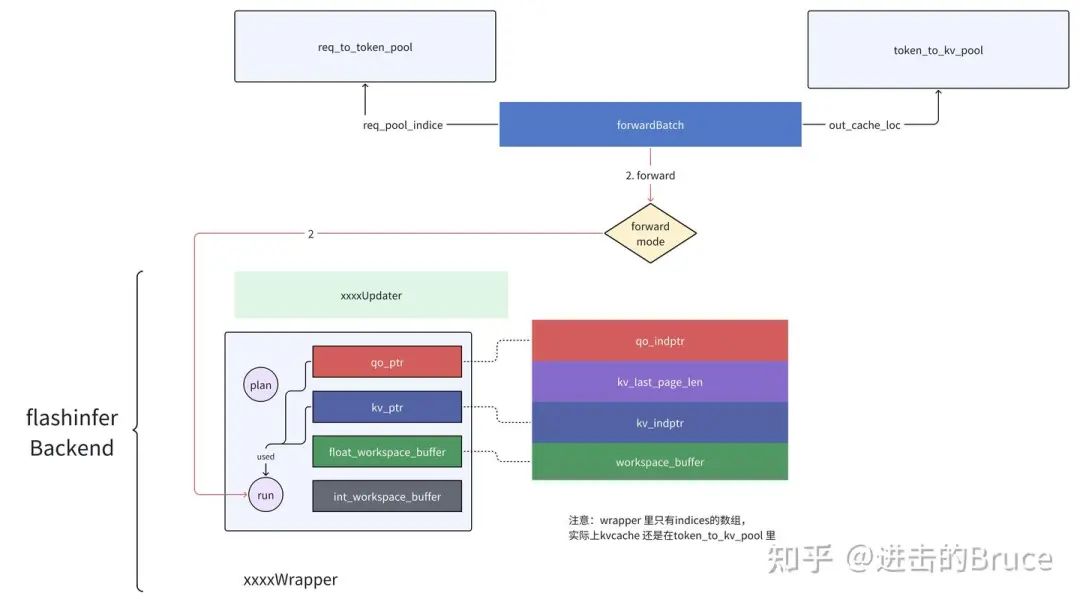
flashinfer 的完整初始化流程
好,现在我们看看flashinferBackend 其他的成员变量。
self.decode_use_tensor_cores = should_use_tensor_core(
kv_cache_dtype=model_runner.kv_cache_dtype,
num_attention_heads=model_runner.model_config.num_attention_heads
// get_attention_tp_size(),
num_kv_heads=model_runner.model_config.get_num_kv_heads(
get_attention_tp_size()
),
)首先是判断decode 过程需不需要使用tensor core,这个判断基于环境变量,数据类型和qga group。判断如下:
-
如果用户设置使用tensor core,则返回true
-
如果是float8_e4m3fn或者float8_e5m2,返回true
-
如果是float16,half或者bfloat16,且gqa group size 超过4,返回true
-
其他情况,不使用tensor core
env_override = os.environ.get("SGLANG_FLASHINFER_USE_TENSOR_CORE")
if env_override is not None:
return env_override.lower() == "true"
gqa_group_size = num_attention_heads // num_kv_heads
# Determine based on dtype and GQA group size
if kv_cache_dtype in (torch.float8_e4m3fn, torch.float8_e5m2):
return True
elif kv_cache_dtype in (torch.float16, torch.half, torch.bfloat16):
return gqa_group_size > 4
else:
return False也就是说,默认情况下,对于一个fp16或者bf16的 MHA,sglang 只会用cudacore 进行计算。我猜测原因可能是因为MHA下decode 的token 实际只有1,每个head的计算量其实是相对偏小的。但是为什么fp8 的decode 适合tensor core算呢?从官方说明上看,e4m3以及e5m2 tensor core 明确支持,但cuda core 支持并不好,所以是可以理解的。BTW,从 zihao 那里得知,其实sglang 一开始cuda core 是按fp16/bf16 调的,后面模板没有维护,所以fp8 目前只支持tensorcore,另外从当前attention 层的计算规模看,后面主要会是tensor core 计算,所以也没有后面花精力调cuda core decoding的打算。
接下来,设置最大上下文长度,和所需wrapper 个数。
self.max_context_len = model_runner.model_config.context_len
self.num_wrappers = 1
self.dispatch_reason = None # 在sliding window或者cross attention下,wrappers不同,但我们先不关注接下来,初始化内部资源,首先是workspace,注意这里的dtype 加剧用于分配buffer,没有其他用处,实际上最后这里最后会用于存储一些计算的中间结果。默认的workspace buffer 是384M,在Qwen2ForCausalLM下是512M。
# Allocate buffers
self.workspace_buffer = torch.empty(
global_config.flashinfer_workspace_size,
dtype=torch.uint8,
device=model_runner.device,
)
########## in global config######################################
self.flashinfer_workspace_size = os.environ.get(
"FLASHINFER_WORKSPACE_SIZE", 384 * 1024 * 1024
)随后是一些内部关键数组。其中kv_indptr与 qo_indptr是一个wrapper 一个,kv_last_page_len 是一个backend 一个。这些数据结构都是flashinfer 内不需要用的。
max_bs = model_runner.req_to_token_pool.size
self.kv_indptr = [
torch.zeros((max_bs + 1,), dtype=torch.int32, device=model_runner.device)
for _ in range(self.num_wrappers)
]
self.kv_last_page_len = torch.ones(
(max_bs,), dtype=torch.int32, device=model_runner.device
)
self.qo_indptr = [
torch.zeros((max_bs + 1,), dtype=torch.int32, device=model_runner.device)
for _ in range(self.num_wrappers)
]其实从这里已经可以嗅到稀疏化的味道,眼疾的朋友,应该会联想到稀疏化的格式表达。indptr 通常数组用于指示每一行(或列)中非零元素的起始和结束位置。对于kv cache 来说,向gpu 刻画一个 稀疏矩阵,需要kv_indptr,kv_indices以及kv buffer。而对于query/output来说,由于query 是一个ragged tensor,所以就只需要indptr。至于这里为什么是max_bs+1,是由于indptr[0]是辅助用的,真正存储数据的是indptr [1:max_bs]。
kv_last_page_len 这个数组我们也需要解释一下。这里的page len的单位是token num,也就是一个page 存几个token 对应cache的意思,不过实际使用上,sglang的page size都是1,也就是一个page 一个token的cache。这里的page 和 实际物理页没有关系,只是一个内存的管理单元,仅仅在碎片管理的角度有意义。
接下来,创建核心子执行器wrapper, 由于我们这里只考虑decode-only selfattention的情况,所以如下的num_wrapper 为1。
# Create wrappers
# NOTE: we do not use ragged attention when there are multiple wrappers
self.prefill_wrapper_ragged = (
BatchPrefillWithRaggedKVCacheWrapper(self.workspace_buffer, "NHD")
if self.num_wrappers == 1
else None
)
# Two wrappers: one for sliding window attention and one for full attention.
# Using two wrappers is unnecessary in the current PR, but are prepared for future PRs
self.prefill_wrappers_paged = []
self.prefill_wrappers_verify = []
self.decode_wrappers = []
for _ in range(self.num_wrappers):
self.prefill_wrappers_paged.append(
BatchPrefillWithPagedKVCacheWrapper(self.workspace_buffer, "NHD")
)
self.prefill_wrappers_verify.append(
BatchPrefillWithPagedKVCacheWrapper(self.workspace_buffer, "NHD")
)
self.decode_wrappers.append(
BatchDecodeWithPagedKVCacheWrapper(
self.workspace_buffer,
"NHD",
use_tensor_cores=self.decode_use_tensor_cores,
)
)这里实际上包括四种wrapper,具体wrapper 内部的数据结构和初始化,我们放到最后看。
| wrapper类别 | wrapper 实现 | 场景 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
随后就是对wrapper 输入的更新器,这里只有两类,Prefill和Decode。
# Create indices updater
self.indices_updater_decode = FlashInferIndicesUpdaterDecode(model_runner, self)
self.indices_updater_prefill = FlashInferIndicesUpdaterPrefill(
model_runner, self
)这里没有什么可以特别说明的,updater的初始化,基本上就是把attentionbackend和model_runner 里的结构赋值过去。读者可以通过下面的例子感受一下,dispatch部分我们只看update_single_wrapper 即可。
self.num_qo_heads = (
model_runner.model_config.num_attention_heads // get_attention_tp_size()
)
self.num_kv_heads = model_runner.model_config.get_num_kv_heads(
get_attention_tp_size()
)
self.head_dim = model_runner.model_config.head_dim
self.data_type = model_runner.kv_cache_dtype
self.q_data_type = model_runner.dtype
self.sliding_window_size = model_runner.sliding_window_size
self.attn_backend = attn_backend
# Buffers and wrappers
self.kv_indptr = attn_backend.kv_indptr
self.kv_last_page_len = attn_backend.kv_last_page_len
self.qo_indptr = attn_backend.qo_indptr
self.req_to_token = model_runner.req_to_token_pool.req_to_token
self.prefill_wrapper_ragged = attn_backend.prefill_wrapper_ragged
# Dispatch the update function
if self.attn_backend.dispatch_reason == WrapperDispatch.SLIDING_WINDOW:
self.update = self.update_sliding_window
elif self.attn_backend.dispatch_reason == WrapperDispatch.CROSS_ATTENTION:
self.update = self.update_cross_attention
else:
assert self.attn_backend.num_wrappers == 1
self.update = self.update_single_wrapper另外需要说明的是forward_metadata,forward metadata 和 updater 对应,包括两种,由于sglang scheduler 本身同时只会有一个forward batch,所以只需要一份forward metadata 即可。
# Other metadata
self.forward_metadata: Union[PrefillMetadata, DecodeMetadata] = None
self.decode_cuda_graph_metadata = {}
self.prefill_cuda_graph_metadata = {}这里的forward_metadata 其实主要是Wrapper 和周围参数,每次forward 都会在metadata里指定wrapper。
@dataclassclassDecodeMetadata:
decode_wrappers:List[BatchDecodeWithPagedKVCacheWrapper]@dataclassclassPrefillMetadata:
prefill_wrappers:List[BatchPrefillWithPagedKVCacheWrapper]
use_ragged:bool
extend_no_prefix:boolwrapper 的数据结构和初始化过程
首先是检查入参,kv layout 只支持NHD和HND。
_check_kv_layout(kv_layout)有关jit 的功能, 我们先不管。所以直接看内部新引入的资源,以下以BatchPrefillWithPagedKVCacheWrapper 为例。
## 前三行就是入参赋值,没啥好说的
self._kv_layout = kv_layout
self._float_workspace_buffer = float_workspace_buffer
self.device = float_workspace_buffer.device
## 这里的backend 更多程度上其实是底层实现用flashattention2还是flashattention3
## auto 即自动识别,如果当前硬件支持fa3则用fa3,否则用fa2,而对于fa3
## vector_sparse 可以理解为一种中间形式的稀疏表达,之所以fa3 需要存储这个中间数组
## 是由于考虑到fa3下将vector_sparse 存放于GPU寄存器的话,寄存器不够
if backend in ["fa3", "auto"]:
# NOTE(Zihao): assume maximum accumulate kv length is 16M
self._vector_sparse_indices_buffer = torch.empty(
(16 * 1024 * 1024,), dtype=torch.int32, device=self.device
)
# NOTE(Zihao): assume maximum batch size is 32768
self._vector_sparse_indptr_buffer = torch.empty(
(32768,), dtype=torch.int32, device=self.device
)
## kv_lens_buffer 实际是请求对应的kv cache len的长度,单位也是tokens num
self._kv_lens_buffer = torch.empty(
(32768,), dtype=torch.int32, device=self.device
)
## 如下两个都是存储控制信息的buffer,区别在于_int_workspace_buffer是device 侧的buffer
## _pin_memory_int_workspace_buffer是host 侧的buffer,二者通过cudaMemcpyAsync 互相交互
## 后面我们会看到这个结构就是init_forward_metadata的核心。
self._int_workspace_buffer = torch.empty(
(8 * 1024 * 1024,), dtype=torch.uint8, device=self.device
)
self._pin_memory_int_workspace_buffer = torch.empty(
self._int_workspace_buffer.shape,
dtype=self._int_workspace_buffer.dtype,
device="cpu",
pin_memory=True,
)以上的资源属于wrapper 内部的核心资源,最后就是将attentionbackend 引用进来方便访问。
self._qo_indptr_buf = qo_indptr_buf
self._paged_kv_indptr_buf = paged_kv_indptr_buf
self._paged_kv_indices_buf = paged_kv_indices_buf
self._paged_kv_last_page_len_buf = paged_kv_last_page_len_buf
self._backend = backend
## 以下主要是cuda graph使用参数,我们放到cuda graph 模式讲。
self._custom_mask_buf = custom_mask_buf
self._mask_indptr_buf = mask_indptr_buf
self._max_total_num_rows = None而 decode wrapper 也比较类似,但是没有了其中一部分,注意我们这里也暂时屏蔽了cuda graph相关的实现。
可以看到,decode 下,query 相关的结构不见了(_qo_indptr_buf与_kv_lens_buffer),对于decode,都是one-by-one 的输出,query相关的内容本身也已经在gpu cache上,不需要额外传入(但是cuda graph 模式下也有query 相关结构,我们再解析)。另外,由于fa3 主要是在fa2 基础上加了seq parallel,只影响prefill,所以decode 这边不需要vector_sparse 这个中间层的buffer。
self._kv_layout = kv_layout
self._float_workspace_buffer = float_workspace_buffer
self.device = float_workspace_buffer.device
self._int_workspace_buffer = torch.empty(
(8 * 1024 * 1024,), dtype=torch.uint8, device=self.device
)
self._pin_memory_int_workspace_buffer = torch.empty(
(8 * 1024 * 1024,),
dtype=torch.uint8,
pin_memory=True,
device="cpu",
)
self._fixed_batch_size = 0
self._paged_kv_indptr_buf = paged_kv_indptr_buffer
self._paged_kv_indices_buf = paged_kv_indices_buffer
self._paged_kv_last_page_len_buf = paged_kv_last_page_len_buffer
self._use_tensor_cores = use_tensor_cores
self._use_cuda_graph = use_cuda_graph本节最后,简单说明一下wrapper 的两个主要接口的功能。
1.plan forward 过程的第一步,将控制信息写入gpu
2. run forward过程第二步,从model 里forward会获得更新后的kvcache(有些forward 会在model 层进行kvcache的更新,比如deepseek),此时调用wrapper的run进行low-level 的run。
下图就是forward 过程中各结构接口的调用关系。

Plan Info 是什么
另外,我们还需要介绍一下plan info。这是wrapper的核心数据结构之一,属于运行的配置信息,plan info即flashinfer 计划为本次forward 提供的配置信息。数据结构如下:
struct PrefillPlanInfo {
int64_t padded_batch_size; # batch size, 和forward batchsize有一丝区别
# forwardbatch的batchsize 是当前batch里请求的个数
# padded_batch_size 可能比forward size大,它面向GPU CTA
# 每个CTA 需要计算的tile根据请求情况获得,padding_batchsize 根据tile 计算
int64_t total_num_rows; # 当前batch 处理总输入token长度, 对应sum(qo_indptr)
int64_t total_num_rows_offset; # 对应qo_indptr的数组指针
int64_t cta_tile_q; # 一个CTA 负责处理的query 长度,即tile 后的query 长度, 下面假设query 0 input 被tile成三个tile
int64_t request_indices_offset; # tile 后的request index 数组指针,like [0, 0, 0]
int64_t qo_tile_indices_offset; # tile 后的query index 数组指针,like 请求0 被tile 成三份,like[0, 1, 2]
int64_t kv_tile_indices_offset; # tile 后的kv index 数组指针,如果kv chunksize > need_kv_len, 则为[0, 0, 0]
int64_t merge_indptr_offset; # merge indptr 与tile 无关,是与请求和gqa有关的
# 如果模型的group size为4,则一个请求对应四个merge_indptr项, 比如[100,200,300,400]
int64_t o_indptr_offset; # 一个请求一个,值为对齐到tile_kv_len * group_size(mha下为1)
int64_t kv_chunk_size_ptr_offset; # 这里也是个数组指针,但是数组size 为1,内容就是kv_chunk_size
int64_t v_offset; # attention中间态计算结果,s_ = q*k, v_ = softmax(s_)*v
int64_t s_offset;
int64_t block_valid_mask_offset; # 数组指针,数组内容是根据tile 分片后的block是不是有效的
# 一般都是有效,但在cudagraph的使用下,会有不对齐的情况,以后再说
bool enable_cuda_graph; # 使用cuda graph
bool split_kv; # 是否进行了分片
}plan info 实在是面向gpu的核心数据结构,这里才有了我们以往耳熟能详的tiling 过程。现在我们可以继续补充forward batch的流程图,forward batch 走进wrapper 里就是plan info了。
init_forward_meta 与 plan/prefill 举例
理解了整个初始化和主要的数据结构,接下来我们可以看看init_forward_meta的过程了。这里的核心就是wrapper的plan 接口。如下我列出了其中prefill 的branch的case(不考虑encoder-decoder 和 sliding window的实现)。
def init_forward_metadata(self, forward_batch: ForwardBatch):
prefix_lens = forward_batch.extend_prefix_lens
# Some heuristics to check whether to use ragged forward
# 如果有prefill token 太长的情况,使用ragged tensor
if forward_batch.extend_num_tokens >= 4096 and self.num_wrappers == 1:
use_ragged = True
extend_no_prefix = not any(forward_batch.extend_prefix_lens_cpu)
else:
use_ragged = False
extend_no_prefix = False
# 通过updater 更新 prefill wrapper
self.indices_updater_prefill.update(
forward_batch.req_pool_indices,
forward_batch.seq_lens,
forward_batch.seq_lens_sum,
prefix_lens,
prefill_wrappers=self.prefill_wrappers_paged,
use_ragged=use_ragged,
encoder_lens=forward_batch.encoder_lens,
spec_info=None,
)
## 更新forward_metadata
self.forward_metadata = PrefillMetadata(
self.prefill_wrappers_paged, use_ragged, extend_no_prefix
)这里ForwardBatch的字段内容可以参考Bruce 仗剑走天涯:sglang 源码学习笔记(一)- Cache、Req与Scheduler(https://zhuanlan.zhihu.com/p/17186885141)里的说明。其中最重要的是update接口, 这里最终会调用到wrapper的plan,栈如下。实际上begin_forward 就是 plan,指针是同一个。
FlashInferAttnBackend.init_forward_metadata->
FlashInferIndicesUpdaterPrefill.update_single_wrapper->
FlashInferIndicesUpdaterPrefill.call_begin_forward->
BatchPrefillWithPagedKVCacheWrapper.begin_forward->
BatchPrefillWithPagedKVCacheWrapper.plan我们主要讲两个函数的实现,call_begin_forward与plan。
call_begin_forward
def call_begin_forward(
self,
wrapper_ragged: BatchPrefillWithRaggedKVCacheWrapper, # ragged wrapper, 用于输入较长的情况
wrapper_paged: BatchPrefillWithPagedKVCacheWrapper, # 主要使用的wrapper
req_pool_indices: torch.Tensor, # batch中包含的请求index
paged_kernel_lens: torch.Tensor, # 请求的长度(对ragged 情况下,对应extend_prefix_lens)
paged_kernel_lens_sum: int, # paged_kernel_lens 之和
seq_lens: torch.Tensor, # 请求的完整长度
prefix_lens: torch.Tensor, # extend_prefix_lens
kv_start_idx: torch.Tensor, # 传参为一般None,实际上指各请求kv cache的起始index
kv_indptr: torch.Tensor, # attention backend 的kv 数组
qo_indptr: torch.Tensor, # attention backend 的qo 数组
use_ragged: bool, # 是否使用ragged tensor用于query
spec_info: Optional[SpecInfo], # 是否是投机推理
):如上是call_begin_forward的传参,方便大家理解一些上下文。接下来是具体的实现。
## 获得当前batch的batchsize
bs = len(req_pool_indices)
if spec_info is None:
# Normal extend
# indptr 意为矩阵中每行非零值的起始位置,以下说明了每个请求的输出token存kv cache的位置
kv_indptr[1 : bs + 1] = torch.cumsum(paged_kernel_lens, dim=0)
kv_indptr = kv_indptr[: bs + 1]
# 这里将分配一个数组,具体赋值在create_flashinfer_kv_indices_triton中
kv_indices = torch.empty(
paged_kernel_lens_sum, dtype=torch.int32, device="cuda"
)
## 注意,这是一个并行函数,并行度是bs,如下调用说明同时起了bs个trtion 内核执行,入参都一样
create_flashinfer_kv_indices_triton[(bs,)](
self.req_to_token,
req_pool_indices,
paged_kernel_lens,
kv_indptr,
kv_start_idx,
kv_indices,
self.req_to_token.shape[1],
)
## 以下说明了每个请求的输出token的起始位置
qo_indptr[1 : bs + 1] = torch.cumsum(seq_lens - prefix_lens, dim=0)
qo_indptr = qo_indptr[: bs + 1]
custom_mask = None
## end_forward 接口已被废弃,可以忽略
wrapper_paged.end_forward()
## begin_forward == plan接口
wrapper_paged.begin_forward(
qo_indptr,
kv_indptr,
kv_indices,
self.kv_last_page_len[:bs],
self.num_qo_heads,
self.num_kv_heads,
self.head_dim,
1,
q_data_type=self.q_data_type,
custom_mask=custom_mask,
)begin forward 稍后分析,我们先看看create_flashinfer_kv_indices_triton,首先这是一个并行执行的函数,依赖triton的jit 。上述我们看到了调用方的调用代码,注意[bs,] 这个部分,这表明在0轴上起了bs 个triton 内核执行该函数,bs的并行度 最终体现在函数内,就是tl.program_id(axis=0)的返回值,该返回值为[0, bs-1],所以以下其实是对入参数组的并行访问。
@triton.jitdefcreate_flashinfer_kv_indices_triton(
req_to_token_ptr,# [max_batch, max_context_len]
req_pool_indices_ptr,
page_kernel_lens_ptr,
kv_indptr,
kv_start_idx,
kv_indices_ptr,
req_to_token_ptr_stride:tl.constexpr,):
BLOCK_SIZE:tl.constexpr=512
pid=tl.program_id(axis=0)
# batch 中第N个请求的req_pool_index和kv_indices_offset
req_pool_index=tl.load(req_pool_indices_ptr+pid)
kv_indices_offset=tl.load(kv_indptr+pid)
kv_start=0
kv_end=0
ifkv_start_idx:
kv_start=tl.load(kv_start_idx+pid).to(tl.int32)
kv_end=kv_start
## 获得请求的kvcache 长度
kv_end+=tl.load(page_kernel_lens_ptr+pid).to(tl.int32)
num_loop=tl.cdiv(kv_end-kv_start,BLOCK_SIZE)
foriinrange(num_loop):
# block_size 又是一个并行度,意在加速load,store的并行效率
# offset 返回的是一个BLOCK_SIZE 维度的array
offset=tl.arange(0,BLOCK_SIZE)+i*BLOCK_SIZE
mask=offset<kv_end-kv_start
# 并行读取req_to_token pool 中req 对应的token 索引
data=tl.load(
req_to_token_ptr
+req_pool_index*req_to_token_ptr_stride
+kv_start
+offset,
mask=mask,
)
## 并行写入kv indices数组
## 注意,这里kv_indices是临时结构,和token_to_kv_pool 没有关系,但最终会作为wrapper的入参
tl.store(kv_indices_ptr+kv_indices_offset+offset,data,mask=mask)backend CacheModule 是什么
在理解wrapper->plan 的调用链之前,我们先看看wrapper 里的核心结构————cache module。
具体上说,cache module 就是wrapper 真正的核心,是cpp 入口结构。它是被延后初始化的,因为主要是接口抽象类,不是实际资源,所以延后初始化也可以接受。cache module 被构建的时机是plan 接口调用时,根据backend的值和硬件当前情况,再次进行一次backend的判定,并根据backend的判定情况获取相应的cache module和挂载相应的具体接口。
首先是判断要不要使用flashattention3.
if self._backend == "auto":
self._backend = determine_attention_backend(
self.device,
PosEncodingMode[pos_encoding_mode].value,
use_fp16_qk_reduction,
self._custom_mask_buf is not None, # use_custom_mask
q_data_type,
kv_data_type,
)当前的flahinfer 对fa3的支持不太好,比如fp8就不支持。当前flashinfer 仅在如下条件都满足的情况下才会使用fa3.
H系列的硬件,cuda 版本大于12.3,不使用fp8(q和kv),不使用query/key的reduction随后获得真正执行的cache module。
get_module_args = (
q_data_type,
kv_data_type,
q_data_type,
kv_indptr.dtype,
head_dim_qk,
head_dim_vo,
PosEncodingMode[pos_encoding_mode].value,
window_left >= 0, # use_sliding_window
logits_soft_cap > 0, # use_logits_soft_cap
use_fp16_qk_reduction,
)
self._cached_module = get_batch_prefill_module(self._backend)(
*get_module_args
)由于flashinfer 还允许用户自定义实现接口和JIT,所以get_batch_prefill_module比较复杂,为了简化分析,我们只看AOT的情况(ahead-of-time compiling,也就是非JIT的情况),AOT下用的是默认已经编译好的接口,AOT的相关框架逻辑也比较复杂,如果感兴趣,可以自行阅读setup.py(https://github.com/flashinfer-ai/flashinfer/blob/95691060444252bc48c7338e9fe629e8c2fd4343/setup.py),这里可以看到AOT的prebuilt ops 相关的逻辑。但简而言之,我们只需要拿来用就可以了。_kernels 是一个内部生成的torch extention,具体逻辑我们先忽略,如下我们可以看到根据不同的backend,选择了不同的function 接口。
####def get_batch_prefill_module(backend)
if backend == "fa2":
from . import _kernels
plan_func = _kernels.batch_prefill_with_kv_cache_plan
ragged_run_func = _kernels.batch_prefill_with_ragged_kv_cache_run
paged_run_func = _kernels.batch_prefill_with_paged_kv_cache_run
else:
from . import _kernels_sm90
plan_func = _kernels_sm90.batch_prefill_with_kv_cache_sm90_plan
ragged_run_func = (
_kernels_sm90.batch_prefill_with_ragged_kv_cache_sm90_run
)
paged_run_func = (
_kernels_sm90.batch_prefill_with_paged_kv_cache_sm90_run
)随后这些接口会被注入到模块里,并返回给wrapper。如果大家真的阅读这部分代码,还会观察到一些中间接口的注册逻辑,但是由于和主功能无关,我们这里就不说明了,为了篇幅考虑。
##def get_batch_prefill_module(backend)
modules_dict[args] = SimpleNamespace(
plan=plan_func,
ragged_run=ragged_run,
paged_run=paged_run,
)
return modules_dict[args]此时,我们真正获得了prefill的模块接口函数。
wrapper->plan的调用链分析
一切数据准备好了,现在可以进行真正的plan了。plan 接口的参数很多,但实际用到的不多,我们以实际用到的进行分析。
def plan(
self,
qo_indptr: torch.Tensor, # 每一个请求输出的起始位置的数组
paged_kv_indptr: torch.Tensor, # 下面三个就是每个请求对应token kv cache的稀疏表达
paged_kv_indices: torch.Tensor,
paged_kv_last_page_len: torch.Tensor,
num_qo_heads: int, # attention 里有几个query head,kv head
num_kv_heads: int,
head_dim_qk: int, # 每个head的dim
page_size: int, # 每个page 包含几个token,实际上sglang 都只传过1
causal: bool = False, # 是否使用causal mask,默认不使用
use_fp16_qk_reduction: bool = False, # 是否裁剪qk 维度,默认不使用
window_left: int = -1, # 如果是window attention,则需要设置,-1 说明是full attention
logits_soft_cap, # 控制注意力机制中的 logits 值的上限,部分模型会用比如gemni,grok, 默认设置0
q_data_type: Union[str, torch.dtype] = "float16", # query的数据类型,默认是fp16
non_blocking: bool = False): # 是否采用非阻塞形式,默认不使用主要几个参数,是从上游传下来的,可能有读者会疑惑,比如head_dim 为什么只有qk,vo的呢?以及data_type,这里其实接口也允许传,但是如果接口不提供,会对齐到qk的值,如下。
q_data_type = canonicalize_torch_dtype(q_data_type)
if kv_data_type is None:
kv_data_type = q_data_type
kv_data_type = canonicalize_torch_dtype(kv_data_type)
if head_dim_vo is None:
head_dim_vo = head_dim_qk随后,需要准备一些中间数据结构,主要作用是赋值,从接口参数到wrapper内部成员参数。
batch_size = len(qo_indptr) - 1
# NOTE(Zihao): only required if qo_indptr/paged_kv_indptr are device tensors
qo_indptr_host = qo_indptr.to("cpu")
paged_kv_indptr_host = paged_kv_indptr.to("cpu")
paged_kv_last_page_len_host = paged_kv_last_page_len.to("cpu")
kv_lens_arr_host = get_seq_lens(
paged_kv_indptr_host, paged_kv_last_page_len_host, page_size
)
self._kv_lens_buffer[: len(kv_lens_arr_host)].copy_(
kv_lens_arr_host, non_blocking=non_blocking
)
total_num_rows = qo_indptr_host[-1]
self._qo_indptr_buf = qo_indptr.to(self.device, non_blocking=non_blocking)
self._paged_kv_indptr_buf = paged_kv_indptr.to(
self.device, non_blocking=non_blocking
)
self._paged_kv_indices_buf = paged_kv_indices.to(
self.device, non_blocking=non_blocking
)
self._paged_kv_last_page_len_buf = paged_kv_last_page_len.to(
self.device, non_blocking=non_blocking
)
self._cached_q_data_type = q_data_type
self._cached_kv_data_type = kv_data_type再接下来是获取当前具体应该调用的后端模块,也就是cache_module,其初始化逻辑可看上文对cache_module的介绍。
获得cache module后,也就获得了核心接口(比如plan,run等等),现在我们可以调用plan 接口了。调用链如下(我们选择flashattention2), 具体接口函数实现大家可以自己看,主要是功能逻辑。
_kernels.batch_prefill_with_kv_cache_plan(py)->
BatchPrefillWithKVCachePlan(cu)->
PrefillPlan这里的核心在于PrefillPlan 这个函数,BatchPrefillWithKVCachePlan只是外部包了一层接口。大体逻辑如下, 所以核心在于PrefillPlan 这个函数,核心数据结构是plan_info。
PrefillPlanInfo plan_info;
cudaError_t status = PrefillPlan<IdType>(...., plan_info, ...)
return plan_info.ToVector()planinfo 是将forward batch的配置信息进行tiling 化,从一个请求维度的数组,变出CTA 维度的数组的过程,这个数据结构本身我们上面已经说明过了。所以我们直接看PrefillPlan 即可。为了简化逻辑,以下只展示最核心的代码。
### 1. 获得硬件配置
int num_sm = 0;
int dev_id = 0;
FLASHINFER_CUDA_CALL(cudaGetDevice(&dev_id));
FLASHINFER_CUDA_CALL(cudaDeviceGetAttribute(&num_sm, cudaDevAttrMultiProcessorCount, dev_id));
int num_blocks_per_sm = 2;
int max_grid_size = num_blocks_per_sm * num_sm;
## 注意这里的max_batch_size_if_split 即指如果进行tile,可以有多少batch
## 比如hopper 有144个sm,则 max_grid_size 为288,kv heads 如果有64个,则prefill 在CTA的batch 最多为4
## 依旧注意这是prefill 的max batch,decode 并不相同
## 从此我们可以看到prefill的batch-size 支持在flashinfer 这里也是比较小的
uint32_t max_batch_size_if_split = max_grid_size / num_kv_heads;
### 2. 进行tiling,获得当前batch 要求下,推理侧CTA 最优的配置
### 这里的new_batch_size 就是tiling 化后的batchsize大小,new_batch_size >= batch_size
auto [split_kv, new_batch_size, padded_batch_size, cta_tile_q, kv_chunk_size, request_indices_vec,
qo_tile_indices_vec, kv_tile_indices_vec, merge_indptr_vec, o_indptr_vec] =
PrefillSplitQOKVIndptr(qo_indptr_h, kv_indptr_h, total_num_rows, batch_size, num_qo_heads,
num_kv_heads, head_dim_vo, page_size, max_batch_size_if_split,
enable_cuda_graph);
### 3. 把配置写入plan info,或者通过plan info 可访问,以及copy到paged_lock_int_buffer(host buffer)中
// 这里一堆赋值
### 4. 把host buffer里的配置信息,copy到device buffer使gpu 可见
size_t num_bytes_to_copy = int_allocator.num_allocated_bytes();
FLASHINFER_CUDA_CALL(cudaMemcpyAsync(int_buffer, page_locked_int_buffer, num_bytes_to_copy,
cudaMemcpyHostToDevice, stream));由于tiling 是一个相对重要的过程,所以我们这里也展示一下PrefillSplitQOKVIndptr的核心逻辑。
## 获得一些配置参数,比如gqa_group_size,用于展开以对齐计算量
const uint32_t gqa_group_size = num_qo_heads / num_kv_heads;
## 由于sglang 使用 pagesize 恒为1,所以可以理解为就是min_kv_chunk_size = 128
const uint32_t min_kv_chunk_size = std::max((128 / page_size), 1U);
## 对齐计算量, 注意这里packed_qo_len_arr的维度是请求维度
## 之所以乘gqa_group_size,是由于每个kv header 面对的query 长度是原本长度的gqa_group_size倍
std::vector<int64_t> packed_qo_len_arr(batch_size), kv_len_arr(batch_size);
for (uint32_t i = 0; i < batch_size; ++i) {
packed_qo_len_arr[i] = int64_t(qo_indptr_h[i + 1] - qo_indptr_h[i]) * int64_t(gqa_group_size);
kv_len_arr[i] = int64_t(kv_indptr_h[i + 1] - kv_indptr_h[i]);
}
#### 根据query len 进行tile(注意这里是非cuda graph的实现)
# 获取需要计算的总tokens 数量
int64_t sum_packed_qo_len = 0;
for (uint32_t i = 0; i < batch_size; ++i) {
sum_packed_qo_len += packed_qo_len_arr[i];
}
# 获得平均每请求计算token 计算量
const int64_t avg_packed_qo_len = sum_packed_qo_len / batch_size;
# 获得一个tile 合适处理的计算量,这里FA2DetermineCtaTileQ里的策略感觉是根据经验选的tile
cta_tile_q = FA2DetermineCtaTileQ(avg_packed_qo_len, head_dim);
# 计算总共需要多少tile
total_num_tiles_q = 0;
for (uint32_t i = 0; i < batch_size; ++i) {
total_num_tiles_q += ceil_div(packed_qo_len_arr[i], cta_tile_q);
}
## 寻找合适kv chunk size
## 其实也是tiling 过程,综合考虑kv len的tiling 过程
# 举例1:如果我们只有一个请求,batchsize 为1,假设请求长度1000,kv_head 64,head_dim 128
# 此时cta_tile_q = 128,min_kv_chunk_size=128,max_batch_size_if_split=4
# 不考虑cuda graph,要求最终batchsize(tiles_q * tiles_kv) < max_batch_size_if_split,
# 由于请求长度较长,tiles_q 都已经超过了4(1000/128),所以不能对kv做chunk,split_kv为false,kv_chunk_size为1000
# 举例2: 如果其他不变,请求只有256,则kv_chunk_size 可以为128。
# 另外,以上都是不开cudagraph的例子,如果打开了cudagraph,则可能在例子1 下依旧做kv cache的tiling
auto [split_kv, kv_chunk_size] =
PrefillBinarySearchKVChunkSize(enable_cuda_graph, max_batch_size_if_split, packed_qo_len_arr,
kv_len_arr, cta_tile_q, min_kv_chunk_size);
## 根据tiling的参数,重构配置信息的相关数组
## 以下核心数据结构的含义在planinfo 有过说明,可以自行脑补,核心逻辑是将请求维度的数组变出CTA维度的数组
## 最后这些核心数组都会返回,成为planinfo的一部分
uint32_t new_batch_size = 0;
for (uint32_t request_idx = 0; request_idx < batch_size; ++request_idx) {
const int64_t packed_qo_len = packed_qo_len_arr[request_idx];
const int64_t kv_len = std::max(int(kv_len_arr[request_idx]), 1);
const int64_t num_tiles_q = ceil_div(packed_qo_len, cta_tile_q);
const int64_t num_tiles_kv = ceil_div(kv_len, kv_chunk_size);
for (uint32_t q_tile_idx = 0; q_tile_idx < num_tiles_q; ++q_tile_idx) {
for (uint32_t kv_tile_idx = 0; kv_tile_idx < num_tiles_kv; ++kv_tile_idx) {
new_batch_size += 1;
request_indices.push_back(request_idx);
qo_tile_indices.push_back(q_tile_idx);
kv_tile_indices.push_back(kv_tile_idx);
}
}
int64_t qo_len = packed_qo_len / gqa_group_size;
for (uint32_t row = 0; row < qo_len; ++row) {
merge_indptr.push_back(merge_indptr.back() + num_tiles_kv);
}
o_indptr.push_back(o_indptr.back() + qo_len * num_tiles_kv);
}forward 整体过程说明
ok,我们终于来到了forward 过程(不容易啊不容易),现在只需要等model forward 过程中根据不同模型的情况更新完kvcache的信息,我们就可以拿着kvcache 去算logits和token了。
让我们再回头看看如下实现.
def forward_extend(self, forward_batch: ForwardBatch):
self.attn_backend.init_forward_metadata(forward_batch)
if self.is_generation:
if forward_batch.input_embeds is None:
return self.model.forward(
forward_batch.input_ids, forward_batch.positions, forward_batch
)先前说过,forward的过程是先init_forward_metadata ,然后后forward。但我们还需注意到init_forward_metadata 对一次完整的模型推理而言是一次性的,model forward 也是一次性的,一次model forward包括所有layer的forward,但是只有调用model 中attention layer的forward 才会真正进入到attentionbackend 的forward。这也是为什么叫做attentionbackend的原因,换言之,flashinfer 只实现了对attention的计算,不包括mlp等layer的情况。可以通过下图理解。
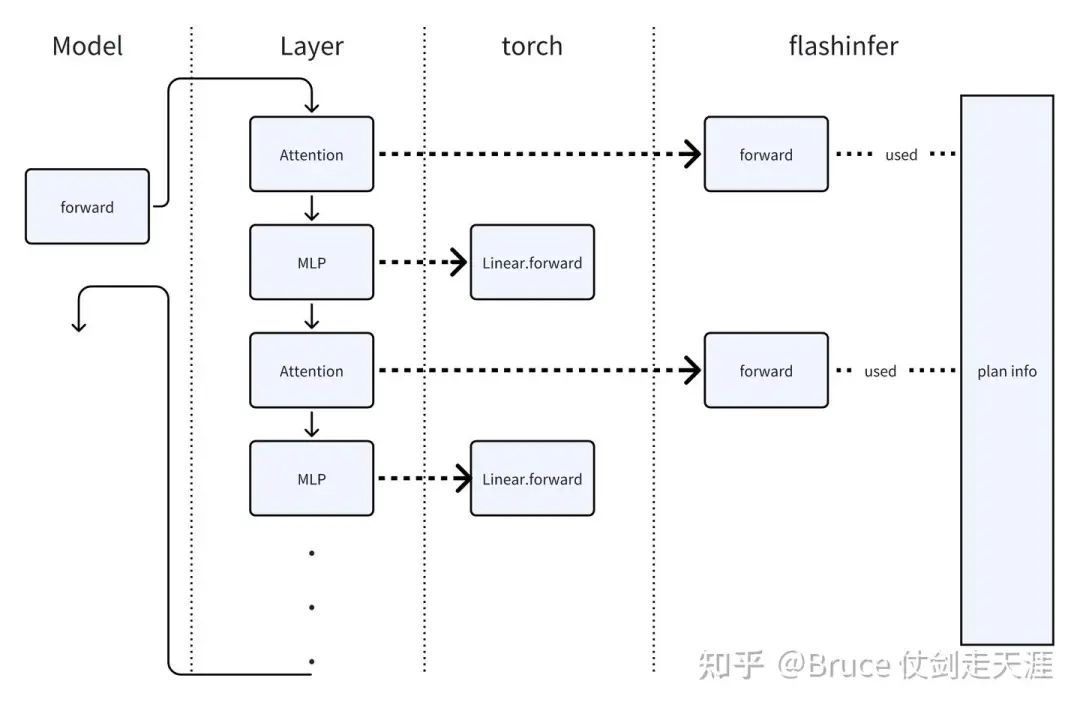
图中的planinfo 是由init_forward_metadata 过程中,由wrapper plan 获得的配置信息,作为当前batch执行的plan。
不过,有同学会问,难道sglang 只加速attention么?回答是:否。
细心的同学都会注意到sglang repo里有一个显眼的sgl-kernel的目录,这里通过torch extention的方式扩展了一些算子实现,比如RMSNorm,fused_moe 等等,而sglang的MLP 层其实默认是从这些extention的实现执行的。
https://github.com/sgl-project/sglang/blob/642ab418f31ead20c7ebd53516864bc9549d7217/sgl-kernel/csrc/torch_extension.ccl/csrc/torch_extension.cc
有兴趣的同学可以看看这里的算子,并追踪调用栈。
forward 实施细节-prefill 举例
一言不合,直接看代码。flashinfer_attentionbackend 里有外层骨架,比较清晰,简单过一下这部分。
def forward_extend(
self,
q: torch.Tensor, # query,key,value
k: torch.Tensor,
v: torch.Tensor,
layer: RadixAttention, # 必须是attention,radixAttention 是官方attention的基类
forward_batch: ForwardBatch, # forward batch 相关信息,具体字段请回顾上篇文章
save_kv_cache=True, # 默认save kv cache
):
# 首先要获得本次forward 对应处理的wrapper
# _get_wrapper_idx仅仅在encoder-decoder/sliding window架构下有用,self-attention 下直接返回0
prefill_wrapper_paged = self.forward_metadata.prefill_wrappers[
self._get_wrapper_idx(layer)
]
# 本次forward的输出token所在数组索引, if 过程可以忽略,selfattention下==forward_batch.out_cache_loc
cache_loc = (
forward_batch.out_cache_loc
if not layer.is_cross_attention
else forward_batch.encoder_out_cache_loc
)
# logits 限制
logits_soft_cap = layer.logit_cap
if not self.forward_metadata.use_ragged:
# 看有没有传kvcache, 如果model 传了kv cache,则在此设置进token_to_kv_pool
# k_scale 和 v_scale 默认为None,对cache 内容进行整除,一般不用
if k is not None:
assert v is not None
if save_kv_cache:
forward_batch.token_to_kv_pool.set_kv_buffer(
layer, cache_loc, k, v, layer.k_scale, layer.v_scale
)
# 核心环节,数据到位,准备forward,开炫, 以下传参是参考gpt2
o = prefill_wrapper_paged.forward(
q.contiguous().view(-1, layer.tp_q_head_num, layer.head_dim), # query/tp 分割后
forward_batch.token_to_kv_pool.get_kv_buffer(layer.layer_id), # kv cache
causal=not layer.is_cross_attention, # True
sm_scale=layer.scaling, # softmax 用的scaling
window_left=layer.sliding_window_size, # -1
logits_soft_cap=logits_soft_cap, # 0
k_scale=layer.k_scale, # None
v_scale=layer.v_scale, # None
)这里的forward 调用流程栈如下,挨个分析。
prefill_wrapper_paged.forward->
prefill_wrapper_paged.run->
cache_module.paged_run->
_kernels.batch_prefill_with_paged_kv_cache_run->
BatchPrefillWithPagedKVCacheRun->
BatchPrefillWithPagedKVCacheDispatchedprefill_wrapper_paged.run->BatchPrefillWithPagedKVCacheRun
这里主要是设置运行参数和检查。
### 1. 检查kvcache的数据类型和layout
k_cache, v_cache = _unpack_paged_kv_cache(paged_kv_cache, self._kv_layout)
_check_cached_qkv_data_type(
q, k_cache, self._cached_q_data_type, self._cached_kv_data_type
)
stride_block = k_cache.stride(0)
if self._kv_layout == "NHD":
page_size = k_cache.shape[1]
stride_n = k_cache.stride(1)
else:
page_size = k_cache.shape[2]
stride_n = k_cache.stride(2)
### 2. 设置默认运行参数,这部分比较冗余,我们仅写一些gpt2 下的参数
# window_left = -1
# logits_soft_cap = 0.0
# kv layout type
# self._kv_layout.value
# sm_scale = head_dim ** -0.5
# rope_scale = 1.0
# rope_theta = 1e4
# return_lse = False
## 使用casual mask
# mask_mode = MaskMode.CAUSAL.value
## kvcache的稀疏表示,fa2 运行中不会修改该表示,但是fa3 会需要修改
# sparse_indices = self._paged_kv_indices_buf
# sparse_indptr = self._paged_kv_indptr_buf
# self._qo_indptr_buf
## 输出,这里的shape 计算,其实就是softmax(q*k)*v 的结果的维度,只是简化了过程
# out = torch.empty(q.shape[:-1] + v_cache.shape[-1:], dtype=q.dtype, device=q.device)
## 以下是wrapper 内部配置
# self._float_workspace_buffer,
# self._int_workspace_buffer,
# self._plan_info,
## 以下是qkv
# q,
# k_cache,
# v_cache,
### 3. 进paged_run 跑kernel,返回输出即可
self._cached_module.paged_run(*run_args)
return out接下来是时候cpp 上场了。BatchPrefillWithPagedKVCacheRun 这个函数其实逻辑也比较接近配参数,不过这个函数里使用了很多pytorch dispatch的宏进行逻辑分派,看上去有点不太易懂(如果不太熟悉pytorch的dispatch 宏的话,比如我)。但没有关系,我们抓住核心,设置PagedParams。基本数据结构内容都在run_args和plainfo 出现过,我们只介绍未出现的字段。
struct PagedParams {
using DTypeQ = DTypeQ;
using DTypeKV = DTypeKV;
using DTypeO = DTypeO;
using IdType = IdType;
DTypeQ* q;
paged_kv_t<DTypeKV, IdType> paged_kv; #封装了kcache和vcache
IdType* q_indptr;
DTypeO* o;
float* lse;
uint_fastdiv group_size; # 即gqa group size
{{ additional_params_decl }}
uint32_t num_qo_heads; # 有多少head (h)
IdType q_stride_n; # 一个batch 包含多少size nbytes(h*d)
IdType q_stride_h; # query 一个head 包含多少dim(d)
int32_t window_left;
IdType* request_indices;
IdType* qo_tile_indices;
IdType* kv_tile_indices;
IdType* merge_indptr;
IdType* o_indptr;
bool* block_valid_mask;
IdType* kv_chunk_size_ptr;
uint32_t max_total_num_rows;
uint32_t* total_num_rows;
uint32_t padded_batch_size;
bool partition_kv; # 即split kv
}BatchPrefillWithPagedKVCacheDispatched
进入这一部分,forward 真正进入面向硬件的部分。
首先计算需要的硬件资源,包括warps和mma , 寄存器和mem。
## CTA_TILE_Q > 64 , 为2,否则为1;MMA 矩阵运算能力是16,这里64 考虑4个warps的共同处理能力
## flashinfer fa2 模板考虑4个warps
constexpr uint32_t NUM_MMA_Q = get_num_mma_q(CTA_TILE_Q);
## NUM_WARPS_Q * NUM_WARPS_KV == 4
constexpr uint32_t NUM_WARPS_Q = get_num_warps_q(CTA_TILE_Q);
constexpr uint32_t NUM_WARPS_KV = get_num_warps_kv(CTA_TILE_Q);
# 注意dim的分割,后续算子内的计算和这个相关,block 维度按batch和head 区分
# threads 内 y和z 分别指NUM_WARPS_Q和NUM_WARPS_KV的粒度
dim3 nblks(padded_batch_size, 1, num_kv_heads);
dim3 nthrs(32, NUM_WARPS_Q, NUM_WARPS_KV);
# 这里计算逻辑是NUM_MMA_x 是 HEAD_DIM_x 的1/16, 这里我理解就是mma的计算尺度一般是16*16*16
constexpr uint32_t NUM_MMA_D_QK = HEAD_DIM_QK / 16;
constexpr uint32_t NUM_MMA_D_VO = HEAD_DIM_VO / 16;
# 获得max_smem_per_sm
int dev_id = 0;
FLASHINFER_CUDA_CALL(cudaGetDevice(&dev_id));
int max_smem_per_sm = 0;
FLASHINFER_CUDA_CALL(cudaDeviceGetAttribute(&max_smem_per_sm,
cudaDevAttrMaxSharedMemoryPerMultiprocessor, dev_id));
// we expect each sm execute two threadblocks
// TODO(Zihao): fix the following computation
# 计算一个sm 可以用多少CTA(threadblocks),根据sharemem 计算
# (num_cta_per_sm * (num_warps_q + nums_warps_kv)) * HEAD_DIM_QK * sizeof(DTypeQ) * MMA_SIZE)
const int num_ctas_per_sm = max_smem_per_sm > (16 * HEAD_DIM_QK * sizeof(DTypeQ) * 16) ? 2 : 1;
# 一个threadblock 需要多少sharemem
const int max_smem_per_threadblock = max_smem_per_sm / num_ctas_per_sm;
# 根据reg 数量,计算最多可以有多少mma 用于kv
const uint32_t max_num_mma_kv_reg =
(HEAD_DIM_VO >= 128 && NUM_MMA_Q == 2 && POS_ENCODING_MODE == PosEncodingMode::kRoPELlama &&
!USE_FP16_QK_REDUCTION)
? 2
: (8 / NUM_MMA_Q);
// TODO(Zihao): fix the following computation
# 根据sharemem,计算最多可以有多少mma 用于kv
const uint32_t max_num_mma_kv_smem =
(max_smem_per_threadblock / (16 * HEAD_DIM_QK * sizeof(DTypeQ)) - NUM_MMA_Q * NUM_WARPS_Q) /
(2 * NUM_WARPS_KV);
## 双重约束 获得最终用于kv的mma数量
NUM_MMA_KV = min(max_num_mma_kv_smem, max_num_mma_kv_reg)硬件参数获得后,抽象成一个数据结构(使用cpp 模板生产)KernelTraits,这名字很直接(cuda kernel 需要用的硬件traits)。并根据计算结果,设置cudakernel 运行过程中可用空间。
using KTraits = KernelTraits<MASK_MODE, CTA_TILE_Q, NUM_MMA_Q, NUM_MMA_KV, NUM_MMA_D_QK, NUM_MMA_D_VO,
NUM_WARPS_Q, NUM_WARPS_KV, POS_ENCODING_MODE, DTypeQ, DTypeKV, DTypeO,
DTypeQKAccum, typename Params::IdType, AttentionVariant>;
# 根据计算得到需要sharemem,设置kernel 可用mem 空间
size_t smem_size = sizeof(typename KTraits::SharedStorage);
auto kernel = BatchPrefillWithPagedKVCacheKernel<KTraits, Params>;
FLASHINFER_CUDA_CALL(
cudaFuncSetAttribute(kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_size));kernel launch ,为了简化篇幅,我们采用最简单的逻辑,不考虑spliting kv的情况。
# 直接launch 就好,参数先前我都介绍过了
if (tmp_v == nullptr) {
// do not partition kv
params.partition_kv = false;
void* args[] = {(void*)¶ms};
FLASHINFER_CUDA_CALL(
cudaLaunchKernel((void*)kernel, nblks, nthrs, args, smem_size, stream));
}最后稍微介绍一下kernelTraits 这个结构,这其实是一个cpp 模版,根据传参生成结构。大部分都是模版参数直接赋值,但其中有个子结构SharedStorage,我们需要稍微说明一下,会涉及后续的一些sharemem计算。
//shareStorage 本身也是模版函数过来的结构,调用如下
//其中CTA_TILE_KV = NUM_MMA_KV * NUM_WARPS_KV * 16 ,该过程在KernelTraits的模版函数中
using SharedStorage = SharedStorageQKVO<NUM_WARPS_KV, CTA_TILE_Q, CTA_TILE_KV, HEAD_DIM_QK,
HEAD_DIM_VO, DTypeQ, DTypeKV, DTypeO>;
=====================================模版函数如下========================
// 这里是个union,不过我们的场景只需要考虑第一个struct。
template <uint32_t NUM_WARPS_KV, uint32_t CTA_TILE_Q, uint32_t CTA_TILE_KV, uint32_t HEAD_DIM_QK,
uint32_t HEAD_DIM_VO, typename DTypeQ, typename DTypeKV, typename DTypeO>
struct SharedStorageQKVO {
union {
struct {
alignas(16) DTypeQ q_smem[CTA_TILE_Q * HEAD_DIM_QK];
alignas(16) DTypeKV k_smem[CTA_TILE_KV * HEAD_DIM_QK];
alignas(16) DTypeKV v_smem[CTA_TILE_KV * HEAD_DIM_VO];
};
struct { // NOTE(Zihao): synchronize attention states across warps
alignas(
16) std::conditional_t<NUM_WARPS_KV == 1, float[1],
float[NUM_WARPS_KV * CTA_TILE_Q * HEAD_DIM_VO]> cta_sync_o_smem;
alignas(16) std::conditional_t<NUM_WARPS_KV == 1, float2[1],
float2[NUM_WARPS_KV * CTA_TILE_Q]> cta_sync_md_smem;
};
alignas(16) DTypeO smem_o[CTA_TILE_Q * HEAD_DIM_VO];
};
};
=============== 还有一个相关结构是smem_t============================================
该结构我们无需贴代码,大家只需要知道这个结构存在的意义是为了抽象对sharemem的读写行为,并进行加速
上述结构关心的是资源分配的问题,smem_t 结构关心的是读写效率问题
=============== 最后是有关layout的管理==========================================
static constexpr SwizzleMode SWIZZLE_MODE_Q = SwizzleMode::k128B;
static constexpr SwizzleMode SWIZZLE_MODE_KV =
(sizeof(DTypeKV_) == 1 && HEAD_DIM_VO == 64) ? SwizzleMode::k64B : SwizzleMode::k128B;
static constexpr uint32_t KV_THR_LAYOUT_ROW = SWIZZLE_MODE_KV == SwizzleMode::k128B ? 4 : 8;
static constexpr uint32_t KV_THR_LAYOUT_COL = SWIZZLE_MODE_KV == SwizzleMode::k128B ? 8 : 4;BatchPrefillWithPagedKVCacheKernel
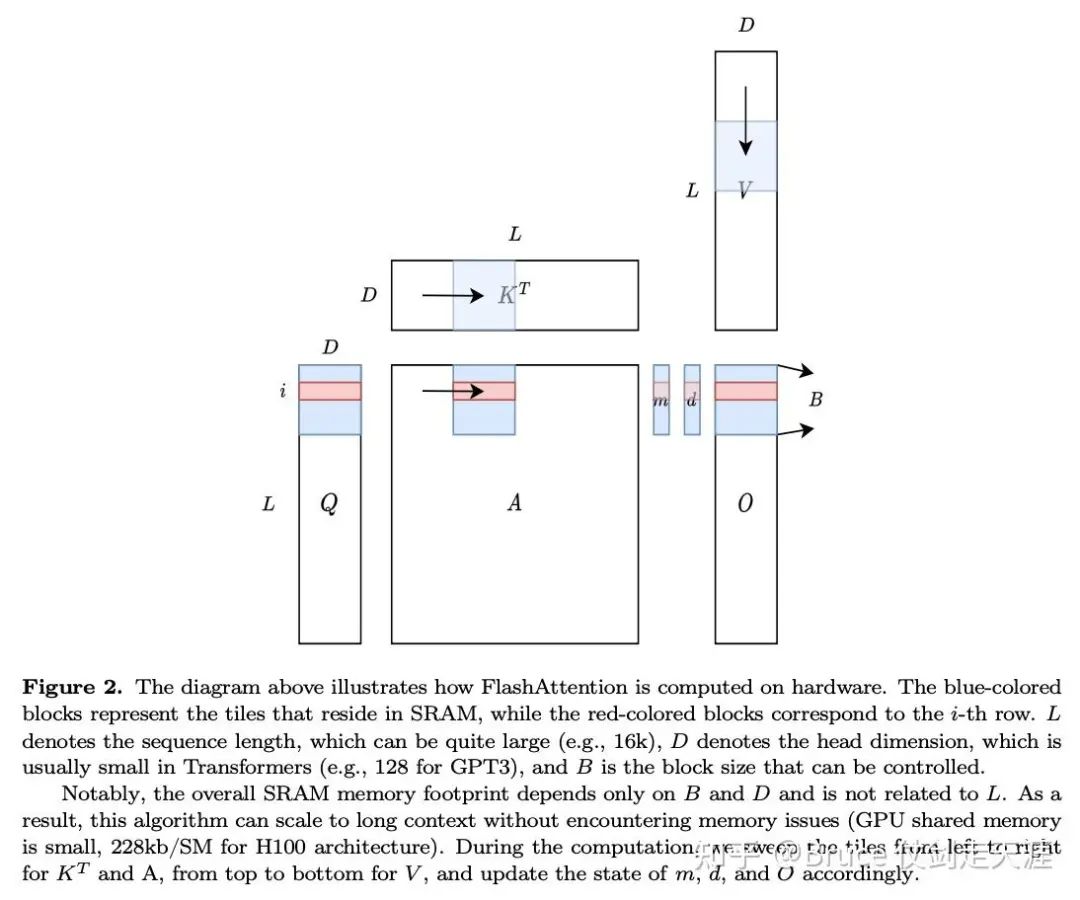
最后,我们一起看看kernel的实现吧。相关源码比较多(1000行+),为了简化,我们依旧抠核心逻辑。
在此前我推荐一下 DefTruth:[Attention优化][2w字] 原理篇: 从Online-Softmax到FlashAttention V1/V2/V3(https://zhuanlan.zhihu.com/p/668888063) 和 zihao 的 http
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
/courses/cse599m/23sp/notes/flashattn.pdf。
auto block = cg::this_thread_block();
const uint32_t kv_chunk_size = *(params.kv_chunk_size_ptr);
// 理解了上面block 和 thread dim的划分,我们应该可以比较容易理解这一部分,bx即batchidx
const uint32_t bx = blockIdx.x, lane_idx = threadIdx.x, warp_idx = get_warp_idx<KTraits>(),
kv_head_idx = blockIdx.z;
// group_size 即 gqa 参数
const uint32_t num_kv_heads = gridDim.z, num_qo_heads = group_size * num_kv_heads;
const uint32_t request_idx = request_indices[bx], qo_tile_idx = qo_tile_indices[bx],
kv_tile_idx = kv_tile_indices[bx];
// 上述可以理解为获取入参
extern __shared__ uint8_t smem[];
auto& smem_storage = reinterpret_cast<typename KTraits::SharedStorage&>(smem);
// 可以忽略这个变量,基本就是params的copy,只是方便管理罢了
AttentionVariant variant(params, /*batch_idx=*/request_idx, smem);
// 下面是几个关键的中间变量
// s_frag存储softmax(q*k) 的结果,o_frag 存储 s*v的结果,m与d见图,属于online-softmax 计算的中间结果
DTypeQKAccum s_frag[NUM_MMA_Q][NUM_MMA_KV][8];
alignas(16) float o_frag[NUM_MMA_Q][NUM_MMA_D_VO][8];
DTypeQKAccum m[NUM_MMA_Q][2];
float d[NUM_MMA_Q][2];
float rope_freq[NUM_MMA_D_QK / 2][4];
# 上述数组的前一维度比较好理解,后一维度与mma layout 相关(不过我还没理解完这部分意思)
init_states<KTraits>(variant, o_frag, m, d);
//加载query 数据从global mem to sharemem
smem_t<SWIZZLE_MODE_Q> qo_smem(smem_storage.q_smem);
load_q_global_smem<KTraits>(qo_packed_idx_base, qo_len, q_ptr_base, q_stride_n, q_stride_h,
group_size, &qo_smem);
// load_q_global_smem 内load 操作也是调用cp 命令操作的,所以这里可以调用commit_group进行管理
cp_async::commit_group();
// 实例化k v sharemem
smem_t<SWIZZLE_MODE_KV> k_smem(smem_storage.k_smem), v_smem(smem_storage.v_smem);
// 加载kv 数据从global mem到sharemem
page_produce_kv<false, KTraits>(k_smem, &k_smem_offset_w, paged_kv, 0, thr_local_kv_offset,
chunk_size);
cp_async::commit_group();
page_produce_kv<true, KTraits>(v_smem, &v_smem_offset_w, paged_kv, 0, thr_local_kv_offset,
chunk_size);
cp_async::commit_group();
// 进行计算
#pragma unroll 1
for (uint32_t iter = 0; iter < num_iterations; ++iter) {
packed_page_iter_base += CTA_TILE_KV;
// 进行计算前,确保qk数据到位,v 可以不加载完(qk 不需要v)
// wait_group 1 指可以有一个挂起,最近挂起的v可以不完成
cp_async::wait_group<1>();
block.sync();
// compute attention score
compute_qk<KTraits>(&qo_smem, &q_smem_offset_r, &k_smem, &k_smem_offset_r, s_frag);
// logits transform,比如先前的logits soft cap 限制,应用一下
logits_transform<KTraits>(
params, variant, /*batch_idx=*/request_idx, qo_packed_idx_base,
chunk_start + (iter * NUM_WARPS_KV + get_warp_idx_kv<KTraits>()) * NUM_MMA_KV * 16,
qo_len, kv_len, group_size, s_frag);
// compute m,d states in online softmax
update_mdo_states<KTraits>(variant, s_frag, o_frag, m, d);
// 块内同步
block.sync();
// 这一批的k 用完了,提前加载下一批的k,注意要在qk 计算确认完成后执行
page_produce_kv<false, KTraits>(k_smem, &k_smem_offset_w, paged_kv, (iter + 1) * CTA_TILE_KV,
thr_local_kv_offset, chunk_size);
cp_async::commit_group();
// 这里其实等的是v,因为wait group 1允许有一个挂起,刚刚挂起k,所以v 被等待完成
cp_async::wait_group<1>();
block.sync();
// compute sfm*v,计算output
compute_sfm_v<KTraits>(&v_smem, &v_smem_offset_r, s_frag, o_frag, d);
block.sync();
// 块内同步完成,为下一个iterate 加载v 数据
page_produce_kv<true, KTraits>(v_smem, &v_smem_offset_w, paged_kv, (iter + 1) * CTA_TILE_KV,
thr_local_kv_offset, chunk_size);
cp_async::commit_group();
}
// 确保所有挂起逻辑完成数据同步
cp_async::wait_group<0>();
// 块内同步
block.sync();
finalize_m<KTraits>(variant, m);
// threadblock synchronization
threadblock_sync_mdo_states<KTraits>(o_frag, &smem_storage, m, d, warp_idx, lane_idx);
// normalize d,这一步使用d 进行o的归一处理
normalize_d<KTraits>(o_frag, m, d);
const uint32_t num_kv_chunks = (kv_len_safe + kv_chunk_size - 1) / kv_chunk_size;
// write_back,将计算结果写回global mem
write_o_reg_gmem<KTraits>(o_frag, &qo_smem, o_ptr_base, qo_packed_idx_base, qo_len,
/*o_stride_n=*/
partition_kv ? num_kv_chunks * o_stride_n : o_stride_n,
/*o_stride_h=*/o_stride_h, group_size);上面这部分逻辑我们只抠了主体代码,其实省略了许多index 的计算细节,这些细节本身也是加速的关键,但奈何笔者理解能力有限,以及flashinfer的注释有些不足,尚不能完全理解,后面理解了再单独完整讲一篇kernel并行计算优化吧。
decode 的 forward 行为-与prefill 行为的辨析
先前我们已经完整过完了flashinfer Prefill 在fa2下的主体代码。 接下来我们比较一下decode 与prefill的差异。
decode 也有自己decodeWrapper,自然也有初始化,plan 和run的接口。
初始化逻辑基本是一致的,只不过少了q相关的字段,以及decode 会考虑不用tensor-core的可能性(should_use_tensor_core)。在sglang侧和flashinfer 的python层都没有特别值得注意的行为。但当我们去看cpp kernel 接口的实现,我们会看到一些不同。
nums_stage_smem
首先我们会经常看到一个变量名 nums_stage_smem。
work estimation
decode plan 的过程与其他几乎一样,也只是少了query 相关的信息。但多了一步work estimation,以评估即将运行的kernel 函数所占用的资源情况。
FLASHINFER_CUDA_CALL(work_estimation_func(split_kv, max_grid_size, kv_chunk_size_in_pages,
new_batch_size, gdy, batch_size, indptr_h, num_qo_heads,
page_size, enable_cuda_graph, stream));这里的评估的结果主要影响split_kv, max_grid_size, kv_chunk_size_in_pages, new_batch_size,对decode batch的编排影响也比较大。其实这里的部分逻辑类似于prefill的PrefillSplitQOKVIndptr,decode 虽然也有DecodeSplitQOKVIndptr ,但实现不同,寻找最佳kvchunk size和batch_size的动作放在了work_estimation_func里。
我们简单过一下代码,首先是选择合适的tiling 依据。prefill的tiling 过程中query len是一个重要考虑,但是decode 这边query len为1,此时由于tiling的维度就仅仅包括kv len,另外也混入了head dim层切割。
constexpr uint32_t vec_size = std::max(16UL / sizeof(DTypeKV), HEAD_DIM / 32UL);
constexpr uint32_t bdx = HEAD_DIM / vec_size; // 从这里可以看到tile 的依据来自对head_dim的切割
static_assert(bdx <= 32);
constexpr uint32_t bdy = GROUP_SIZE;
constexpr uint32_t num_threads = std::max(128U, bdx * bdy);
constexpr uint32_t bdz = num_threads / (bdx * bdy);
constexpr uint32_t tile_size_per_bdx = GROUP_SIZE == 1 ? (sizeof(DTypeKV) == 1 ? 2U : 4U) : 1U;
const uint32_t num_kv_heads = num_qo_heads / GROUP_SIZE;然后是计算可能需要的sharemem 数量
gdy = num_kv_heads;
const uint32_t smem_size =
2 * NUM_STAGES_SMEM * tile_size_per_bdx * bdy * bdz * HEAD_DIM * sizeof(DTypeKV) +
std::max(tile_size_per_bdx * num_threads * sizeof(DTypeKV*), 2 * bdy * bdz * sizeof(float));
auto kernel =
BatchDecodeWithPagedKVCacheKernel<POS_ENCODING_MODE, NUM_STAGES_SMEM, tile_size_per_bdx,
vec_size, bdx, bdy, bdz, AttentionVariant, Params>;
int num_blocks_per_sm = 0;
int num_sm = 0;
int dev_id = 0;
FLASHINFER_CUDA_CALL(cudaGetDevice(&dev_id));
FLASHINFER_CUDA_CALL(cudaDeviceGetAttribute(&num_sm, cudaDevAttrMultiProcessorCount, dev_id));
FLASHINFER_CUDA_CALL(cudaOccupancyMaxActiveBlocksPerMultiprocessor(&num_blocks_per_sm, kernel,
num_threads, smem_size));
max_grid_size = num_blocks_per_sm * num_sm;这里cudaOccupancyMaxActiveBlocksPerMultiprocessor这个接口可用于给定threads和sharemem以及kernel的情况下(也就是给定一个block需要的资源),当前在获得sm 内可以拿到几个这种block。
从flashinfer的同学那边得知, decode的模板后续可能也不再维护了,所以我们就浅尝辄止,接下来回过头来看看cudaGraph 下的工作方式。
cudaGraphRunner 下的行为
游凯超:一文读懂cudagraph(https://zhuanlan.zhihu.com/p/700224642),首先推荐一篇游凯超对于cudagraph的文章,对于cudagraph的原理说明是相当透彻的。这里我们详细介绍一下sglang的cudaGraphRunner 里的基本实现框架。这一部分其实和vllm 可能会比较类似。
初始化
其初始化结构很简单,这里最重要的就是graphs和outputbuffers,graph是cudaGraph 结构的字典(key 是batchsize),outputbuffers 是graph 字典一一对应的输出buffer 字典。
def __init__(self, model_runner: ModelRunner):
# Parse args
self.model_runner = model_runner
self.graphs = {}
self.output_buffers = {}
self.enable_torch_compile = model_runner.server_args.enable_torch_compile
self.disable_padding = model_runner.server_args.disable_cuda_graph_padding
self.is_encoder_decoder = model_runner.model_config.is_encoder_decoder
# 这部分是distributed 相关的配置,等下一篇讲分布式再来看吧)
self.enable_dp_attention = model_runner.server_args.enable_dp_attention
self.tp_size = model_runner.server_args.tp_size
self.dp_size = model_runner.server_args.dp_size
# Batch sizes to capture,这里的bs 和 graph相关,基本是硬编码和配置
# 不过这里有一个点,capture_bs 可以大于Max_running_request,为了尽量攒大一点graph的batchsize
self.capture_bs, self.compile_bs = get_batch_sizes_to_capture(model_runner)
# 这里有意思的是,sglang的cudaGraph 似乎只有decode 模式(投机推理情况下+verify)
self.capture_forward_mode = ForwardMode.DECODE
self.num_tokens_per_bs = 1
self.max_bs = max(self.capture_bs)
self.max_num_token = self.max_bs * self.num_tokens_per_bs
## init_cuda_graph_state 其实没啥,单独为cuda graph 准备了一个kv indice的数组资源
self.model_runner.attn_backend.init_cuda_graph_state(self.max_num_token)
## 这个是padding的填充值,sglang 固定用0
self.seq_len_fill_value = (
self.model_runner.attn_backend.get_cuda_graph_seq_len_fill_value()
)
# 为graph 输入开辟空间
# Graph inputs
with torch.device("cuda"):
self.input_ids = torch.zeros((self.max_num_token,), dtype=torch.int64)
self.req_pool_indices = torch.zeros((self.max_bs,), dtype=torch.int32)
self.seq_lens = torch.full(
(self.max_bs,), self.seq_len_fill_value, dtype=torch.int32
)
self.out_cache_loc = torch.zeros((self.max_num_token,), dtype=torch.int64)
self.positions = torch.zeros((self.max_num_token,), dtype=torch.int64)
self.mrope_positions = torch.zeros((3, self.max_bs), dtype=torch.int64)
# Capture
try:
with self.model_capture_mode():
self.capture()以上这段代码是cudaGraphRunner的初始化部分主体代码,不过我们稍微关注4个函数的实现,为了更好理解graphrunner的工作原理。分别如下
# 用于获取capture 的graph 总数,且每种graph的尺寸
def get_batch_sizes_to_capture(model_runner: ModelRunner):
server_args = model_runner.server_args
capture_bs = server_args.cuda_graph_bs
if capture_bs is None:
if server_args.speculative_algorithm is None:
if server_args.disable_cuda_graph_padding:
capture_bs = list(range(1, 33)) + [64, 96, 128, 160]
else:
# 默认走这个branch,也就是capture 最多160的bs,[1,2,4,8,16,24,32,40,48,,,160]
capture_bs = [1, 2, 4] + [i * 8 for i in range(1, 21)]
else:
capture_bs = list(range(1, 33))
# 大部分情况下,max_running_queue 大于capture_bs,但是在一些显存紧张的场景下
# (比如一些小gpu 或者加载权重完,没有什么显存可以留给推理kvcache的情况下)
# max_running_queue较小,此时为了更好的capture,capture_bs 最大控制到max_running_queue
if max(capture_bs) > model_runner.req_to_token_pool.size:
# In some case (e.g., with a small GPU or --max-running-requests), the #max-running-requests
# is very small. We add more values here to make sure we capture the maximum bs.
capture_bs = list(
sorted(
set(
capture_bs
+ [model_runner.req_to_token_pool.size - 1] #增加max_running_queue同宽size
+ [model_runner.req_to_token_pool.size]
)
)
)
capture_bs = [
bs
for bs in capture_bs
if bs <= model_runner.req_to_token_pool.size # 削去max_running_queue 以上的bs
and bs <= server_args.cuda_graph_max_bs # 又一重限制,不过对于显存富余的场景(大于24GB),默认160
]
# torch_compile_max_bs 默认32, 且仅在enable_torch_compile 开启时生效
compile_bs = (
[bs for bs in capture_bs if bs <= server_args.torch_compile_max_bs]
if server_args.enable_torch_compile
else []
)
return capture_bs, compile_bs如上是一个大体的cudagraph runner的初始化。接下来我们看看capture的细节。
Capture() 过程
首先我们看看graph capture的context 构造过程。
# 对外capture_graph的调用函数,注意到这里context 加了tp和pp 两层通信上组上的限制
@contextmanager
def graph_capture():
with get_tp_group().graph_capture() as context, get_pp_group().graph_capture(
context
):
yield context
@dataclass
class GraphCaptureContext:
stream: torch.cuda.Stream
# 从上述可见capture_graph 与通信组相关,我们来看看原因
class GroupCoordinator:
...
@contextmanager
def graph_capture(
self, graph_capture_context: Optional[GraphCaptureContext] = None
):
# 默认context 可传None,在上述调用中tp的context 就是创建的,pp的context 来自于tp 创建的
if graph_capture_context is None:
# 获得一个Stream
stream = torch.cuda.Stream()
# 基于Stream 构造一个GraphCaptureContext对象(如上,很简单)
graph_capture_context = GraphCaptureContext(stream)
else:
stream = graph_capture_context.stream
# 通信组的comm 对象
ca_comm = self.ca_comm
maybe_ca_context = nullcontext() if ca_comm is None else ca_comm.capture()
# ensure all initialization operations complete before attempting to
# capture the graph on another stream
# 等待当前默认stream的操作完成后,才能进入context capture的初始化
curr_stream = torch.cuda.current_stream()
if curr_stream != stream:
stream.wait_stream(curr_stream)
# 设置新stream 作为当前线程cuda的默认stream
# 如果使用graph,那么只能支持pynccl(默认nccl实现的py 接口)或者sglang custom_allreduce
with torch.cuda.stream(stream), maybe_ca_context:
# In graph mode, we have to be very careful about the collective
# operations. The current status is:
# allreduce \ Mode | Eager | Graph |
# --------------------------------------------
# custom allreduce | enabled | enabled |
# PyNccl | disabled| enabled |
# torch.distributed | enabled | disabled|
#
# Note that custom allreduce will have a runtime check, if the
# tensor size is too large, it will fallback to the next
# available option.
# In summary: When using CUDA graph, we use
# either custom all-reduce kernel or pynccl. When not using
# CUDA graph, we use either custom all-reduce kernel or
# PyTorch NCCL. We always prioritize using custom all-reduce
# kernel but fall back to PyTorch or pynccl if it is
# disabled or not supported.
pynccl_comm = self.pynccl_comm
maybe_pynccl_context: Any
if not pynccl_comm:
maybe_pynccl_context = nullcontext()
else:
maybe_pynccl_context = pynccl_comm.change_state(
enable=True, stream=torch.cuda.current_stream()
)
with maybe_pynccl_context:
yield graph_capture_context获得了graph capture的stream和context,我们可以看看capture的实现了。
def capture(self):
# 第一步获取graph的上下文
with graph_capture() as graph_capture_context:
# 获取stream和可用显存
self.stream = graph_capture_context.stream
avail_mem = get_available_gpu_memory(
self.model_runner.device, self.model_runner.gpu_id, empty_cache=False
)
# 反向遍历bs,以希望获得更好的显存共享
# Reverse the order to enable better memory sharing across cuda graphs.
capture_range = (
tqdm.tqdm(list(reversed(self.capture_bs)))
if get_tensor_model_parallel_rank() == 0
else reversed(self.capture_bs)
)
for bs in capture_range:
# 只在tp 0 上打印
if get_tensor_model_parallel_rank() == 0:
avail_mem = get_available_gpu_memory(
self.model_runner.device,
self.model_runner.gpu_id,
empty_cache=False,
)
capture_range.set_description(
f"Capturing batches ({avail_mem=:.2f} GB)"
)
# 在默认情况下,patch_model 直接返回model.forward,
# 在enable_torch_compile的情况下,返回一个torch 编译优化的版本,具体我们后续说
with patch_model(
self.model_runner.model,
bs in self.compile_bs,
num_tokens=bs * self.num_tokens_per_bs,
tp_group=self.model_runner.tp_group,
) as forward:
# 基于bs 和 forward,进行capture
(
graph,
output_buffers,
) = self.capture_one_batch_size(bs, forward)
self.graphs[bs] = graph
self.output_buffers[bs] = output_buffers
# Save gemlite cache after each capture
# 每次cuda graph capture 完,保存gemlite cache 配置,便于后续加速
save_gemlite_cache()可以看到,在初始化时,sglang 就调用过capture,所以实际上graph的构建绝大部分情况下,是初始化时期就完成了。但是在新版本的代码中,replay 过程会进行检查看是否需要重新capture,这一点我们后续看replay代码再说。继续看上述代码中的两块关键函数。
首先是patch_model,该函数返回一个model 层面的forward 接口,默认情况下返回Model 本身的forward 接口,但是sglang 支持torch compile的情况,所以也可以发挥torch 编译优化后的接口。如下是代码分析。
# 该函数是一个设置model 每一层forward的调用函数的功能,大家可以看到几个点:
# reverse True表明采用sglang保留的实现(custom kernel,forward_cuda看代码都是调用sglang自己的算子)
# 注意这里CustomOp 说明是一个sglang 内部自定义的layer,但是不一定会调用custom kernel,只是支持调用customKernel
# forward_native 就是使用torch 原生接口实现customOp,
def _to_torch(model: torch.nn.Module, reverse: bool, num_tokens: int):
for sub in model._modules.values():
if isinstance(sub, CustomOp): # 以下操作仅仅对customOp执行
if reverse:
sub._forward_method = sub.forward_cuda
setattr(sub, "is_torch_compile", False) #表明编译未完成,即如果torch.compile,可以编译
else:
# NOTE: Temporarily workaround MoE
if "FusedMoE" in sub.__class__.__name__:
if num_tokens == 1:
# The performance of torch.compile on this layer is not always good when bs > 1,
# so we decide to only use torch.compile when bs =1
sub._forward_method = fused_moe_forward_native
else:
sub._forward_method = sub.forward_native
setattr(sub, "is_torch_compile", True) #表明编译完成,即便torch.compile,也不会执行编译操作
if isinstance(sub, torch.nn.Module):
_to_torch(sub, reverse, num_tokens) # 递归嵌套处理子模块
# 默认下就是else 分支,原地返回model.forward, 我们主要介绍开启torch 编译优化下的执行逻辑
@contextmanager
def patch_model(
model: torch.nn.Module,
enable_compile: bool,
num_tokens: int,
tp_group: GroupCoordinator,
):
"""Patch the model to make it compatible with with torch.compile"""
backup_ca_comm = None
try:
if enable_compile:
# compile 前reverse=False,我理解是为了方便torch compile 优化
_to_torch(model, reverse=False, num_tokens=num_tokens)
backup_ca_comm = tp_group.ca_comm
# Use custom-allreduce here.
# We found the custom allreduce is much faster than the built-in allreduce in torch,
# even with ENABLE_INTRA_NODE_COMM=1.
# tp_group.ca_comm = None
yield torch.compile(
torch.no_grad()(model.forward), # torch.no_grad 即编译优化过程中不考虑梯度更新,因为梯度更新对推理没有用
mode="max-autotune-no-cudagraphs", #优化过程中最大程度使用自动调优,且不使用cudagraph(因为sglang 有自己的cudagraph 优化)
dynamic=False, #说明输入形状是静态的,torch 可以进行更深入的优化
)
else:
yield model.forward
finally:
if enable_compile:
# capture 完,model 重新恢复custom kernel 实现
_to_torch(model, reverse=True, num_tokens=num_tokens)
tp_group.ca_comm = backup_ca_comm
# 如下则是torch compile的设置
def set_torch_compile_config():
import torch._dynamo.config
import torch._inductor.config
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.triton.unique_kernel_names = True
torch._inductor.config.fx_graph_cache = True # Experimental feature to reduce compilation times, will be on by default in future
# FIXME: tmp workaround
torch._dynamo.config.accumulated_cache_size_limit = 1024
if hasattr(torch._dynamo.config, "cache_size_limit"):
torch._dynamo.config.cache_size_limit = 1024现在我们搞懂了capture 过程中调用的forward 接口的内容,接下来我们看看capture 过程中forwardbatch的内容组成,这一部分主要在capture_one_batch_size里。为了可读性,我们简化一下代码。
def capture_one_batch_size(self, bs: int, forward: Callable):
graph = torch.cuda.CUDAGraph() #构建cudagraph 实例, 获取stream
stream = self.stream
num_tokens = bs * self.num_tokens_per_bs #预备所需要的tokens
# Graph inputs
# 注意cudagraph 中也是类似的forwardbatch和数组,只不过都是静态的batch,无需动态生成
# 为了突出重点,我扔掉了投机推理、dp 相关的逻辑,仅仅讨论最简单情况下的流程
input_ids = self.input_ids[:num_tokens]
req_pool_indices = self.req_pool_indices[:bs]
seq_lens = self.seq_lens[:bs]
out_cache_loc = self.out_cache_loc[:num_tokens]
positions = self.positions[:num_tokens]
encoder_lens = None
mrope_positions = self.mrope_positions[:, :bs]
# forward batch 传参,和disable-cuda-graph 的区别是cuda graph下这里数组都是固定的
forward_batch = ForwardBatch(
forward_mode=self.capture_forward_mode,
batch_size=bs,
input_ids=input_ids,
req_pool_indices=req_pool_indices,
seq_lens=seq_lens,
req_to_token_pool=self.model_runner.req_to_token_pool,
token_to_kv_pool=self.model_runner.token_to_kv_pool,
attn_backend=self.model_runner.attn_backend,
out_cache_loc=out_cache_loc,
seq_lens_sum=seq_lens.sum(),
encoder_lens=encoder_lens,
return_logprob=False,
positions=positions,
global_num_tokens_gpu=global_num_tokens,
gathered_buffer=gathered_buffer,
mrope_positions=mrope_positions,
spec_algorithm=self.model_runner.spec_algorithm,
spec_info=spec_info,
capture_hidden_mode=self.capture_hidden_mode,
)
# Attention backend,在attention backend 中初始化cuda graph 信息
self.model_runner.attn_backend.init_forward_metadata_capture_cuda_graph(
bs,
num_tokens,
req_pool_indices,
seq_lens,
encoder_lens,
forward_batch.forward_mode,
forward_batch.spec_info,
)
# Run and capture, forward 参考上述patch_model的返回
def run_once():
# Clean intermediate result cache for DP attention
forward_batch.dp_local_start_pos = forward_batch.dp_local_num_tokens = None
logits_output = forward(input_ids, forward_batch.positions, forward_batch)
return logits_output.next_token_logits, logits_output.hidden_states
# 这两次run_once我没有完全理解,第一次run_once 应该是提前获取相关数据(也可以理解为warmup的一部分)
# 有些动作,比如cudaMalloc 分配显存是不允许的,而run_once 过程中会分配一些中间buffer
# 如果buffer 已经分配过了则不会再次分配
# 但第二次,我没看懂,可能是为了确保没有问题?
for _ in range(2):
torch.cuda.synchronize()
self.model_runner.tp_group.barrier()
run_once()
# 构建静态图
global global_graph_memory_pool
with torch.cuda.graph(graph, pool=global_graph_memory_pool, stream=stream):
out = run_once()
global_graph_memory_pool = graph.pool()
return graph, out这里的init_forward_metadata_capture_cuda_graph 逻辑上比较简单,也是赋值metadata而已。
在最新的代码中,在replay 过程中也按需capture,不过这和投机推理有关,让我先忽略一下。
以上我们就整理完了cudaGraph runner 初始化的代码。
Replay() 过程
cudaGraph 的replay 其实就是正式forward的过程。我们观察到cudaGraphRunner 的forward 过程如下,如果使能cudaGraph,则通过cudaGraphRunner的replay 执行。
def forward(
self, forward_batch: ForwardBatch, skip_attn_backend_init: bool = False
) -> LogitsProcessorOutput:
if (
forward_batch.forward_mode.is_cuda_graph()
and self.cuda_graph_runner
and self.cuda_graph_runner.can_run(forward_batch)
):
return self.cuda_graph_runner.replay(
forward_batch, skip_attn_backend_init=skip_attn_backend_init
)
........现在我们看看replay 接口的实现,从上述接口中传递了forward_batch。
def replay(self, forward_batch: ForwardBatch, skip_attn_backend_init: bool = False):
self.recapture_if_needed(forward_batch) # 非投机推理,基本忽略
raw_bs = forward_batch.batch_size
raw_num_token = raw_bs * self.num_tokens_per_bs
# Pad,获取raw_bs 的index
index = bisect.bisect_left(self.capture_bs, raw_bs)
bs = self.capture_bs[index]
# 如果是之前不支持的bs 类型,对系统值进行初始化,seq_len 默认1,out_cache_loc 默认0
if bs != raw_bs:
self.seq_lens.fill_(1)
self.out_cache_loc.zero_()
# Common inputs,赋值入flashinfer的数组
self.input_ids[:raw_num_token].copy_(forward_batch.input_ids)
self.req_pool_indices[:raw_bs].copy_(forward_batch.req_pool_indices)
self.seq_lens[:raw_bs].copy_(forward_batch.seq_lens)
self.out_cache_loc[:raw_num_token].copy_(forward_batch.out_cache_loc)
self.positions[:raw_num_token].copy_(forward_batch.positions)
if forward_batch.decode_seq_lens_cpu is not None:
if bs != raw_bs:
self.seq_lens_cpu.fill_(1)
self.seq_lens_cpu[:raw_bs].copy_(forward_batch.decode_seq_lens_cpu)
if self.is_encoder_decoder:
self.encoder_lens[:raw_bs].copy_(forward_batch.encoder_lens)
if forward_batch.mrope_positions is not None:
self.mrope_positions[:, :raw_bs].copy_(forward_batch.mrope_positions)
if hasattr(forward_batch.spec_info, "hidden_states"):
self.hidden_states[:raw_num_token] = forward_batch.spec_info.hidden_states
# Attention backend,这里也仅仅是再次设置metadata,主要是设置pagetable
self.model_runner.attn_backend.init_forward_metadata_replay_cuda_graph(
bs,
self.req_pool_indices,
self.seq_lens,
forward_batch.seq_lens_sum + (bs - raw_bs),
self.encoder_lens,
forward_batch.forward_mode,
forward_batch.spec_info,
seq_lens_cpu=self.seq_lens_cpu,
)
# Replay,replay 时真正launch kernel,返回output
self.graphs[bs].replay()
next_token_logits, hidden_states = self.output_buffers[bs]
# 注意这里主要做split,outputbuffer 里有完整一个bs的logits和hidden_stats
# 但是capture的bs和当前forward bs 可能不一样,所以要过滤一下
logits_output = LogitsProcessorOutput(
next_token_logits=next_token_logits[:raw_num_token],
hidden_states=(
hidden_states[:raw_num_token] if hidden_states is not None else None
),
)
return logits_output好,这里为止,我们基本介绍完了forward和backend 流程里的主要环节,希望可以帮助大家更好理解代码
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)