


-
论文标题:Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
-
论文地址:https://arxiv.org/pdf/2503.09573
-
项目主页:https://m-arriola.com/bd3lms/


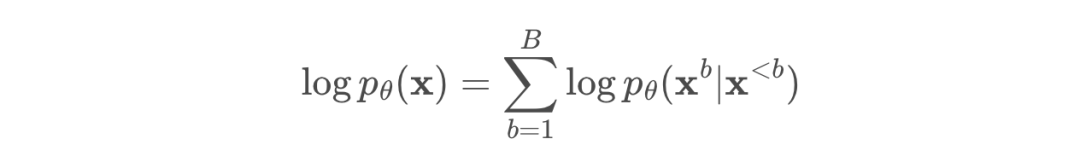
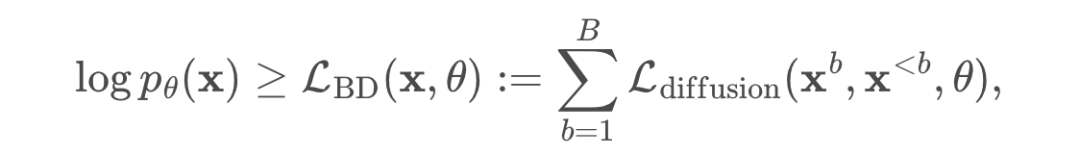
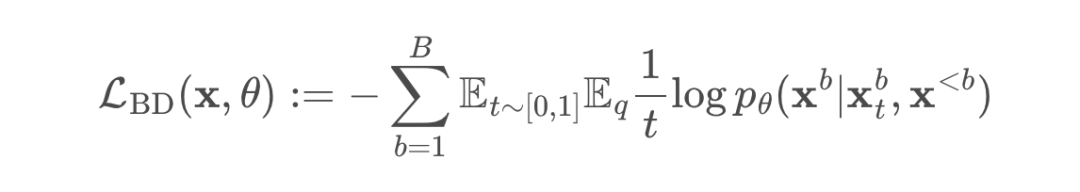
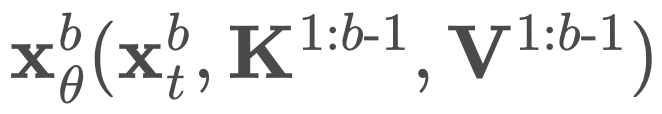 B 次来计算 logits。不过,他们只需要两次前向传递。第一次传递分别预计算完整序列 x 的键和值 K^1:B、V^1:B,在第二次前向传递中使用
B 次来计算 logits。不过,他们只需要两次前向传递。第一次传递分别预计算完整序列 x 的键和值 K^1:B、V^1:B,在第二次前向传递中使用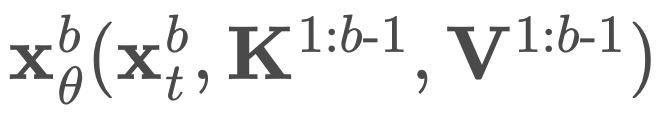 同时计算所有块的去噪预测。
同时计算所有块的去噪预测。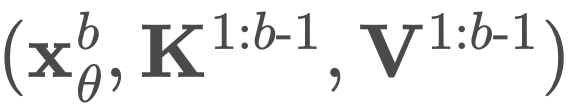 中进行采样。来从条件分布 pθ
中进行采样。来从条件分布 pθ 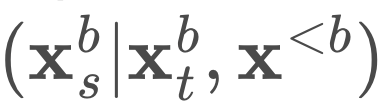

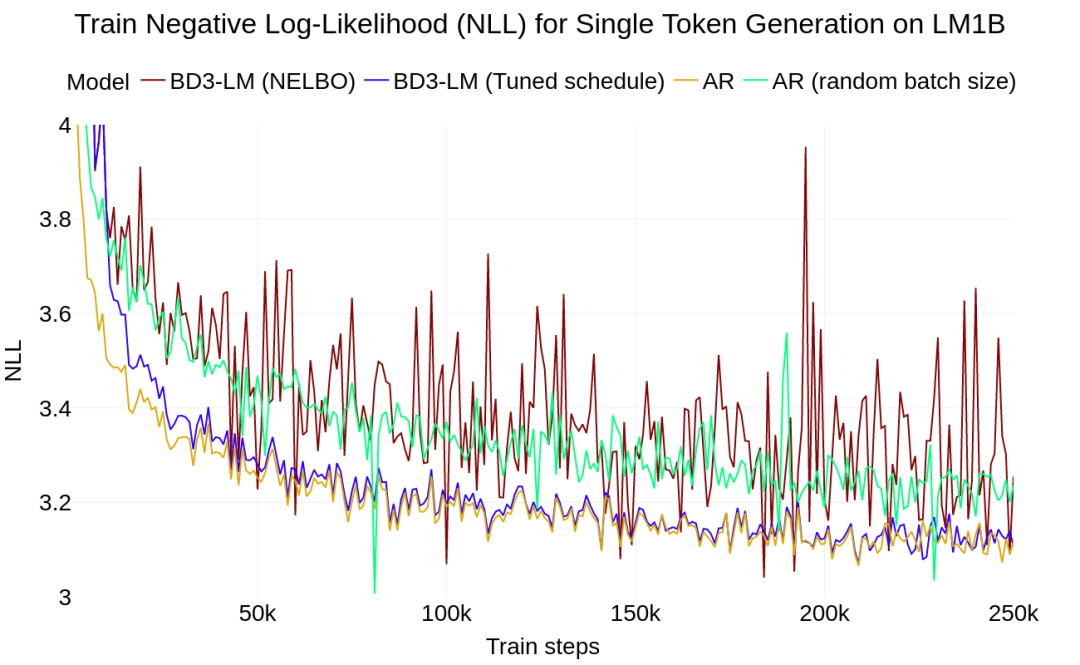
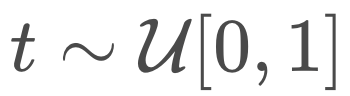 过低,重构 x 会变得容易,这不能提供有用的学习信号。如果掩码全部内容,最优的重构就是数据分布中每个标记的边际概率,这很容易学习,同样也没有用处。
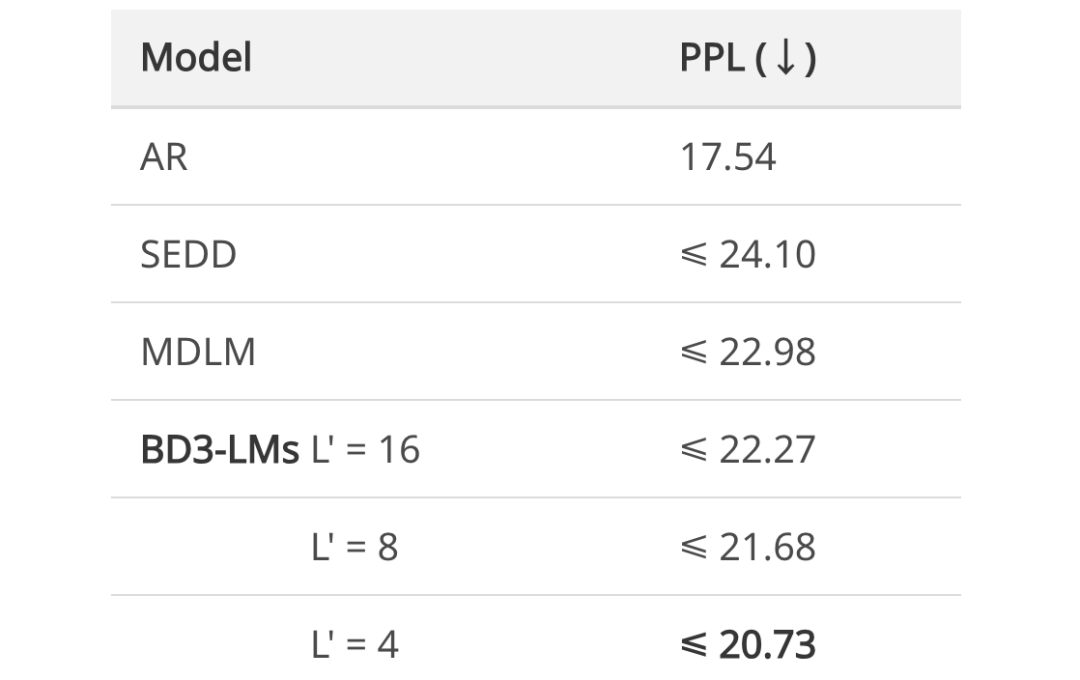
过低,重构 x 会变得容易,这不能提供有用的学习信号。如果掩码全部内容,最优的重构就是数据分布中每个标记的边际概率,这很容易学习,同样也没有用处。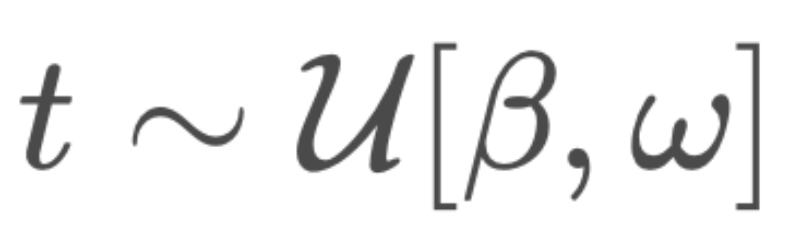 下来训练 BD3-LMs。通过降低训练方差,研究者在均匀采样的掩码率评估下改善了似然度。
下来训练 BD3-LMs。通过降低训练方差,研究者在均匀采样的掩码率评估下改善了似然度。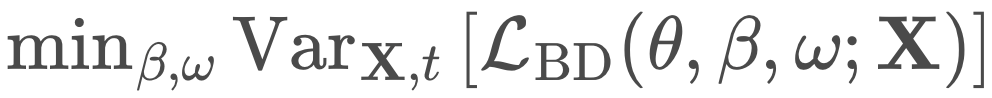 。
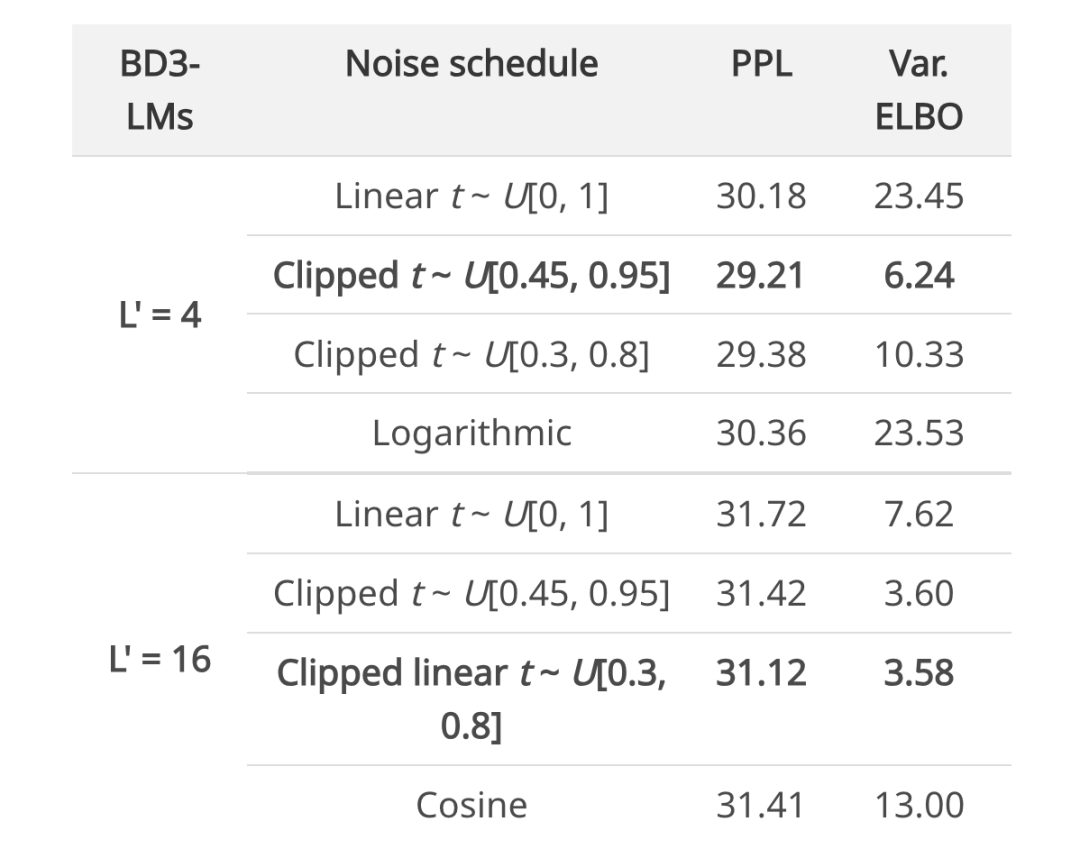
。
(文:机器之心)