



论文标题:
MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing
论文链接:
https://arxiv.org/abs/2411.16773
收录会议:
CVPR 2025

研究背景
3D 点云处理(PCP)涉及多种任务,如重建、去噪、配准、分割等,传统做法往往为每个任务设计特定模型,导致模型繁杂、成本高昂。虽然多任务学习(MTL)能缓解模型数量问题,但在任务冲突、参数调优方面仍存在挑战。
近年来兴起的 In-Context Learning(ICL)技术,不依赖参数更新,仅通过 “提示示例” 即可适配多个任务,展示出任务泛化潜力。但将 ICL 用于点云处理时,当前方法面临任务间和任务内的显著敏感性问题。
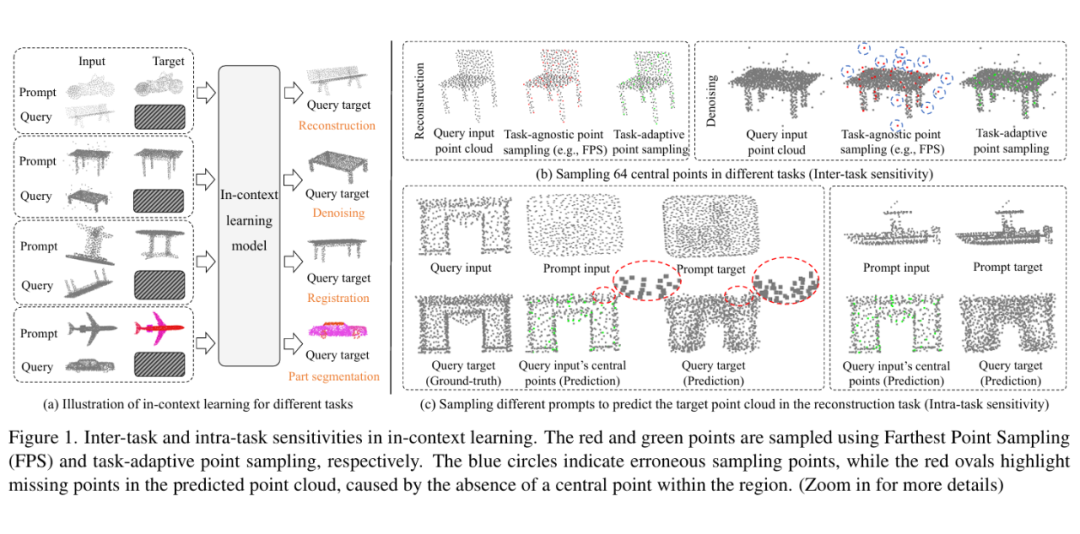

MICAS 方法:从采样出发,让上下文学习更“懂点云”
本论文提出 MICAS,首个专为点云上下文学习设计的多粒度自适应采样方法,从 “点级” 和 “提示级” 两个维度提升 ICL 在 3D 任务中的稳健性和适应性。
2.1 MICAS 的两大核心模块
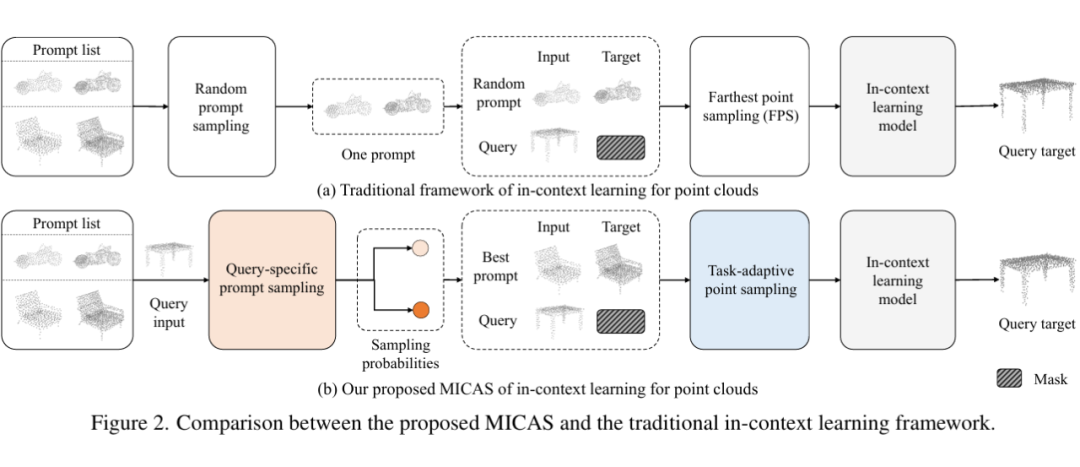
Task-Adaptive Point Sampling:利用任务信息,引导点级采样策略,提升模型对任务特征的适配能力。(同一个点云在不同任务中能够产生差异化的采样结果,从而提升任务适应性与表达能力。)
Query-Specific Prompt Sampling:针对每个查询输入,动态选择最优的提示示例,缓解同一任务内提示样本多样性带来的敏感问题。
2.2 MICAS 的具体实现
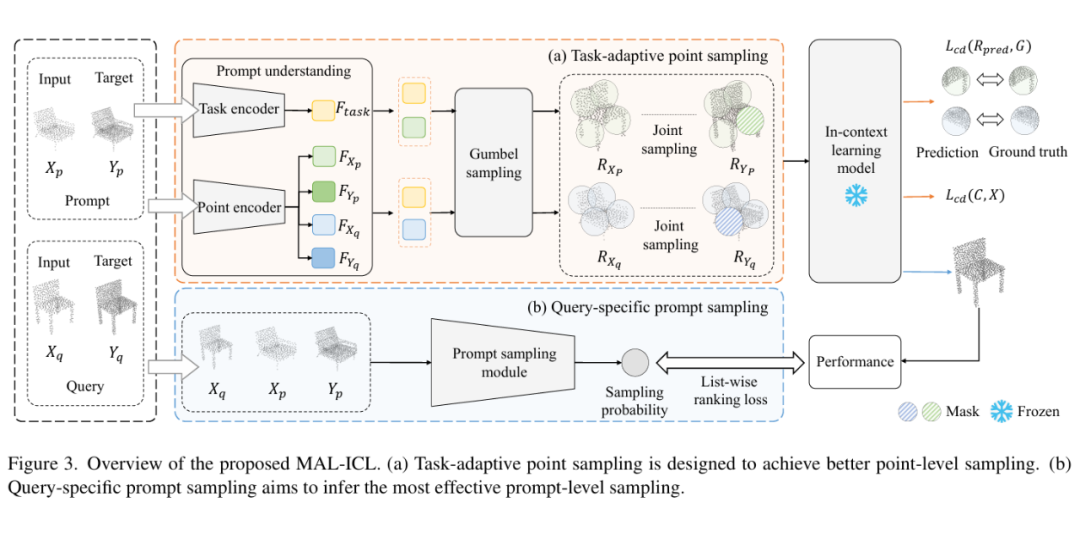
任务自适应点采样(Task-adaptive Point Sampling)
目标:利用任务相关的信息,优化每个点的采样过程,以提高不同任务间(例如重建、去噪、配准、分割)对点的选择精度。
实现步骤:
-
提示理解(Prompt Understanding):使用 PointNet 作为编码器,从输入的 prompt 中提取任务特征。通过将输入点云和目标点云的特征进行拼接,生成任务特征。
-
Gumbel 采样(Gumbel Sampling):利用 Gumbel-softmax 实现可微分的采样。这个机制将任务特征和当前点云的特征结合,通过正态化的 sampling weights 生成最终的采样结果。这一过程允许模型在训练期间得到更高的效能。
查询特定提示采样(Query-specific Prompt Sampling)
目标:在相同任务中,针对不同的查询提高提示的相关性,以克服任务内部的各种敏感性。
实现步骤:
-
伪标签生成:通过 ICL 模型生成预测结果,并评估其与真实值之间的差异,利用这些模型性能作为伪标签。
-
采样分值计算:对于每个查询点云,根据不同候选提示计算采样分值,选取分值最高的提示作为最终输入。
-
损失函数:使用 List-wise ranking loss 来优化提示的选择顺序,从而提高模型的整体性能。

实验设置
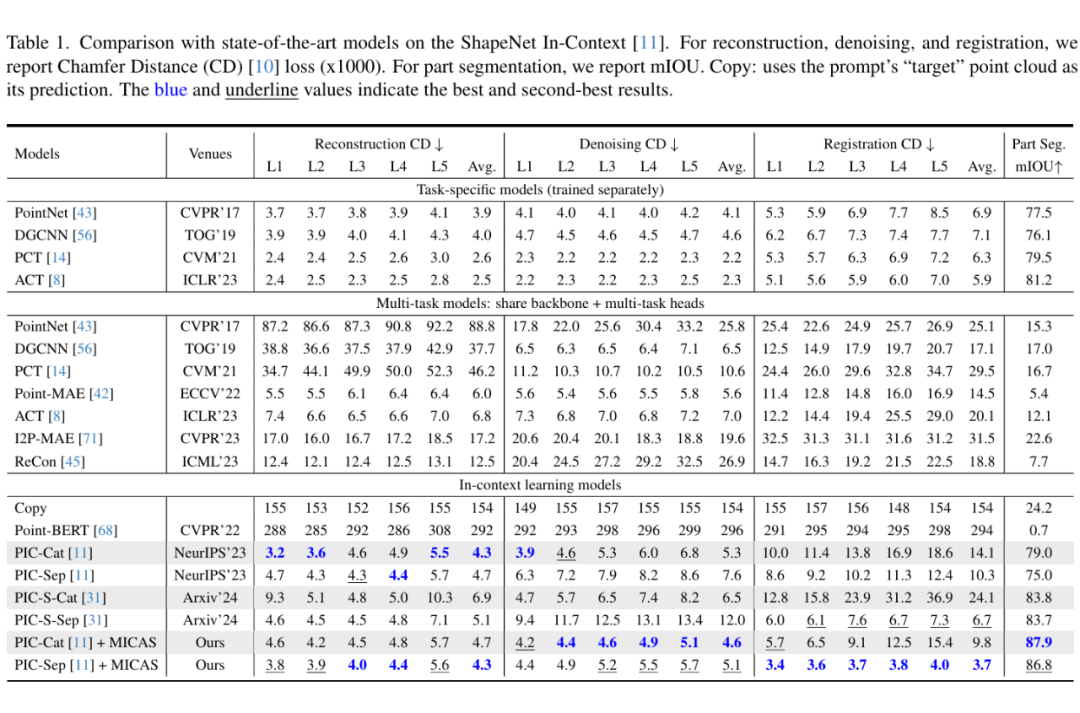
评估数据集:使用 ShapeNet In-Context Dataset,该数据集包含了多种“输入-目标”点云的对,以便进行全面的任务评估。
评估指标:使用 Chamfer Distance(CD)和 Mean Intersection over Union(mIOU)来衡量不同任务的性能。例如,CD 用于重建、去噪和配准任务,mIOU 用于分割任务。

结果与讨论
性能提升:通过对任务自适应点采样和查询特定提示采样的联合使用,MICAS 在所有被评估任务中均显著超越现有技术,特别是在部件分割任务中,性能相较于前作提升了 4.1%。
严谨性与可靠性:进行了一系列对比实验和消融研究,验证了 MICAS 在不同场景下的鲁棒性,同时展示了各组件在整体性能提升中的协调作用。
复杂度管理:在模型训练过程中,通过分步骤训练来降低复杂度,使得模型既能有效学习任务特征,又可轻松适应不同的提示。


模型训练和推理可视化

实验结果对比可视化
▲ 重建任务的采样结果对比
▲ 去噪任务的采样结果对比
▲ 配准任务的采样结果对比
▲ 分割任务的采样结果对比
(文:PaperWeekly)