
人眨了一下眼 —— 约 0.3 秒

东西从茶几上落下 —— 约 0.3 秒

为了严谨,我真的去测算了
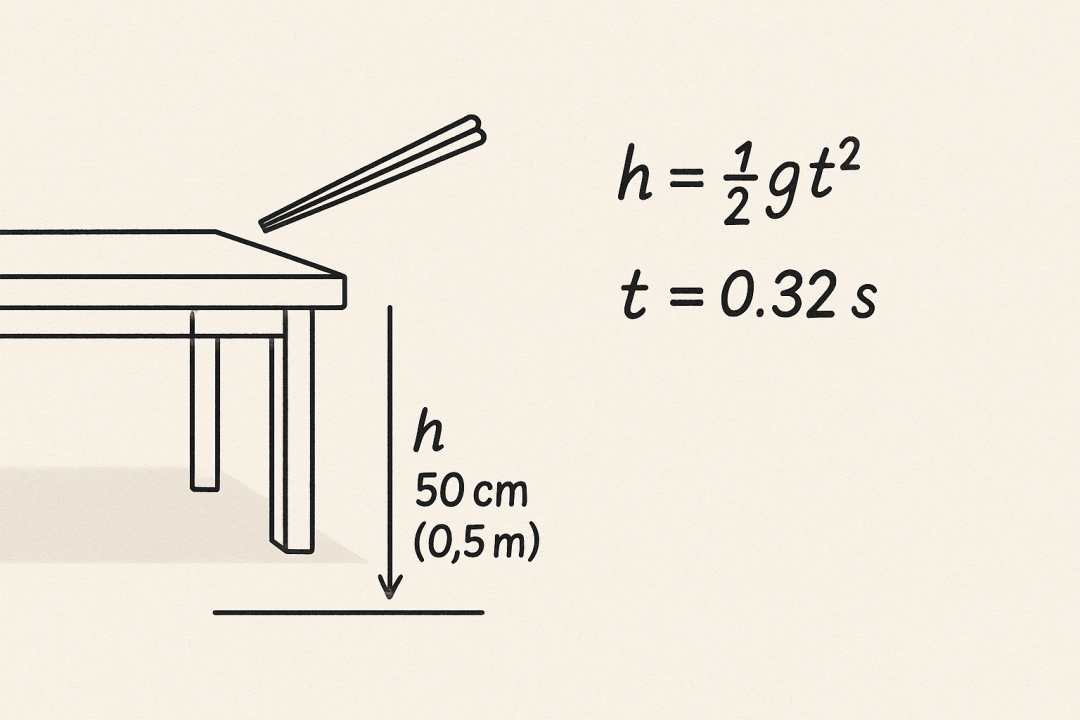
然后,视线从键盘移到屏幕 —— 0.3 秒,Z1 已刷屏了回答
当快到这个程度,人是反应不过来的。
这,就是瞬时模型。
首款“瞬时模型”
0.3 秒,是神经反射所需时间,也是人的「瞬间」
Z1-AirX 是首个国内大模型厂商提供的“瞬时模型”,这里有两个指标:
-
• 在 0.3 秒内,完成首响应,相当于一次神经反射或眨眼的时间。 -
• 在 0.3 秒内,能够完成 50+ 个汉字生成,等效于一条完整回复、一段语音内容,或一则朋友圈的长度。 -
• 非过度压缩的极小模型(比如 1.5B)
于是,我们见证了一个改变:从“提出问题—等待回应”的线性节奏,变成输入与输出同步发生的即时对话。

速度改变一切
正常情况下,AI 的响应时间通常在 1~3 秒之间,生成速度约为 20 tokens/s。这意味着,用户在输入结束后,会经历短暂的等待期,模型随后才开始输出。这种延迟在多轮交互中被频繁放大,造成明显的思维中断。
而 Z1-AirX,改变了这种交互:
-
• 延迟低于感知阈值。用户在完成输入的瞬间几乎同步获得反馈,交互节奏从“输入后等待”转变为“输入即响应”。 -
• 生成即时显现。输出不再是可感知的“逐步生成”,而是直接呈现为完整段落,极大减少了等待中的认知空白。 -
• 对话节奏一致。语言回合之间无明显停顿,避免语境断裂。
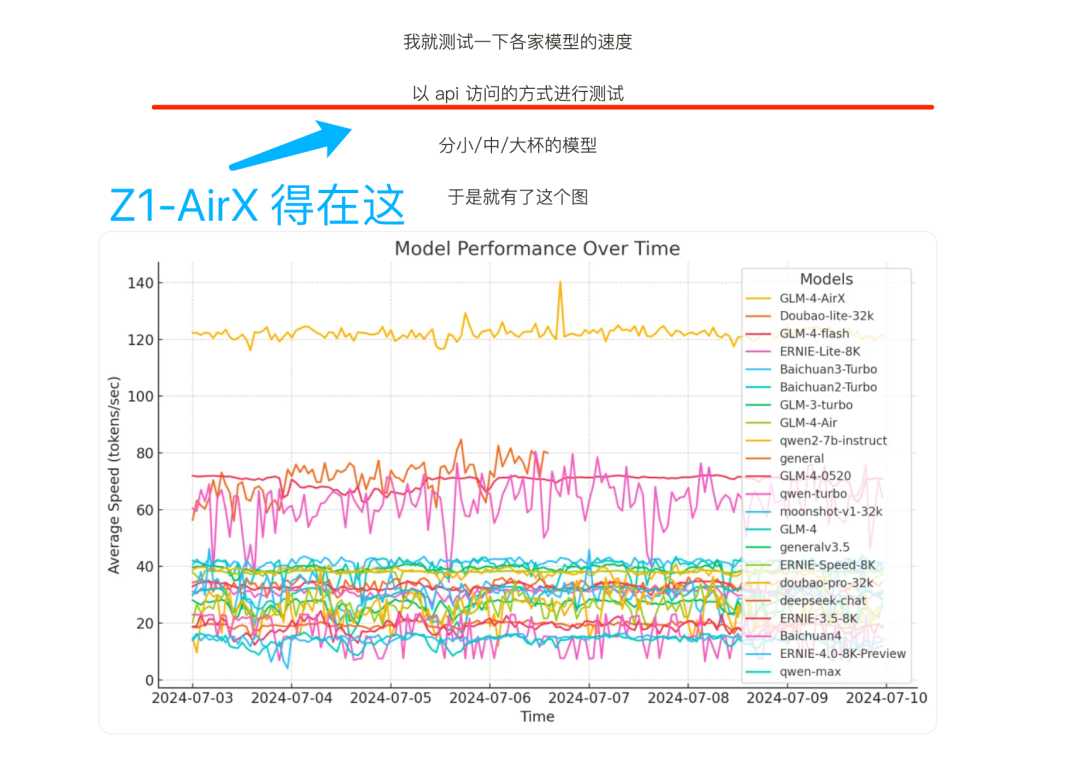
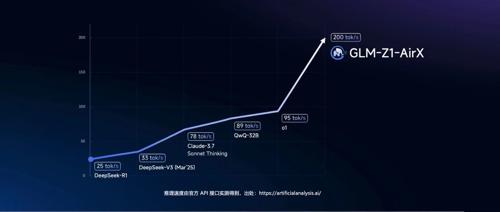
⬆️上面这个图,是我去年测的(当时air就遥遥领先):
大模型真实速度一览(附:测试脚本)
另一角度,速度的变化扩展了大模型的应用范围,在实时任务中尤其明显:
-
• 教育场景下,学生注意力有限。问答、批改与反馈等任务中,需要在学生注意力窗口期中给出响应:0.3 秒以内的反馈,让模型有了在课堂和练习中直接介入的可能。 -
• 客服场景下,低延迟、告诉生成让用户感觉到“真实感”。在对话中保持低延迟和高吞吐,有助于稳定交互节奏,避免因卡顿造成用户退出或任务中断。 -
• 文案协作、脚本生成中,告诉让人不被打断。减少等待感,流畅撰写。 -
• 在 Agent 调用中,快速完成意图识别、工具调用和结果聚合。让 agent 走入工业成为可能。
这些场景下,以往以来特定模型或特殊优化。而 Z1-AirX 带来了另一种思路:只要速度够快,就能跨越边界。
现已可用

Z1 今天已可以调用,通过智谱开放平台 bigmodel.cn 有三个版本:
-
Z1-AirX(极速版) 速度达 200 tokens/s,5 元 / M token -
Z1-Air(高性价比版) -
约 50 tokens/s ,0.5 元 / M token -
Z1-Flash(免费版) 免费
Instant is All You Need
称 Z1-AirX 为“瞬时模型”,是因为它突破了“大模型必须等待”的范式,让 AI 节奏真正接近人类。
可以期待,更多模型会跨越这条临界线:真正的智能,不该让人等待
(文:赛博禅心)