
General-Level团队 投稿
量子位 | 公众号 QbitAI
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。
在“如何全面客观地评测多模态大模型”这一问题的回答上,过去常用的多模态大模型评测方法是堆砌多个任务的成绩。但简单以“更多任务上更高分”衡量模型强弱并不可靠,模型在某些任务上表现突出也并不一定意味着它在所有领域都更接近人类智能水平。
正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。
近期录用于ICML’25 (Spotlight)的论文《On Path to Multimodal Generalist: General-Level and General-Bench》提出了一套全新的评测框架General-Level和配套的数据集General-Bench,为这一议题带来了奠基性的解答和突破。

该评测框架已落地于社区:上述论文的项目团队构建了涵盖700多个任务、覆盖5大常见模态、29个领域、多达32万+测试数据的超大规模评测基准和业界最完善的多模态通才模型排行榜Leaderboard,为公平、公正、全面地比较不同多模态通才大模型提供了基础设施。
General-Level评估算法:五级段位体系与协同效应
General-Level评测框架引入了一个五级段位体系,类似“段位晋级”的方式来衡量多模态模型的通才能力。
General-Level评估的核心在于协同泛化效应(Synergy),指的是模型将从一种模态或任务中学到的知识迁移提升到另一种模态或任务中的能力,简单来说就是1+1 > 2的效果。
模型的段位由低到高依次为:Level-1专业高手,Level-2通才新秀(无协同),Level-3任务协同,Level-4范式协同,Level-5全模态完全协同。段位越高表示模型展现出的“通用智能”越强,达到的协同效应层级越高。
General-Level正是通过考察不同层面的协同效应,来决定模型所属的段位的:

- Level-1 专家型选手(Specialist)
这一级别包括了当前各单项任务的专精模型,通常是针对某个数据集或任务单独微调到极致的SOTA模型。 - Level-2 入门通才(Generalist,无协同)
达到Level-2意味着模型开始具备“一专多能”的能力,能支持多种模态和任务,但尚未体现出协同增益效应。 - Level-3 任务级协同(Task-level Synergy)
晋升Level-3要求模型出现任务层面的协同提升。这意味着模型通过多任务联合学习,在某些任务上的成绩超越了该任务的专精模型SOTA。 - Level-4 范式级协同(Paradigm-level Synergy)
要迈入Level-4,模型必须展现跨范式的协同,也就是在“理解与生成”这两大任务范式之间形成协同效应。本段位代表模型已开始具备“生成-理解一体化”的推理能力,能够跨越任务形式的差异进行知识迁移。 - Level-5 全模态完全协同(Cross-modal Total Synergy)
这是General-Level评估的最高段位,标志着模型在跨模态、跨任务范畴达成了全面协同,也是理想的AGI状态。
然而截至目前,尚无任何模型达到Level-5段位。
Level-5代表着通往AGI的终极目标,一旦有模型迈入此段位,也许就预示着通才AI朝“通用人工智能”跨出了关键一步。

总的来说,General-Level通过这五级段位体系,将评估视角从单纯堆叠任务分数,提升到了考察模型内部知识的迁移融合能力。
这种段位制在保障客观量化的同时,也为业界描绘出一条从专才到通才再到“全才”的进阶路线图。
General-Bench评测基准:一张多模态通才的超级考卷
General-Bench被誉为当前规模最大、范畴最广、任务类型最全面的多模态通才AI评测基准。
它不仅是一张考察多模态AI能力的“通才高考卷”,更是一个集广度、深度、复杂性于一体的全景式评测系统。
在广度上,General-Bench覆盖了五大核心模态——图像、视频、音频、3D以及语言,真正实现了从感知到理解,再到生成的全链路模态覆盖。
在深度维度,General-Bench不仅涵盖了大量传统理解类任务(如分类、检测、问答等),更纳入了丰富的生成类任务(如图像生成、视频生成、音频生成、描述生成等)。
更值得注意的是,所有任务均支持Free-form自由作答,不局限于选择题或判断题,而是依据任务原生的开放指标进行客观评估,填补了业界长期以来的评测盲区。

从数据规模来看,General-Bench汇集了700余个任务、325,000+个样本,并细分为145项具体技能,全面覆盖视觉、听觉、语言等模态下的核心能力点。
在这些技能背后,General-Bench跨越了29个跨学科知识领域,囊括自然科学、工程、医疗、社会科学、人文学科等,从图像识别到跨模态推理、从语音识别到音乐生成、从3D模型到视频理解与生成,应有尽有。
此外,General-Bench还特别关注模型在内容识别、常识推理、因果判断、情感分析、创造与创新等高阶能力上的表现,为通才AI模型提供了一个多维度、立体化的评测空间。
可以说,General-Bench是一张挑战性前所未有的多模态综合考卷,从模态维度到任务范式,再到知识领域,全方位检验AI模型的广度、深度与综合推理能力。
目前,General-Bench的任务样本总量已达到325,876,并将保持开放动态增长。这一开放性与可持续更新,确保了General-Bench具备长期生命力,能够持续支撑多模态通才AI的研发与演进。
多Scope Leaderboard设计:全模态通才到子技能通才
有了General-Level评估标准以及数据集,还需要一个公开透明的排行榜来呈现各模型的评测结果和排位。这正是项目的Leaderboard系统。
为了兼顾评测全面性与参与门槛之间的平衡,Leaderboard设计了多层次的榜单Scope分层解耦机制(Scope-A/B/C/D)。
不同Scope相当于不同范围和难度的子排行榜,允许能力各异的模型各展所长,从“全能冠军赛”一路覆盖到“单项能力赛”, 既保证了顶尖通才模型有舞台角逐全能桂冠,也让普通模型能选择合适范围参与比较,降低了社区参与的门槛。

Scope-A: 全谱英雄榜 :“全模态通才”争霸。
这是难度最高、覆盖面最广的主榜单:参赛模型必须接受General-Bench全集的考验,也就是涵盖所有支持的模态、所有范畴任务的完整评估。
Scope-A旨在选拔真正全能型的多模态基础模型,检验它们在全面复杂场景下的综合实力。
Scope-B: 模态统一英雄榜 :“单一模态通才”竞技。
Scope-B包括若干子榜单,每个针对特定模态或限定的模态组合。
具体而言,Scope-B划分出7个并行榜单:其中4个是单一模态榜(如纯视觉、纯语音、纯视频、纯3D),另外3个是模态组合榜(例如图像+文本、视频+文本等跨模态组合)。
参赛模型只需在所选模态范围内完成多任务评测,不涉及其它模态的数据。
Scope-C: 理解/生成英雄榜 :“范式能力”分组竞技。
Scope-C将评测进一步细分为理解类任务和生成类任务两大范式,在每种模态下分别设榜。具体来说,在图像、视频、音频、文本这几类模态中,各自分出“理解能力榜”和“生成能力榜”两个榜单,共计8个榜单。
Scope-C评测强调同一模态内跨任务范式的迁移能力:比如一个模型在视觉理解榜表现优异,说明它在视觉分类、检测等多种理解任务间具备共享知识的能力;在视觉生成榜得分高则意味着它在各种生成任务(描述、画图)上都有通用能力。
由于限制了任务范式的范围,Scope-C对资源要求较低(三星难度),非常适合轻量级模型或资源有限的团队参与。
Scope-D: 技能专长榜:“细分技能”擂台。
这是粒度最细、参与门槛最低的一类榜单。Scope-D将General-Bench中的任务按具体技能或任务类型进一步聚类,每个小类单独成榜。
例如:“视觉问答(VQA)榜”“图像字幕生成榜”“语音识别榜”“3D物体检测榜”等等,每个榜单涵盖一组密切相关的任务。
参赛模型可以只针对某一类技能提交结果,从而在自己最擅长的狭窄领域与其它模型比较。
这种技能榜机制鼓励模型循序渐进地发展:先在单点技能上做到极致,再逐步挑战更广泛的多任务、多模态评测。
Leaderboard链接可见文末。
Leaderboard参赛指南:提交流程与公平评测机制
为了促进社区参与,General-Level项目提供了清晰的Leaderboard参赛流程和严格的公平性保障机制。
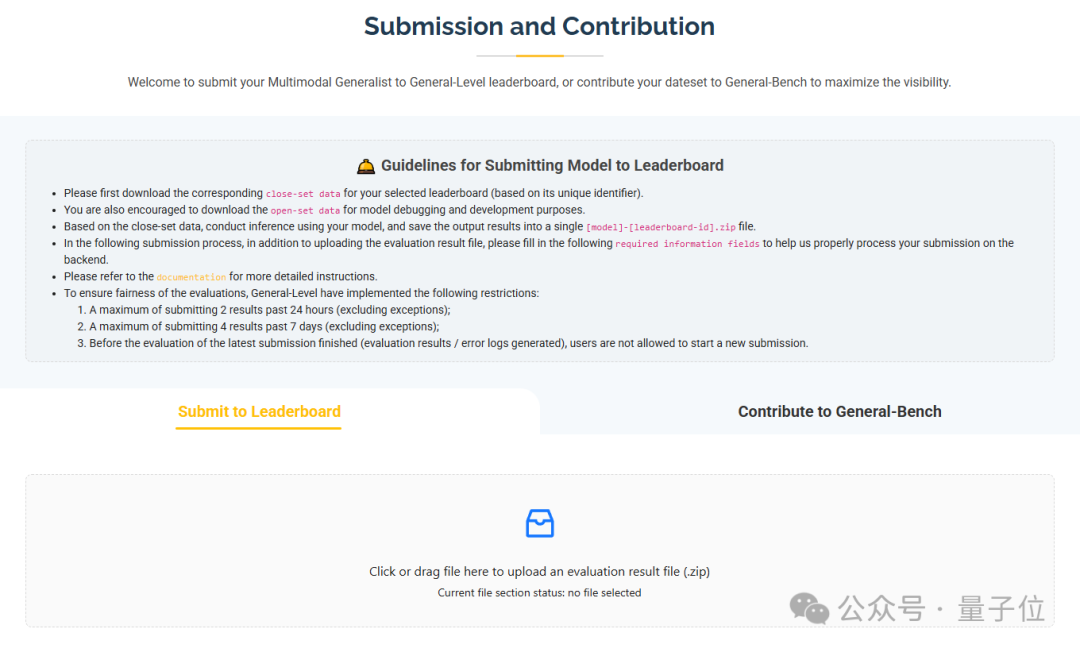
无论是学术研究团队还是工业实验室,都可以按照以下步骤将自己研发的多模态模型提交到Leaderboard打榜:
1.选择榜单与下载评测数据
首先根据模型能力,选择适当的Leaderboard范围(Scope)和具体榜单ID。
选定榜单后,从官方提供的链接下载该榜单对应的封闭测试集(Close-set data)。
这是一份只包含输入的测试数据,不公开标准答案,用于正式评测。
官方同时提供了开放开发集(Open-set data)用于调试开发,在打榜前可用于本地测试模型输出格式等。
2.本地运行模型推理
拿到封闭测试集后,在本地用模型对其进行推理Inference,生成对应的输出结果。
需要注意的是,每个榜单可能包含多种任务类型,提交的结果文件应严格遵循官方规定的格式和目录结构。提交前请务必参考官方的详细提交文档确认格式要求。
一旦输出结果整理完成,将其命名为“[模型名称]-[榜单ID].zip”以备上传。
3.提交结果并填写信息
在Leaderboard网站的提交入口,上传上述结果ZIP文件。同时需要填写一些必要的模型信息(如模型名称、参数规模、简介等)以及联系邮箱等,以便主办方后台正确处理结果。
如果想让自己的模型得到更多曝光,团队也可以选择在结果提交后公开模型的详细说明或技术报告,方便社区了解模型亮点。
4.等待评测与查看榜单
提交结果后,系统会在后台对模型输出进行评分,包括计算各任务指标并汇总成General-Level段位分数。
由于封闭测试集的答案和评分脚本在后台保密运行,提交者无法直接得知未公布数据的答案,从而保证了评测的公正性。
评测完成后,Leaderboard页面将实时更新:新模型会出现在对应榜单上,展示模型名称、所属模态范畴、各模态下的得分以及总分、段位等级和提交日期等信息。这样,提交者和公众都能立即在排行榜上看到模型的名次和段位。
排行榜支持按段位或分数排序,清晰标识哪些模型达到了Level-3、Level-4等协同级别。
为了确保Leaderboard评测的公平性和权威性,项目方还制定了一系列规则和限制:
封闭测试:所有排行榜使用的数据集均为封闭集,模型不得使用这些测试数据进行训练或调优,这一点通过协议约束和数据监控等方式严格执行。
同时,由于是封闭评测,模型开发者在提交结果前也无法得知正确答案,从根本上保证了成绩的可信度。
限频提交:每个用户24小时内最多提交2次,7天内最多提交4次结果,并且在前一次提交的评测尚未完成时,不允许发起新的提交。
这些措施有效杜绝了利用提交机会反推标准答案或对封闭集过拟合的可能,避免了有人反复试错投机,维护了排行榜的严肃性。
统一评测环境:所有模型提交均在主办方统一的评测环境中执行评分,确保不同模型的比较在相同标准下进行。
无论模型使用何种框架或推理加速,最终成绩都以相同的指标体系衡量,并根据General-Level算法转换成段位分数,从而可直接横向对比。
通过以上流程与机制,General-Level Leaderboard为研究者提供了一个开放且公平的竞技场。
在这里,新的模型算法可以得到客观检验,与业界现有的方法同台比拼;同时封闭评测也保障了结果的可信度,使排行榜成为公认权威的数据点。
排行榜现状:代表模型段位分布与社区反馈
截至目前,排行榜收录了100多个多模态模型的成绩,并根据General-Level标准揭示了它们在通才能力上的座次高低。
在首批发布的闭集评测榜单中,各模型整体表现差异悬殊,甚至颠覆大家对常见的多模态大模型的能力排位的认知。
纵观排行榜,不同段位档次已经初现梯队分布。
Level-2(无协同)

排行榜中占比最多的就是Level-2段位模型,其中包括GPT4-V等重量级闭源模型,其他大量的常用的开源模型也位列其中。
这些模型胜在支持任务范围广,几乎囊括所有测评任务,但极少在任何任务上超越单项SOTA。因此它们被General-Level评为Level-2通才,只能算是“全科及格”的水平。
值得注意的是,GPT4-V等虽是商业顶尖模型,但由于没有针对评测任务进行专项优化,未能体现协同增益,评分并不出挑。
相反,一些开源模型通过多任务训练,全面开花,也跻身Level-2行列,如SEED-LLaMA、Unified-IO等。这一层级模型主要的能力分布在图片模态上,且单模态的平均得分带大致在10-20分左右,表现尚有巨大提升空间。
当前Level-2的冠亚季军分别为:Unified-io-2-XXL,AnyGPT以及NExT-GPT-V1.5。
Level-3(任务协同)

这一级别所汇聚的多模态大模型相比于Level-2少了很多,它们在若干任务上击败了专业模型,展现出协同学习带来的性能飞跃。
许多2024年后的新模型纷纷晋升此列,包括开源的Sa2VA-26B、LLaVA-One-Vision-72B、Qwen2-VL-72B系列。这些模型通常具有数百亿参数且经过海量多模态、多任务训练,因而在部分Benchmark上超越了传统单任务SOTA的成绩。
这证明了协同效应的价值:统一的多任务训练可以让模型学到更通用的表征,在相关任务上互相促进性能。
反而,一些闭源大模型如OpenAI的GPT4-o、GPT4-V和Anthropic的Claude-3.5等在Level-3上表现不够靠前。
Level-3模型的整体平均分范围相比Level-2继续降低,这表示本Level更加困难的得分情况。
Level-4(范式协同)

达到此段位的模型目前仍属凤毛麟角。
据Leaderboard显示(截止评测日期24年12月),仅有极个别模型被评为Level-4,如体量巨大的Mini-Gemini、Vitron-V1、Emu2-37B等原型开源模型。
这些模型在跨范式推理上有所突破,兼具卓越的理解与生成能力,并能将两者融会贯通。
例如Mini-Gemini模型在图像理解和生成两方面均取得领先,其在Leaderboard的范式协同评分上名列前茅。
Level-4段位的出现,意味着离真正的跨模态推理AI又近了一步。不过当前Level-4模型的平均分非常低。这揭示了构建范式全面协同AI的巨大挑战:要兼顾多模态的理解与生成并取得双重突破,非常不易。
Level-5(全模态总协同)
这一段位至今依然是空缺状态,没有任何模型能够达成。
这并不意外,因为要在所有模态和任务上都超越专家并同时提升语言智能,目前来看超过了现有技术的能力范围。
General-Level团队推测,也许下一个里程碑将来自“多模态版”的GPT-5,它们有可能首次展现全模态协同的苗头,从而改写Level-5无人问津的局面。
不过在那一天到来之前,Leaderboard上Level-5位置还将继续空悬,也提醒着我们距离真正的AGI依然有不小的距离。
当前Leaderboard的推出在AI研究社区引发了热烈反响。许多研究者认为,这样一个统一的、多维度的评测平台正是多模态领域所急需的:它不仅规模空前(覆盖700+任务)、体系完整(有等级有分项),而且公开透明,为业界提供了共同进步的参照。
在社交媒体和论坛上,大家对排行榜上的结果展开讨论:有人惊讶于开源模型Qwen2.5-VL-72B竟能击败许多闭源巨头,证明开源社区的潜力;也有人分析GPT-4V在复杂视听任务上的短板,探讨如何弥补。
Leaderboard的数据还被用来指导研究方向:哪些任务是多数模型的薄弱项,哪些模态结合尚未被很好解决,一目了然。
可以预见,随着更多模型加入打榜,排行榜将持续更新,这不仅是一场竞赛,更是在不断积累宝贵的科研洞见。
General-Level评测框架与其Leaderboard排行榜的推出,标志着多模态通才AI研究进入了一个新阶段。正如作者在论文中所期望的那样,该项目构建的评估体系将成为坚实的基础设施,帮助业界更科学地度量通用人工智能的进展。
通过统一标准的段位评测,研究者可以客观比较不同模型的优劣,找出进一步提升的方向;通过大规模多任务的Benchmark,可以全面考察模型在不同领域的能力短板,加速发现问题并迭代改进。这一切对于推动下一个世代的多模态基础模型、乃至朝真正的AGI迈进,都具有重要意义。
更可贵的是,General-Level项目秉持开放共享的态度,欢迎社区广泛参与共建。无论您是有新模型方案,还是手头有独特的数据集,都可以参与进来:提交模型结果上榜,与全球顶尖模型一决高下;或贡献新的评测数据,丰富General-Bench的任务多样性。
每一份数据集的加入,都会在官网主页获得鸣谢并在技术报告中被引用。
项目主页:https://generalist.top/
Leaderboard:https://generalist.top/leaderboard
论文地址:https://arxiv.org/abs/2505.04620
Benchmark:https://huggingface.co/General-Level
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)