

语音交互技术的进步正在改变人机对话的方式,但传统语音助手受限于高延迟、单向交互和缺乏情感表达。
Maitrix 团队最新发布的开源 AI 端到端语音模型:Voila,其以 195ms 超低延迟及全双工对话得到众多开发者及企业的关注。

它是一款真正端到端、全双工、低延迟、可调角色的 AI 语音模型,可实现像人类一样“边听边说”的自然对话,并支持中英等多语言识别与翻译,具备极强的个性化和对话上下文保持能力。
支持实时自主对话、自动语音识别(ASR)、文本转语音(TTS)和多语言语音翻译,预置百万种语音和可定制角色。
核心功能
-
• 全双工语音对话:可同时听与说,不再是“你说完我再说”,模拟真实人类对话 -
• 超低延迟:仅 195 毫秒延迟,超越人类平均反应时间(200-250ms) -
• ASR/TTS支持:高精度语音转文本、文本转语音 -
• 语音个性预设:预置 100 万种语音风格(性别、年龄、情绪、音色均可控制) -
• 多语言支持:支持中英等多语种 ASR + TTS + 翻译 -
• 多模型分类:提供了用于各种音频任务的统一模型
快速入手
Voila 提供有在线网页版Demo地址直接体验,也可使用Python方式直接调用。
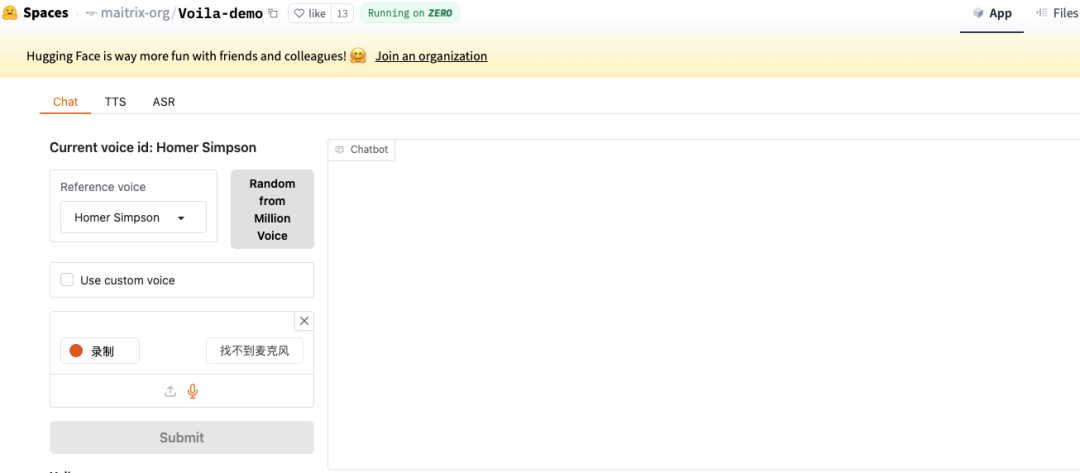
在线Gradio:https://huggingface.co/spaces/maitrix-org/Voila-demo
在线网页端打开后,你会看到它分为Chat、TTS、ASR三大模块,可选择语音角色,打开麦克风直接进行语音对话,或上传音频进行语音转文本等功能。
Python使用方式
① 克隆项目
git clone https://github.com/maitrix-org/Voila.git
cd Voila② 实时语音对话
import torch
from transformers import AutoModel, AutoProcessor
model = AutoModel.from_pretrained("maitrix-org/Voila-base").to("cuda")
processor = AutoProcessor.from_pretrained("maitrix-org/Voila-base")
audio_input, _ = librosa.load("test.mp3", sr=16000)
inputs = processor(audio=audio_input, sampling_rate=16000, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_length=2000)
audio_output = processor.decode(outputs.audio, sampling_rate=16000)
with open("output.wav", "wb") as f:
f.write(audio_output)
python infer.py --model-name "maitrix-org/Voila-base" --input-audio "test.mp3" --task-type chat_aiao③ 文本输入
python infer.py --model-name "maitrix-org/Voila-chat" --input-text "Hello" --task-type chat_tito④ 角色定制
python infer.py --model-name "maitrix-org/Voila-chat" --input-text "Speak as a cheerful guide" --task-type chat_tito⑤ 在线Web界面
python gradio_demo.py典型应用场景
-
• AI 虚拟人(直播、陪伴机器人) -
• AI 语音助手(如车载、智能硬件) -
• 实时语音翻译器 -
• 多角色语音教学助手 -
• RPG 语音 AI 剧情引擎(支持角色自定义)
架构设计
Voila 采用模块化设计,包含:
-
• ASR 模块:语音识别模块(实时) -
• LM 模块:语言模型模块(支持多模态思考) -
• TTS 模块:文本转语音模块(低延迟、可调节音色/情绪) -
• Controller:调度和个性化对话控制器(角色指令解析器)
可通过 Hugging Face + WebRTC 实现浏览器或本地实时语音对话。
写在最后
这款 Voila 模型确实是语音 AI 的一个突破性进展,特别是在“全双工”“端到端”“超低延迟”这些关键特性上。
它作为一款刚刚开源的新型语音模型,实现了真正的全双工对话能力 — 就像真人一样边听边说、低延迟互动、可自定义说话者性格。
可通过文本 prompt 指令设置说话者“人设”,生成百万种不同声音。
如果你在构建 AI 语音应用,Voila 是一个值得重点关注的下一代模型。
GitHub 开源地址:https://github.com/maitrix-org/Voila

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)