

skjack 投稿
量子位 | 公众号 QbitAI
近年来,人脸合成技术在快速发展,相关检测任务也逐渐从“看得出来”向“说明白为什么”演进。除了判断一张脸是真还是假,更需要模型能“说出个所以然”。
在CVPR 2025的工作《Towards General Visual-Linguistic Face Forgery Detection》中,研究团队尝试从视觉+语言的多模态视角来改进伪造检测方法。
本文提出了一种简单有效的训练范式,并围绕数据标注问题,构建了一个高质量的文本生成流程。
为什么要引入语言模态?
在伪造检测任务中加入语言,有两个直接的好处:
-
第一,提升可解释性。比起真和假的这种二元黑盒输出,如果模型能进一步说明“假在哪里”“怎么假”,无论是用于分析溯源,还是辅助下游任务,都更有价值; -
第二,激活预训练知识。现有的一些视觉backbone(如CLIP、LLaVA)等被证明能力已经高于很多纯视觉预训练模型,而这些模型在下游任务的潜在的知识需要语言模态来激活。所以我们希望它们的语言模态不仅能辅助理解图像细节,还能提高模型的迁移能力和泛化表现。
因此,团队提出了如图所示的一个新的多模态训练框架:
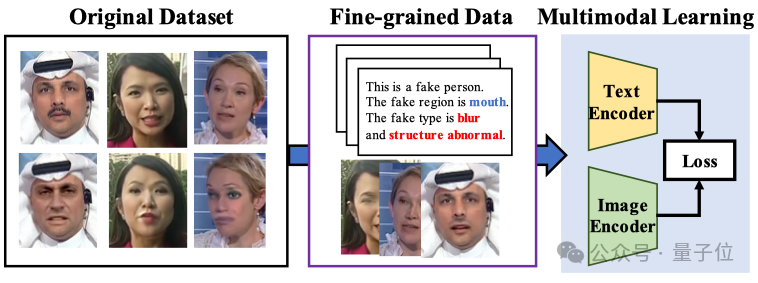
△图1:视觉语言伪造检测训练范式
该方法的关键在于:不再直接用图像做二分类判断,而是先为伪造图像生成文本描述,再通过这些图文对来联合微调多模态模型,比如CLIP或mLLM。这样训练后的模型不仅能判断伪造,还能在语言中“指出问题所在”。
但问题也随之而来——
数据从哪里来?
多模态任务的关键是高质量标注数据。而伪造检测任务相比于传统的图文匹配,难度在于:
-
它是一种更偏底层的任务,涉及的伪造往往是非常微妙的局部特征(比如鼻梁稍微歪了一点、嘴角颜色糊了一点); -
要准确地用语言描述这些细节,远没有那么容易。
目前社区主流的做法大概有两类:
-
人工众包标注(如DD-VQA); -
利用大模型(如GPT-4o)生成伪造描述。
但实验发现,两种方式都存在较明显的问题,尤其在高质量伪造图像中,容易出现“看花眼”的情况——模型或者标注人可能会误判没有问题的区域,产生所谓的“语言幻觉”。
如下图所示,仅嘴部被修改的伪造图,GPT和人工标注都错误地指出了鼻子区域:

△图2:现有伪造文本标注容易出现幻觉
此外,真实图像该怎么标注?要不要也写一段文字描述?怎么写才不误导模型?这些问题都说明:需要一个系统化的、高可信度的标注流程。
FFTG伪造文本生成流程
针对上述挑战,研究团队提出了FFTG(人脸伪造文本生成器),这是一种新颖的标注流程,通过结合伪造掩码指导和结构化提示策略,生成高精度的文本标注。
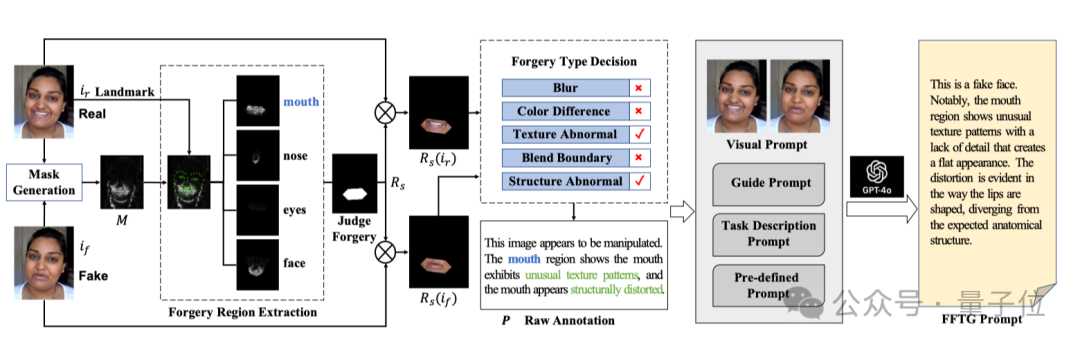
△图3:FFTG标注流程
FFTG 标注流程主要分为两个核心阶段:原始标注生成 (Raw Annotation Generation) 和 标注优化 (Annotation Refinement)。
第一阶段:原始标注生成
在这一阶段,FFTG利用真实图像和对应的伪造图像,通过精确的计算分析生成高准确度的初始标注:
1、掩码生成 (Mask Generation):
-
通过计算真实图像和伪造图像之间的像素级差异,生成伪造掩码 M
-
掩码值被归一化到 [0,1] 范围,突显操作强度较大的区域
2、伪造区域提取 (Forgery Region Extraction):
-
基于面部特征点将人脸划分为四个关键区域:嘴部、鼻子、眼睛和整个脸部
-
计算每个区域内掩码 M 的平均值,并设置阈值 θ 判断该区域是否被篡改
-
形成伪造区域列表,并从中随机选择一个区域进行下一步分析
3、伪造类型判定 (Forgery Type Decision): 设计了五种典型的伪造类型判断标准:
-
颜色差异 (Color Difference):通过 Lab 色彩空间中的均值和方差差异检测
-
模糊 (Blur):使用拉普拉斯算子量化局部模糊程度
-
结构异常 (Structure Abnormal):使用 SSIM 指数衡量结构变形
-
纹理异常 (Texture Abnormal):通过灰度共生矩阵 (GLCM) 对比度衡量纹理清晰度
-
边界融合 (Blend Boundary):分析融合边界的梯度变化、边缘过渡和频域特征
4、自然语言描述转换:
-
将识别出的伪造区域和类型转换为自然语言表达
-
如”Texture Abnormal”转换为”lacks natural texture”,”Color Difference”转换为”has inconsistent colors”
此阶段生成的原始标注虽然结构相对固定,但准确度极高,为后续优化提供了可靠基础。
第二阶段:标注优化
为增加标注的多样性和自然流畅性,FFTG 使用多模态大语言模型(如 GPT-4o-mini)进行标注优化,同时设计了全面的提示策略防止幻觉:
1、视觉提示 (Visual Prompt):
-
将真实和伪造人脸图像作为配对输入提供给大模型
-
这种对比方式使模型能通过直接比较识别伪造痕迹,减少幻觉
-
保持伪造检测视角,避免生成与伪造无关的描述
2、指导提示 (Guide Prompt):
-
将前一阶段生成的原始标注作为指导提供给大模型
-
附带详细解释每种伪造类型的判定标准(如纹理异常是如何通过 GLCM 分析确定的)
-
强化技术依据,减少主观臆断
3、任务描述提示 (Task Description Prompt):
-
设定专家级伪造检测任务情境
-
提供分析视觉证据和生成综合描述的具体要求
-
引导模型进行逐步推理
4、预定义提示 (Pre-defined Prompt):
-
规定输出格式(如 JSON 结构)
-
要求包含特定短语(如”This is a real/fake face”)
-
确保不同样本的标注格式一致
下游微调:双路模型训练策略
有了高质量的图文标注数据,接下来的问题是:如何充分利用这些数据来训练模型?研究团队提出了两种不同的训练策略,分别针对CLIP架构和多模态大语言模型(MLLM),注意本文的目的主要是验证数据的有效性,所以才去了相对简单的微调方式:
CLIP三分支训练架构
对于CLIP这类经典的双塔结构模型,团队设计了一种三分支联合训练框架,如图4所示。
这种训练方法结合了单模态和多模态的学习目标:
1、图像特征分类(Image Feature Classification):直接使用图像编码器提取的特征进行真伪二分类,保证模型在纯视觉输入下的基本检测能力。
2、多模态特征对齐(Multimodal Feature Alignment):通过对比学习,使图像特征和对应的文本特征在表示空间中对齐,并且激活CLIP预训练时获得的跨模态理解能力。
3、多模态特征融合分类(Multimodal Feature Classification):通过注意力机制融合视觉和文本特征,引导模型学习跨模态的伪造证据整合能力
这三个分支的损失函数共同优化,使模型既能独立运行,又能充分利用文本信息来增强检测能力。
MLLM微调方法
对于如LLaVA这类多模态大语言模型,采用了一种更为直接的微调方法:
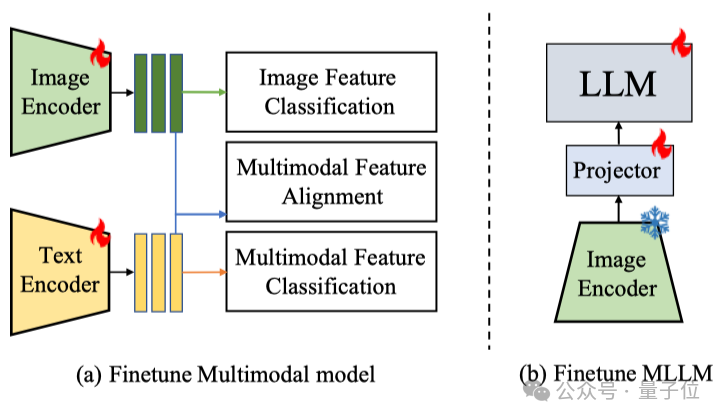
△图4:MLLM微调架构
MLLM通常由三部分组成:视觉编码器、对齐投影器和大语言模型。策略是:
-
固定预训练好的视觉编码器参数,专注于微调对齐投影器和大语言模型部分
-
设计简洁有效的提示模板:”Do you think this image is of a real face or a fake one? Please provide your reasons.”
-
这种双部分提示不仅引导模型做出二分判断,还要求提供可解释的理由。
实验:多维度验证FFTG的有效性
为了全面评估提出的方法,团队在多个伪造检测基准数据集上进行了广泛实验,包括FaceForensics++、DFDC-P、DFD、CelebDF等。
标注质量评估
首先,比较了不同标注方法的质量:

△表1:不同标注方法的质量对比
结果表明,FFTG在所有指标上都显著优于现有方法。特别是在精度上,FFTG比人工标注高出27个百分点,比直接使用GPT-4o-mini高出28个百分点,证明了该研究的掩码引导和结构化提示策略能有效减少”幻觉”问题。
跨数据集泛化能力评估
在FF++数据集上训练模型,并在其他四个未见过的数据集上测试,评估方法的泛化能力:
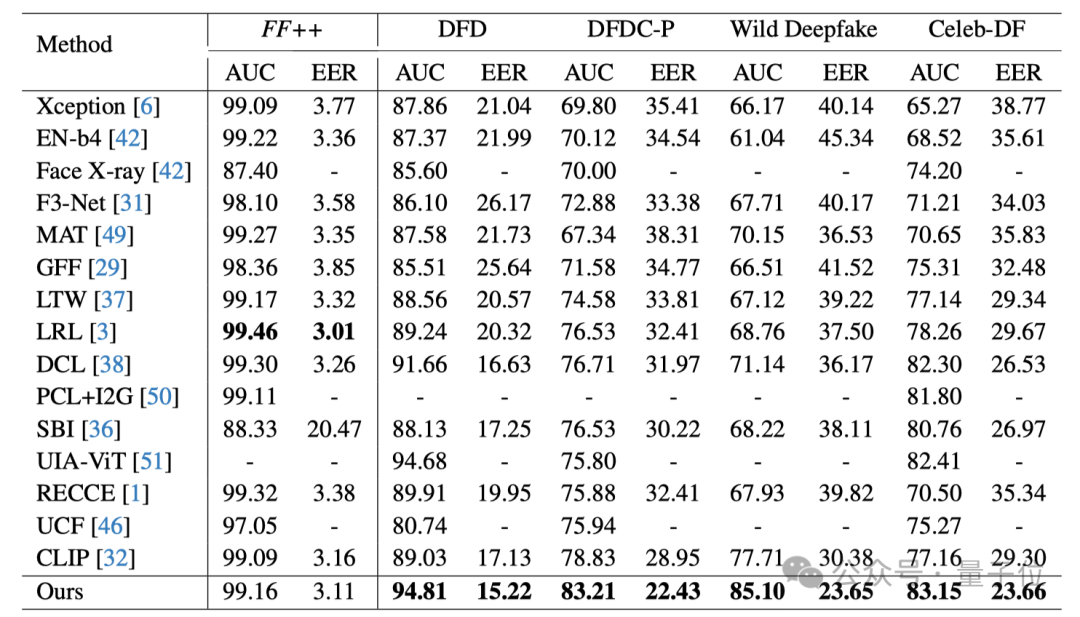
△表2:跨数据集泛化性能对比
在所有未见过的数据集上,该研究的方法都取得了性能提升。
可视化分析
团队对模型的注意力机制进行了可视化分析,进一步验证了FFTG的有效性:

△图5:不同方法的注意力可视化对比
可以看到,使用FFTG标注训练的模型能够更精确地关注真正的伪造区域,而基线方法的注意力更为分散或错位。例如,在NeuralTextures的例子中,该方法准确聚焦在嘴部区域的微妙变化,而其他方法则在未被篡改的区域产生错误激活。
总结
语言模态让伪造检测任务不止停留在“看得见”,更能“讲得清”。
如果你也关注伪造检测的可解释性和泛化性,欢迎进一步了解。为了方便社区复现与研究,团队已经将标注流程和生成数据集开放:https://github.com/skJack/VLFFD
文章链接:
https://arxiv.org/pdf/2502.20698
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)