


为什么现有大模型看不懂图表? 当前的视觉大模型(如GPT-4.1)虽然能识别图像中的物体,但在处理复杂图表时却经常“翻车”。比如一张股票走势图,模型可能直接回答“最高点是2023年”,但实际数据需要通过坐标轴数值验证。
这种“视觉盲区”源于两大问题:
-
纯文本推理:现有模型主要依赖文字描述,缺乏对图像细节的主动操作能力(比如放大局部、画参考线)。 -
工具僵化:即使接入OCR(文字识别)等工具,调用策略也是固定的,无法根据任务动态调整。

论文:OPENTHINKIMG:Learning to Think with Images via Visual Tool Reinforcement Learning
链接:https://arxiv.org/pdf/2505.08617
github:https://github.com/zhaochen0110/OpenThinkIMG
X:https://x.com/suzhaochen0110/status/1922481570453074070?s=46

比如论文中的案例:GPT-4.1直接“目测”饼图比例出错,而OpenThinkIMG通过放大子图+OCR提取数值精准计算答案。
OpenThinkIMG:给AI装上一套“视觉工具箱”
为了解决上述问题,研究者开发了开源框架OpenThinkIMG,核心设计可以概括为:标准化工具接口+分布式部署+训练流水线。
三个亮点功能:
-
九大视觉工具:包括OCR、局部放大、画参考线、坐标定位等,覆盖图表分析的常见需求。 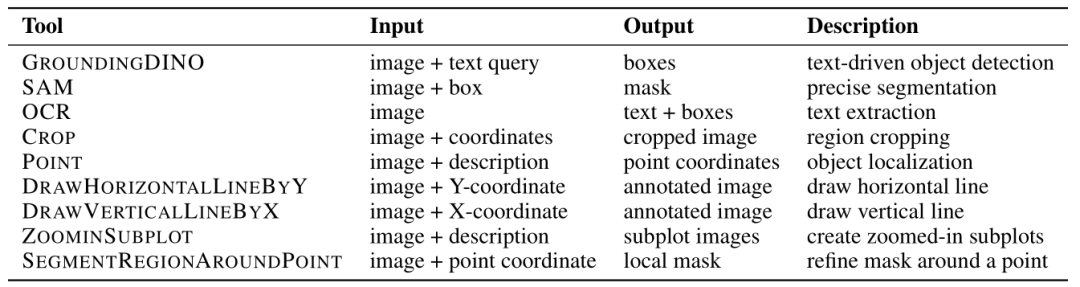
-
模块化部署:每个工具独立运行,避免“一个工具崩溃,全家罢工”。 -
训练一条龙:从工具调用轨迹生成到强化学习训练,全程自动化。
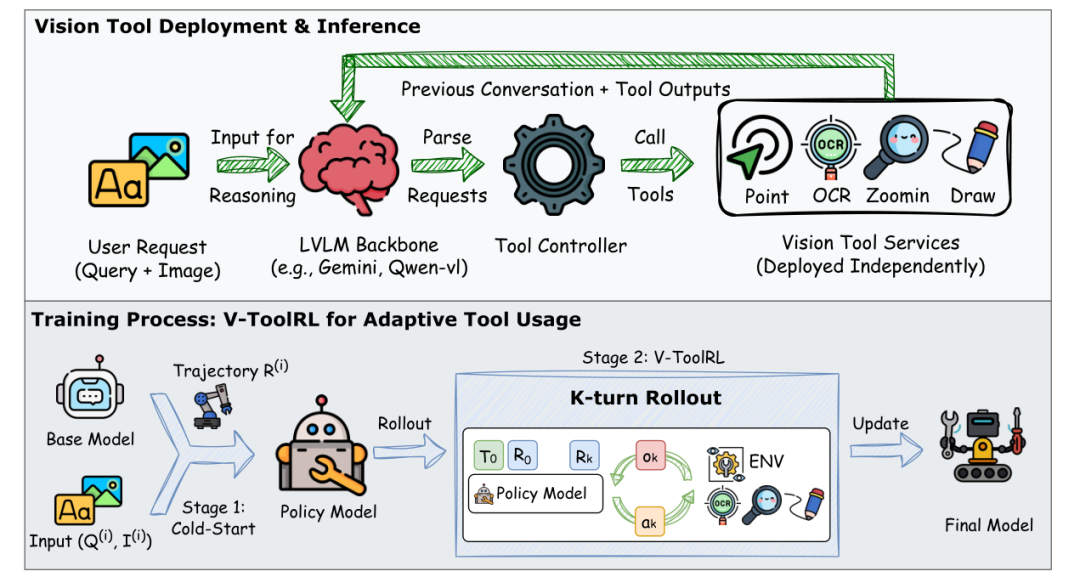 用户提问后,模型像“指挥官”一样调度工具,逐步拼接答案。例如分析折线图时,先调用OCR读数字,再画垂直线对比趋势。
用户提问后,模型像“指挥官”一样调度工具,逐步拼接答案。例如分析折线图时,先调用OCR读数字,再画垂直线对比趋势。
V-ToolRL:像人类一样“试错学习”的强化训练法
传统方法靠“模仿人类操作”训练模型(监督学习),但遇到新问题容易“死记硬背”。OpenThinkIMG的杀手锏是V-ToolRL——用强化学习让模型自主探索工具组合策略。
训练过程:
-
初级任务(监督学习):先让模型学习人类标注的“标准操作流程”,比如“先OCR再画线”。 -
进阶任务(强化学习):开始自由尝试工具组合,系统根据最终答案正确性给“奖励分”。通过不断试错,学会“用最少工具得最高分”。
论文中的数学公式显示,奖励机制简单粗暴:答案正确+1分,错误-1分。这种设计迫使模型快速收敛到高效策略。
实验结果:准确率超越GPT-4.1,工具调用效率翻倍
在图表推理任务ChartGemma测试中:
-
V-ToolRL准确率59.39% ,比GPT-4.1(50.71%)高出近9个百分点。 -
工具调用次数下降80% :训练后AI从平均每题调用0.6次工具,优化到仅需0.1。 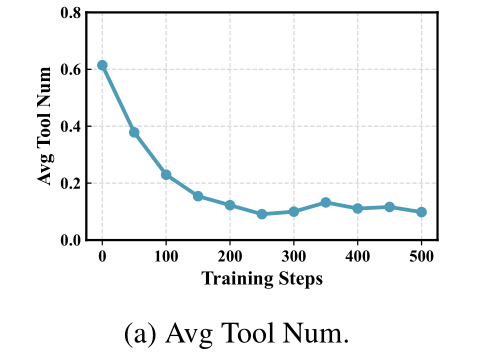
-
推理过程更详细:模型输出的思考步骤从66个单词增长到86个,解释更清晰。 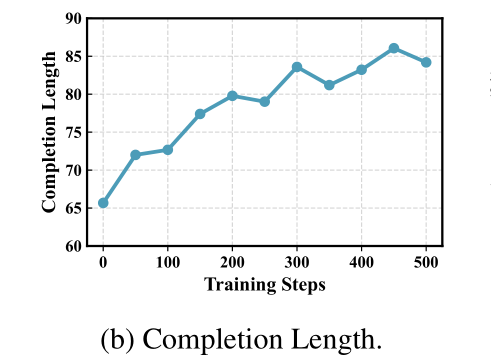

对比图中,V-ToolRL(橙色曲线)的准确率一路领先,证明强化学习能显著突破监督学习的性能天花板。
未来想象
这项技术不仅限于图表分析,研究者展望了更广阔的应用场景:
-
医疗影像:智能医生调用“病灶标注工具”辅助诊断。 -
自动驾驶:实时调用“障碍物追踪工具”优化路径规划。 -
教育:学生上传几何题,AI用“画辅助线工具”分步骤讲解。
论文最后开源了所有代码和工具库,呼吁社区共建“视觉思维”生态。
(文:机器学习算法与自然语言处理)