

本周对AI来说可谓是疯狂的一周。
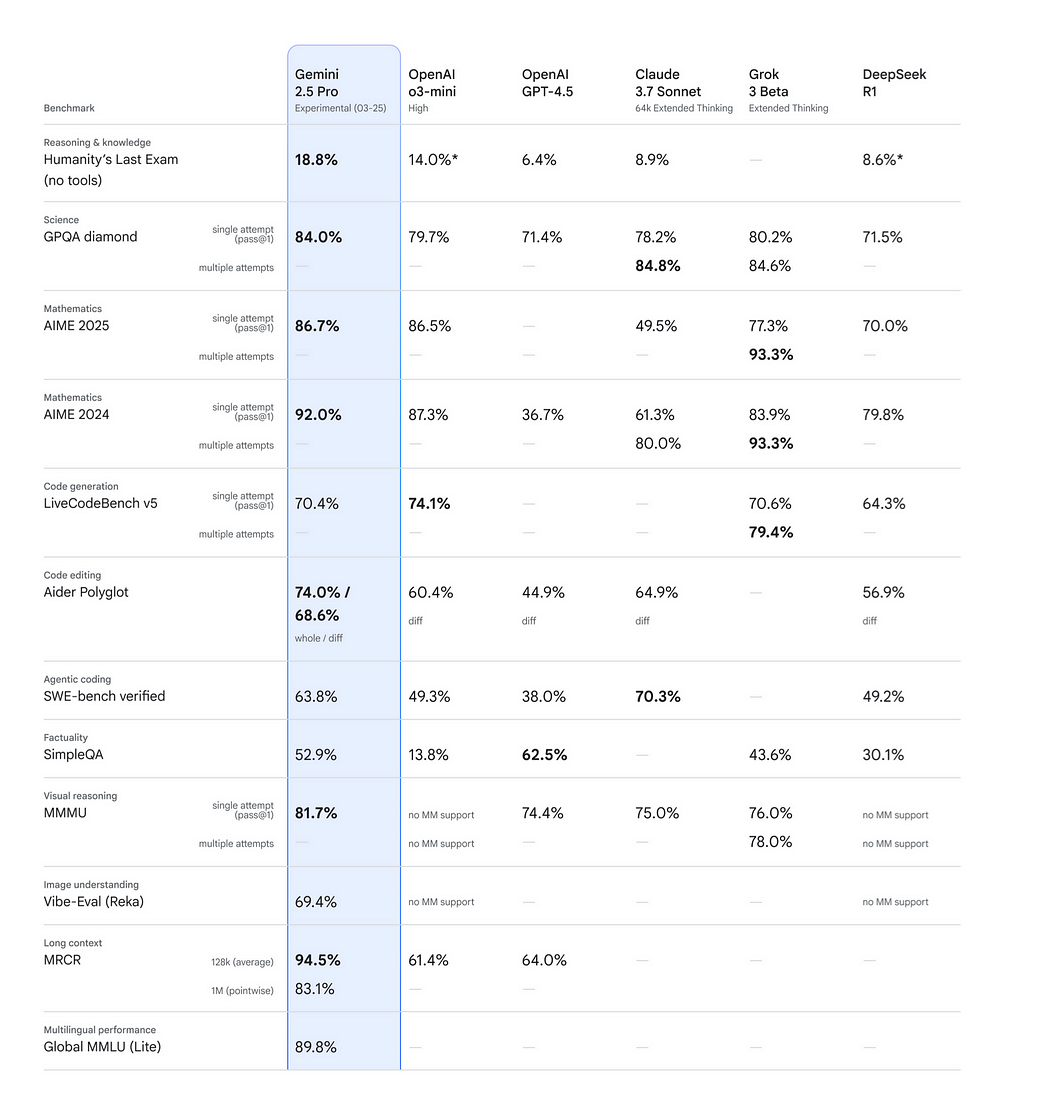
DeepSeek V3-0324 刚刚发布,从基准测试来看,它是目前最强的AI模型,甚至超越了像 Grok 3 这样的推理模型。
几天后,谷歌又推出了 Gemini 2.5 Pro,再次在基准测试中超越了所有其他模型。
随着这些新模型的不断推出,大家都在问同一个问题:
“哪个是最适合编程的模型?”
这是我们集体关注的焦点。
本文将通过一个真实的前端开发任务来探索这个问题。
任务准备
为了让 LLM 顺利完成任务,我们需要提供足够的信息。下面是我们的准备方式。
背景介绍:我正在构建一个算法交易平台,其中一个核心功能名为 “Deep Dives”,它是由 AI 生成的全面尽职调查报告。
尽管我已经将这个功能发布上线,但它还没有一个经过 SEO 优化的入口。因此,我决定测试一下各大顶级 LLM 能否为这个功能生成一款优秀的落地页。
测试方法:
-
编写系统提示词,提供足够的上下文,让模型能够一键生成解决方案。
-
所有模型使用相同的系统提示词,以确保公平对比。
-
仅凭我的主观感受,评估前端页面的视觉效果和质量。
我首先从系统提示词开始。
构建完美的系统提示词
为了打造高质量的系统提示词,我采取了以下步骤:
-
提供 Markdown 版的文章,让模型理解这个功能的背景和作用。
-
提供代码示例,让模型知道要生成页面的关键组件。
-
列出约束与需求,例如,我希望用户可以直接从落地页生成报告,并在提示词中明确说明这一点。
-
撰写详细的目标说明,明确我们希望构建的内容。
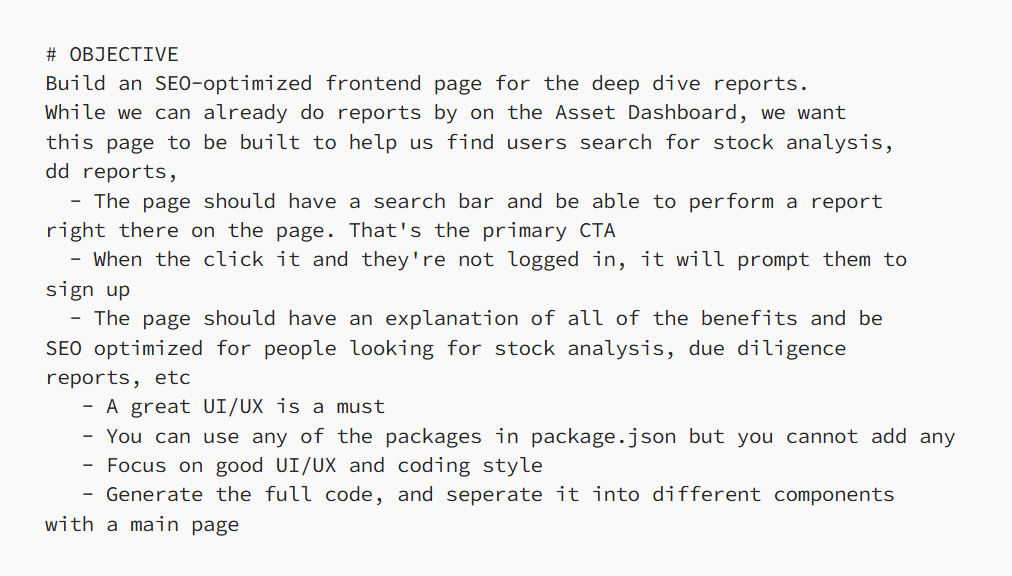
完整版提示词可以加群免费获取。
接下来,我使用这个提示词,对顶级大模型的输出进行测试,包括:
-
Grok 3
-
OpenAI o1-pro
-
Gemini 2.5 Pro
-
DeepSeek V3
-
Claude 3.7 Sonnet
以上排序是我按测试结果从差到优的顺序排列的。
那么,让我们从这四个模型中表现最差的开始:Grok 3。
测试 Grok 3 在真实前端任务中的表现
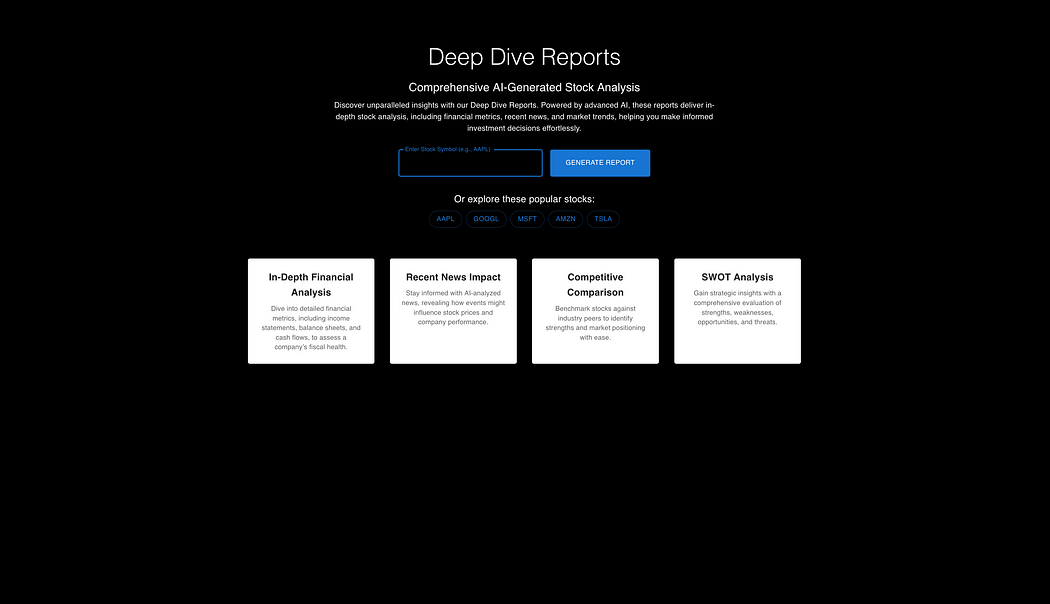
说实话,尽管我对 Grok 3 抱有很高的期望(因为它在其他复杂的编程推理任务中表现不错),但在这个任务中,它的表现却相当普通。
它生成的代码水平,大概也就是 GPT-4 的水平,完全没有展现出任何特别之处。
看看这个页面就知道了——这根本不是一个经过 SEO 优化的页面,说实话,谁会用这样的页面呢?
相比之下,GPT o1-Pro 表现稍好一点,但也没有好太多。
测试 GPT o1-Pro 在真实前端任务中的表现
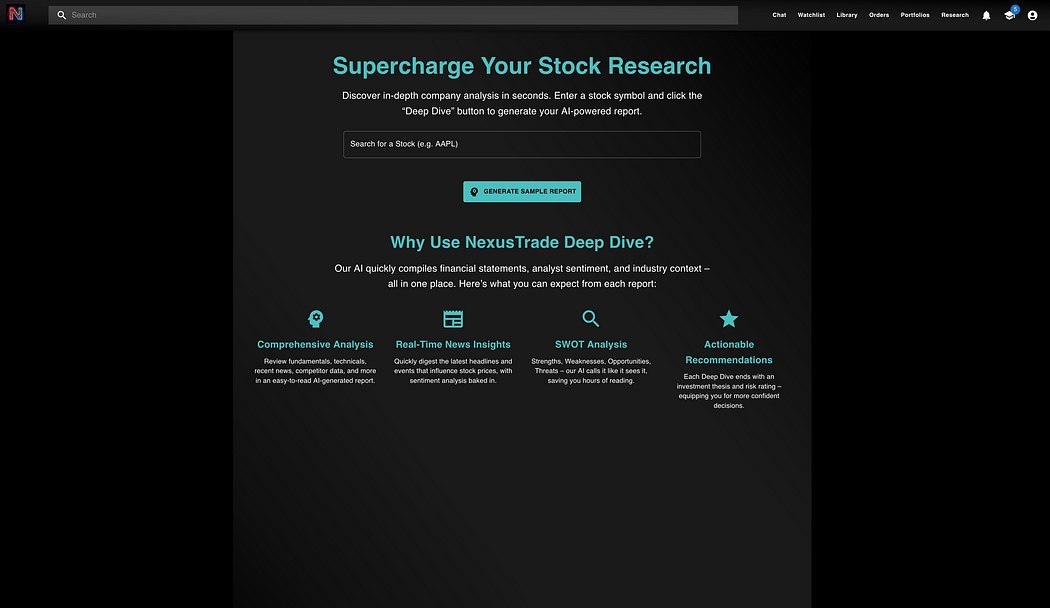
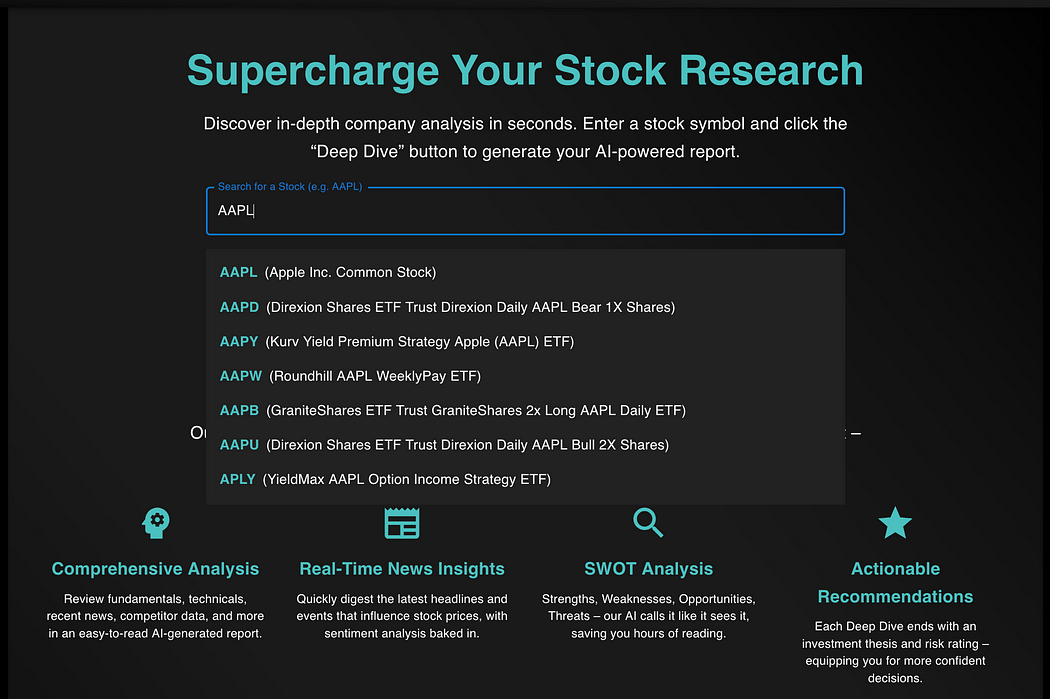
它还能正确使用我提供的图标库,格式化方面也基本在线。
但问题是——这远远达不到生产级别的标准。无论是 Grok 3 还是 o1-Pro,它们的输出水平都像是刚上“Web开发入门”课程的实习生写出来的。
不过,接下来的模型表现要好得多。
测试 Gemini 2.5 Pro Experimental 在真实前端任务中的表现


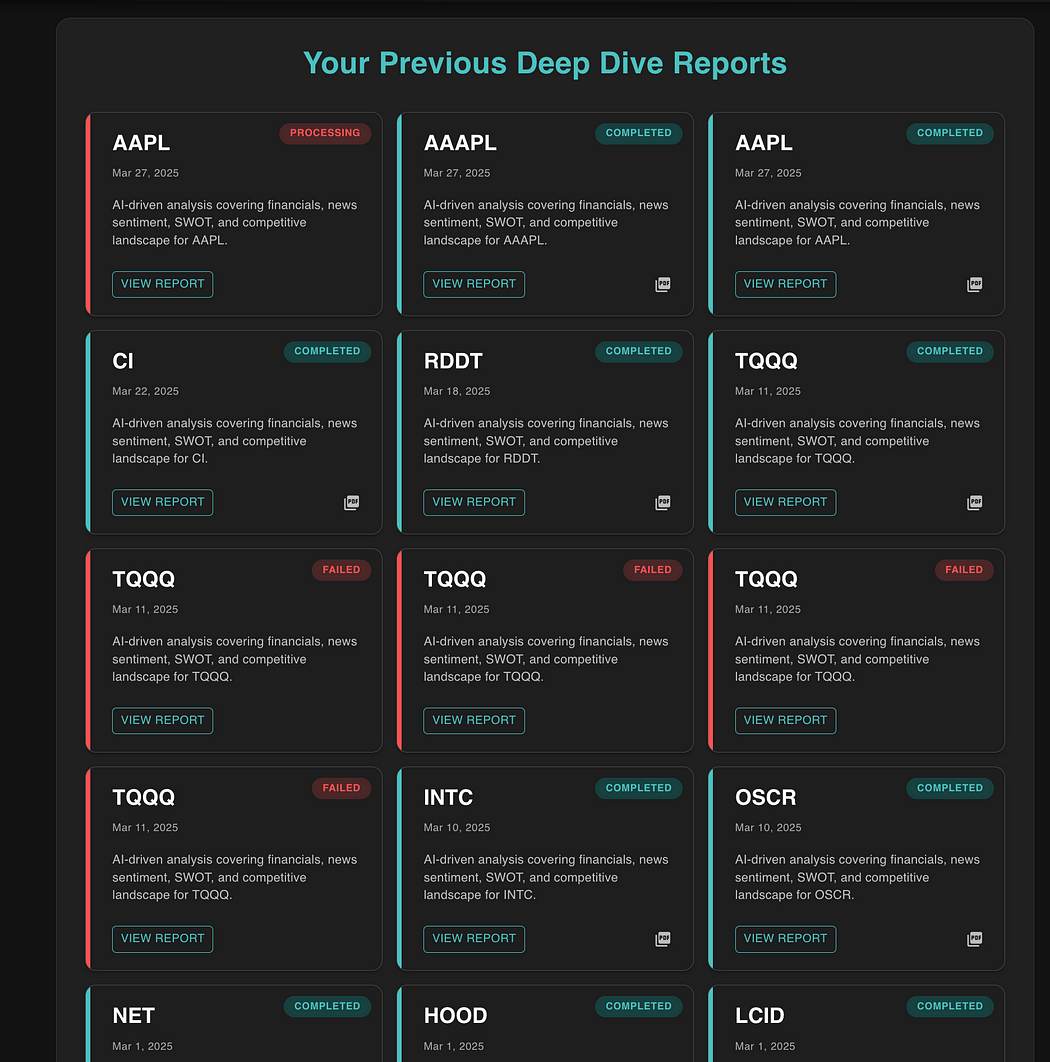
在看到这个结果后,我本以为它会是这次测试的最佳模型……
直到我看到了 DeepSeek V3-0324 的表现。
测试 DeepSeek V3-0324 在真实前端任务中的表现



DeepSeek V3-0324 的表现远超我的预期。作为一个非推理型模型,它的输出却极其全面。
页面不仅包含了精美的英雄区(Hero Section),还提供了惊人的细节,甚至还添加了用户推荐(Testimonial)部分,整体完成度极高。
看到这里,我已经对这些模型的进步感到震撼,并且几乎笃定——DeepSeek V3-0324 会是最终的赢家。
直到我测试了 Claude 3.7 Sonnet……结果让我彻底惊呆了。
测试 Claude 3.7 Sonnet 在真实前端任务中的表现


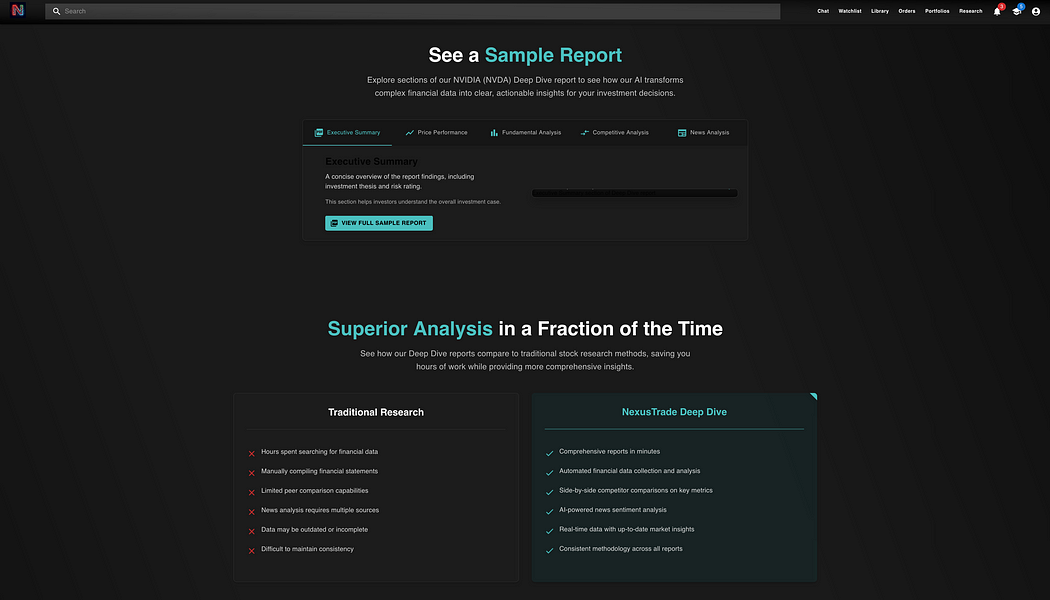

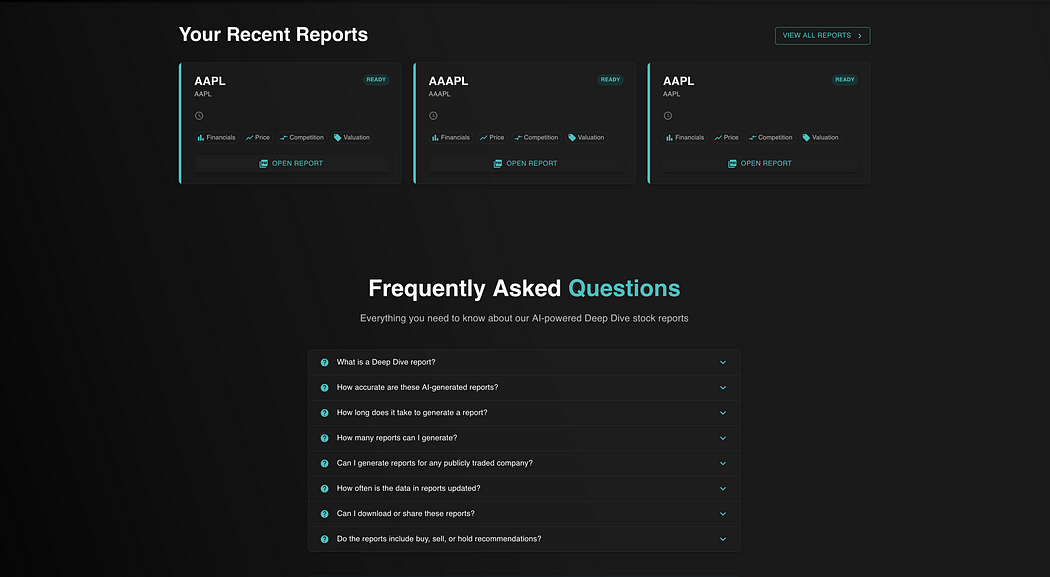
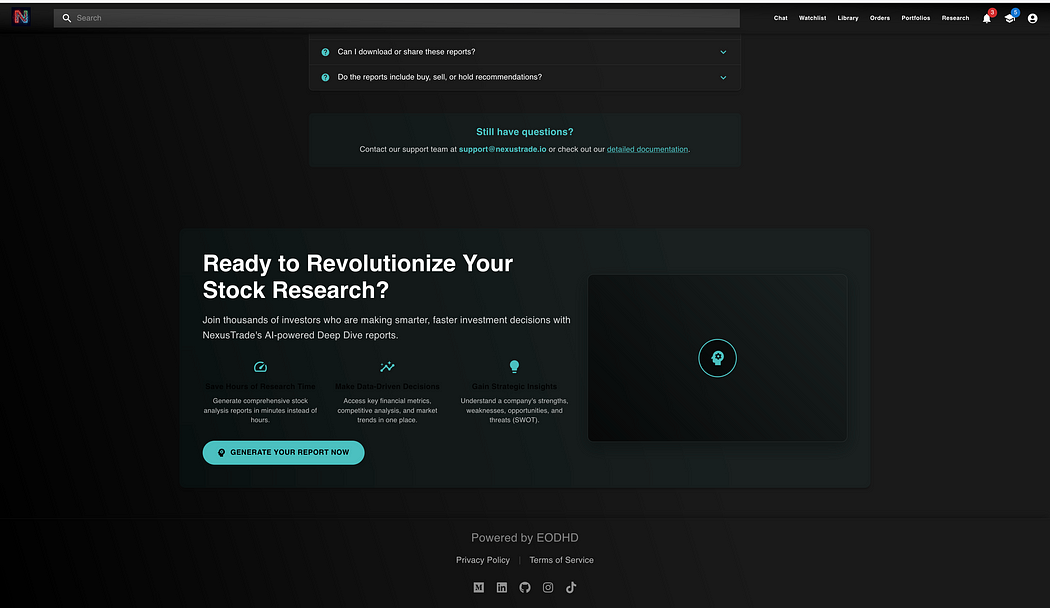
在相同的提示词下,Claude 3.7 Sonnet 生成了一个极其复杂且符合我所有要求的前端落地页,甚至超出了预期。
它不仅允许用户直接在 UI 界面上生成报告,还额外提供了全新的组件,详细介绍了功能、SEO 优化文本、完整的功能描述、用户推荐部分等等。
这不仅仅是完整,而是“超完整”。
不仅仅是视觉效果:代码质量分析
尽管这些落地页在视觉呈现上都非常优秀,但代码层面也值得深入讨论。
1. 组件复用情况
不同模型在使用共享组件和库方面表现不同。例如:
-
DeepSeek V3-0324 和 Grok 3 未正确实现
OnePageTemplate(负责页眉和页脚的组件)。 -
o1-Pro、Gemini 2.5 Pro 和 Claude 3.7 Sonnet 正确复用了这些模板,让代码更加规范和一致。
2. 代码质量
所有模型的代码整体上都干净、可读性强,命名规范且结构清晰,没有明显的错误。这说明它们在代码编写方面已经相当成熟。
3. 移动端适配
由于我使用的是 Material UI,所有模型都成功生成了适用于移动端的代码,保证了良好的跨设备用户体验。
4. Claude 3.7 Sonnet 的独特优势
Claude 3.7 Sonnet 生成的代码量最多,但同时仍然保持了高可维护性。它不仅提供了更多组件和功能,而且代码结构良好,无缝集成到现有项目中。
结果分析:模型的成本 & 选择建议
尽管 Claude 3.7 Sonnet 在代码质量上无可挑剔,但在选择模型时,开发者还需要考虑其他因素,如成本、速度和使用场景。
1. 代码质量 vs. 价格
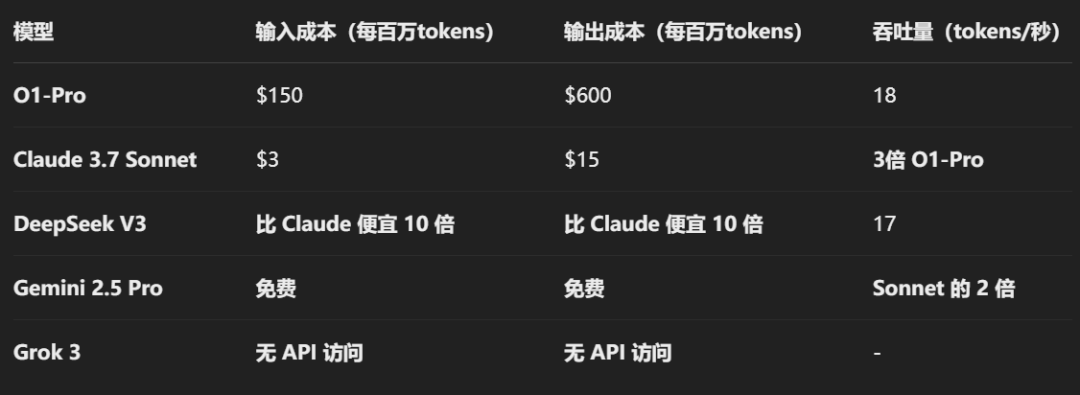
2. 选型指南
-
如果你追求最好的代码质量,选择 Claude 3.7 Sonnet。
-
如果你在意速度和成本,选择 Gemini 2.5 Pro(免费且最快)。
-
如果你有预算限制,或需要 API 访问,选择 DeepSeek V3-0324(成本最低)。
总结:Claude 3.7 Sonnet 是最佳选择吗?
在这次测试中,Claude 3.7 Sonnet 无疑是代码质量最好的模型,它在技术理解和设计美感上的表现超越了其他对手,提供了完整的用户体验——包括用户推荐、功能介绍、SEO 优化文本,以及一个真正可用的落地页。
但与此同时,DeepSeek V3-0324 的出色表现也表明,开源模型的差距正在迅速缩小。
当然,这篇文章只是我的主观评价。你是否同意 Claude 3.7 Sonnet 的表现?你觉得哪个模型的结果最合理?欢迎在评论区讨论!
https://medium.com/codex/i-tested-out-all-of-the-best-language-models-for-frontend-development-one-model-stood-out-f180b9c12bc1
(文:PyTorch研习社)