


AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
论文第一作者为清华大学自动化系博士生韩东辰,指导老师为黄高副教授。他的主要研究方向包括高效模型架构设计、多模态大模型等。
Mamba 是一种具有线性计算复杂度的状态空间模型,它能够以线性计算复杂度实现对输入序列的有效建模,在近几个月受到了广泛的关注。
本文给出了一个十分有趣的发现:强大的 Mamba 模型与通常被认为性能不佳的线性注意力有着内在的相似性:本文用统一的公式表述了 Mamba 中的核心模块状态空间模型(SSM)和线性注意力,揭示了二者之间的密切联系,并探究了是哪些特殊的属性和设计导致了 Mamba 的成功。
实验结果表明,等效遗忘门和宏观结构设计是 Mamba 成功的关键因素。本文通过分析自然地提出了一个新的模型结构:Mamba-Inspired Linear Attention(MILA),它同时继承了 Mamba 和线性注意力的优点,在各种视觉任务中表现出超越现有的视觉 Mamba 模型的精度,同时保持了线性注意力优越的并行计算与高推理速度。

-
论文链接:https://arxiv.org/abs/2405.16605 -
代码链接:https://github.com/LeapLabTHU/MLLA -
视频讲解:https://www.bilibili.com/video/BV1NYzAYxEbZ
 ,单头线性注意力可以表达为:
,单头线性注意力可以表达为:
 。上式中,每个 Q 拥有全局感受野,可以与所有的 K、V 进行信息交互。实际应用中,线性注意力也可以应用在自回归的模型中,限制每个 token 只能与之前的 token 进行信息交互:
。上式中,每个 Q 拥有全局感受野,可以与所有的 K、V 进行信息交互。实际应用中,线性注意力也可以应用在自回归的模型中,限制每个 token 只能与之前的 token 进行信息交互:

 ,Mamba 所采用的状态空间模型可以表达为:
,Mamba 所采用的状态空间模型可以表达为:

 ,Mamba 会在每个维度分别应用上式的实数输入 SSM,从而得到下面状态空间模型:
,Mamba 会在每个维度分别应用上式的实数输入 SSM,从而得到下面状态空间模型: ,Mamba 与线性注意力的公式之间有许多相似之处。为了便于比较,本文将二者使用相同的公式进行表达:
,Mamba 与线性注意力的公式之间有许多相似之处。为了便于比较,本文将二者使用相同的公式进行表达:
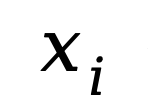 会与
会与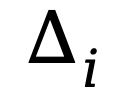 逐位相乘。由于
逐位相乘。由于 是每一位严格大于零的向量,因此可将其视为一个等效的输入门,可以控制输入 SSM 的比例。
是每一位严格大于零的向量,因此可将其视为一个等效的输入门,可以控制输入 SSM 的比例。 与
与 逐位相乘。在 Mamba 的实现中,每一位都是 0 到 1 之间的实数,因此实际控制对于之前的状态空间的衰减程度,因此可将其理解为等效的遗忘门。
逐位相乘。在 Mamba 的实现中,每一位都是 0 到 1 之间的实数,因此实际控制对于之前的状态空间的衰减程度,因此可将其理解为等效的遗忘门。 。
。 ,Mamba 中没有这样的归一化。
,Mamba 中没有这样的归一化。





(文:机器之心)
我弄