


邮箱|wf@pingwest.com
当ChatGPT在2022年横空出世,大模型技术掀起全球科技浪潮时,它开始改变了人工智能,慢慢又改变了语音对话,它进一步地试探进入到了交互领域,但很少有人能预见到,仅仅三年后,这股AI革命浪潮会深刻地改变汽车行业。
这场关乎智能汽车的革命浪潮以一种名为VLA的技术展开,也是以一种“Agent”的方式。
如果你关注智能辅助驾驶行业,应该了解这两年的热词“端到端”。
关于VLA,全名则为Vision-Language-Action,作为视觉–语言–行为三位一体的大模型架构,不少业内人士将VLA技术视为当下“端到端”方案的进阶版本——它将空间智能、语言智能和行为智能统一在一个模型里,由此它也拥有更高的场景推理能力与泛化能力。
简而言之,有VLA赋能的车不再只是一个驾驶工具,而是一个能与用户沟通、理解用户意图的智能体,通过语言模型和逻辑推理结合在一起之后,它能够成为一个听得懂、看得见、找得到,真正意义上的“司机Agent”。
自动驾驶技术正在经历的一场静悄悄但深刻的范式转移:从规则驱动向学习驱动,从分布式感知–决策–控制向端到端一体化架构,再到今天VLA的多模态融合统一建模。技术不再只是模块叠加的堆栈,也不再满足于“看得见”和“听得懂”,而是要求AI真正“行动起来”。“司机Agent”也拥有像人类司机一样理解环境、做出判断并立即执行的能力——成为像人一样在复杂世界中感知、理解、推理和行动的整体智能体。
放眼硅谷到北京,大洋彼岸的Waymo到理想,在这种多模态模型与机器人框架的技术趋势中,理想汽车成为了中国车企中走在最前面的一位践行者。
在2025理想AI Talk第二季活动上,理想汽车董事长兼CEO李想聚焦理想汽车最新推出的VLA司机大模型,不仅展示了“司机Agent”,更通过他本人对AI与人性的深度思考,勾勒出了智能汽车发展的新范式——
AI不应该是简单地将“汽车智能化“,而是真正实现“人工智能的汽车化“。
从NOA到VLA,理想为何要实现AI三段跳?
理想并非是突然转向VLA的。在此之前,也经历了充足的技术积累。
实话说,李想此前在第一季AI Talk上首次提出公司未来是一家领先的人工智能企业的时候,很多人可能并没有get到他在表达什么。
但如果你观摩了理想这连续的两季AI Talk活动,大概能看出这家公司是如何奔向“连接物理世界和数字世界,成为全球领先的人工智能企业”企业愿景的。
在第一季AI Talk活动中,理想展示出了技术路径其一:将公司汽车的销量挤到中国市场的领先地位,卖出年销量50万辆的汽车,在车上全部部署上端到端技术、Mind GPT,随后Mind GPT经过1.0/2.0,然后到3o多模态智能体的迭代后,理想决定推出理想同学App,让这个语音助手触及到更多的人。
第二季AI Talk活动中,理想回顾了在辅助驾驶领域的发展历程,我们也可以清晰地看到一条从量变到质变的技术演进路线:2023年年底,全场景NOA的推送标志着理想辅助驾驶从高速向城市场景的延展,为用户带来了更全面的智能辅助驾驶体验。而2024年7月15日推送的无图NOA功能,则首次实现了对先验信息依赖的突破,让车辆能够在没有高精度地图的情况下依然保持良好的驾驶表现。

2024年10月23日,理想汽车推送的端到端+VLM功能,真正意义上实现了One Model一体化端到端模型的大规模实践应用,并首次将大模型部署至车端量产芯片。这一突破性进展不仅体现了理想在AI算法上的深厚积累,更展示了其在车规级硬件与大模型融合方面的独特优势。
2025年3月18日,理想汽车正式发布下一代自动驾驶架构VLA。这在业内算是一次质的飞跃——当众多汽车品牌仍在为L2级辅助驾驶技术优化细节时,理想汽车却完成了一场田径运动中的“三级跳“,通过层层递进取得成绩,理想汽车的智能驾驶技术经历了从规则算法、到无图NOA、再到端到端+VLM,最终迈向VLA司机大模型的“三段“进化。
如果从结果来验证这其中的规律:从无图NOA到端到端+VLM,再到VLA司机大模型,每一步都至关重要,且每一阶段都是不可跨越。
比如NOA这一阶段的核心在于感知能力和环境适应性的提升,是连接规则算法和端到端模型的关键桥梁。
第二阶段端到端+VLM功能,标志着从规则驱动向数据驱动的根本转变。
前两个阶段的技术沉淀,解决了两个问题:一是前期没有足够的数据支撑模型训练;二是缺乏规则约束导致的安全风险。
汽车驾驶不同于简单的互联网应用,它直接关系到用户的生命安全,需要在实际道路环境中反复验证和迭代。
如果没有通过前期收集的大量实际道路数据和规则算法的约束,成功训练出了稳定可靠的端到端模型,并将其与VLM视觉语言模型结合,就无法初步实现了系统对环境的“理解“,只是简单的“识别“。

理想的VLA从“辅助”到“智能体”的跃迁,建立在前三个阶段所有技术积累的基础之上。如果没有规则算法打下的基础,系统就无法理解基本驾驶规则;如果没有无图NOA阶段锻造的环境适应能力,系统就无法应对未知场景;如果没有端到端+VLM阶段的模型整合经验,VLA的三位一体架构就无从谈起。
从一定程度上来说,VLA技术的成功离不开中国本土AI市场的崛起。
另外,也正如DeepSeek在大模型领域的发展路径所示,从构建集群能力到基建、链路的优化,通过这些前期的积累,才能实现低成本和高效率的AI应用。DeepSeek不可能一步到位构建出强大的大语言模型,而是经历了从基础算法研究、数据收集清洗、模型架构优化到最终产品落地的完整过程。
李想也在活动上强调:“如果规则算法都做不好,根本不知道怎么去做端到端;如果端到端没有做到一个极致的水平,那连VLA怎么训练都无从谈起。“这也再次证明,这个过程中没有捷径可走,每一步都是通往下一步的必要铺垫。
司机Agent,VLA的实力
说了这么多,VLA到底可以实现什么样的功能?
前面提到,VLA(Vision-Language-Action)是视觉–语言–行为大模型,代表着机器人大模型的新范式。它将空间智能、语言智能和行为智能统一在一个模型中,赋予了系统强大的3D空间理解能力、逻辑推理能力和行为生成能力,让自动驾驶系统真正具备感知、思考和适应环境的能力。
在理想最新公布的demo视频里,理想的这个“司机Agent”展示了其“能听懂人话”且“直接执行”的智能辅助驾驶能力:

从技术原理上看,前文提到的端到端+VLM的阶段,VLA并非简单地将端到端模型和VLM模型结合在一起,而是所有模块的全新设计与整合。

据介绍,其工作流程可概括为:3D空间编码器通过语言模型处理后,与逻辑推理结合,给出合理的驾驶决策,并输出一组action token(动作词元)。这些action token是对周围环境和自车驾驶行为的编码,随后通过diffusion(扩散模型)进一步优化出最佳的驾驶轨迹。整个推理过程都发生在车端,并且实现了实时运行,这对计算效率和系统响应速度提出了极高要求。
我们尝试简单类比解读一下:
-
视觉智能(Vision):就像人类驾驶员通过眼睛观察道路情况,VLA通过车载摄像头和传感器”看见”周围环境。但不同于传统系统只是识别物体,VLA能够理解场景的语义和空间关系。这就像是从”我看到一个红色物体”升级到”我明白这是一个红灯,需要停车,而且它位于前方十米处的十字路口”。 -
语言智能(Language):如果说视觉智能是VLA的”眼睛”,那么语言智能就是它的”大脑”。通过强大的语言理解和推理能力,VLA可以处理复杂的人类指令,理解上下文,并将视觉信息与语言知识融合。比如当你说”在前面路口掉头”时,VLA不仅能识别出”路口”这个概念,还能将它与视觉中看到的道路匹配,理解”前面”这个相对位置,并执行适当的停车操作。 -
行为智能(Action):这是VLA最与众不同的部分,它不只是理解,还能采取行动。VLA将对环境的理解转化为精确的驾驶决策,生成平滑、自然的驾驶轨迹。这就像一个经验丰富的司机,不仅知道何时转弯,还知道如何以合适的速度和角度完成转弯,使乘客感到舒适。
相对直观地理解VLA的工作原理,可以尽可能地将其想象成一个高效的驾驶决策链条。
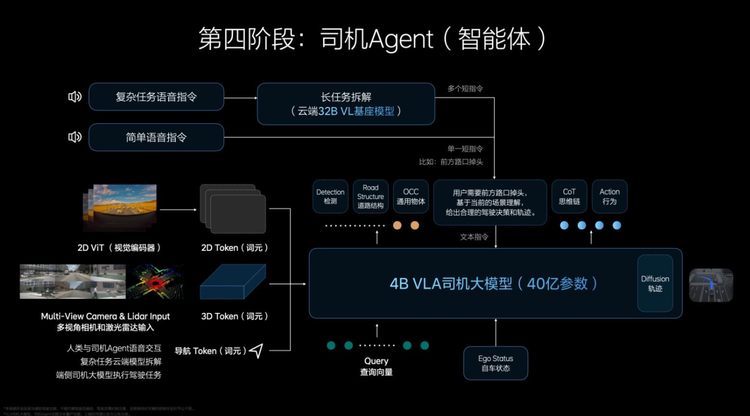
理想称,理想辅助驾驶系统从“端到端+VLM双模型分立“向“VLA三位一体架构“的跃迁,本质上是突破了多模态协同效率与物理世界建模能力的双重瓶颈。
多模态协同效率问题可以理解为:之前的双模型架构就像两个专家各自独立工作——一个负责开车,一个负责理解指令,沟通效率低下。两个模型工作频率不同,联合训练和优化困难。想象一下两个人合开一辆车,一个人负责方向盘,一个人负责油门和刹车,却无法流畅沟通,这显然会导致驾驶不协调。VLA则将这两位专家的能力整合在一个大脑中,实现了无缝协作。
物理世界建模能力不足则更像是:基于千问等大模型的VLM虽然在互联网2D图文数据上训练充分,但对于3D世界的理解和专业驾驶知识存在短板。就像一个在模拟器上学习驾驶的人,缺乏真实道路的立体感和空间认知。VLA通过专门的3D空间编码技术和大量真实驾驶数据训练,弥补了这一不足。
从视频上的效果来看,VLA能够更好的处理人类驾驶行为的多模态性,可以适应更多驾驶风格。
这也是前文所提到的,语言模型和逻辑推理结合在一起之后,它能够成为一个听得懂、看得见、找得到,真正意义上的“司机Agent”。
“类似人和代驾的关系,人们怎么和代驾说,就怎么和司机Agent说。”
理想率先驶入无人区
很明显,VLA技术的突破,在汽车座舱和车辆驾驶层面进行了结合,也拉高了智能辅助驾驶系统的上限。
李想将智能辅助驾驶拆解成了三个发展阶段,用自然界中不同的物种进行了形象的比喻:
-
第一阶段,昆虫动物智能。通过机器学习感知配合规则算法的分段式辅助驾驶解决方案,需要有既定的规则,同时依赖高精地图,类似蚂蚁的行动和完成任务的方式。 -
第二阶段,哺乳动物智能。端到端阶段通过大模型学习人类驾驶行为(类似马戏团的动物),但其对物理世界的理解并不充分,此阶段通过三维图像判断自身速度和轨迹以及在空间中所处的位置,足以应对大部分泛化场景,但很难解决从未遇到过或特别复杂的问题,此时需要配合视觉语言VLM模型,但现有视觉语言模型在应对复杂交通环境时只能起到辅助作用。 -
第三阶段,人类智能。VLA阶段可以实现类似人类观察世界的方式,利用3D视觉和2D的组合构建更真实的物理世界,VLA拥有自己的脑系统,进一步理解物理世界,还具备语言和思维链系统,也就是VLA的司机大模型。
这同时也对应着李想本人对于AI工具的分级制度——信息工具、辅助工具和生产工具,“我觉得人工智能变成生产工具,然后才是真正人工智能爆发的时刻。“

一定程度上,这也是在强调,司机Agent——VLA技术有望成为具备这种生产工具特征的先驱者。
从人工智能行业来看,VLA是“机器人模型”的一种,是Physical AI的原型。在ChatGPT、Gemini等数字智能代表主导的软件智能浪潮之后,AI的下一个风口毫无疑问将是物理智能。汽车,作为最复杂的物理空间智能终端,是理想选择的主要切入口。一旦VLA模式在车上跑通,空间智能+语言智能+行为智能三者的融合,一定程度也将为其他领域的机器人模型打下范式基础。
OpenAI、DeepSeek等大模型公司虽强,但他们并未真正涉足汽车领域的空间智能与行为建模,更没有语料、数据和场景去覆盖家庭用户与真实路况的多样性。正因如此,理想选择了自己下场,打造自己的基座模型。实打实地讲,Language层上借助DeepSeek,但空间智能和行为智能部分也得靠自己一步步打磨,尝试建立闭环能力的雏形。
“交通工具”能否能成“空间机器人”尚未可知,但司机智能体确实是人工智能汽车化的无人区。
这场变革,不只是理想的突破,更是AI进化的必然。
正如手机并非因通话而被重新定义,而是因其成为“数字生活中枢”才改变了世界——今天的汽车,也将在VLA的驱动下,从“移动交通工具”进化为“移动智能空间”,成为AI与人的共生载体。
而这条从端到端走向VLA的进化之路,或许才刚刚开始。

(文:硅星人Pro)