

昨天DeepSeek连续5天开源第一天就拿出了杀器。
FlashMLA才开源了1天,在GitHub就有9000颗星了。

猛自然是有猛的道理,榨干GPU的性能像是DeepSeek最近几天开源的目标一样。
今天是DeepSeek开源的第二天,这才几个小时过去,GitHub的星星也已经到了3900。
估计各AI大厂最近一周是不用休息了,快点加班研究吧,人家为什么能横空出世。
一起来看看今天开源的是什么好东西。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
DeepEP是一个专为混合专家(MoE)和专家并行(EP)设计的高效通信库。它提供了高吞吐量、低延迟的全连接GPU内核,支持低精度操作,并优化了NVLink和RDMA之间的数据转发。DeepEP特别适用于训练和推理任务,能处理大规模并行计算需求。它还通过RDMA支持低延迟内核,并引入基于钩子的通信计算重叠方法,避免占用SM资源。
总之就是快!快!快!
竭尽所能的榨干GPU性能。
就目前的开源的两个项目来看,可是比OpenAI当时连续的十几天发布会精彩多了。
当时OpenAI的发布会可是很多博主更了一天,第二天就不会写了。
技术特点
DeepEP的强大之处已经帮大家整理好了。
1.高效的通信架构
DeepEP采用了高吞吐量、低延迟的全连接GPU内核,这使得数据在多个GPU之间传输时能够更高效地进行。其设计可以在大规模并行计算中提供稳定的性能,尤其是在训练和推理任务中,避免了传统通信方法所带来的瓶颈。它能够确保计算任务快速且顺畅地分发到不同的处理单元,提升了整体系统的效率。
2. 支持低精度计算(FP8)
DeepEP支持低精度操作,如FP8(8-bit浮点数),这对于大规模深度学习模型尤其重要。低精度计算能够显著提高计算速度,并减少内存占用,从而有效缩短训练时间并节省硬件资源。与传统的32-bit精度计算相比,FP8能够在不牺牲模型精度的情况下提升效率,尤其适合处理海量数据的训练任务。
3. 优化的NVLink和RDMA数据转发
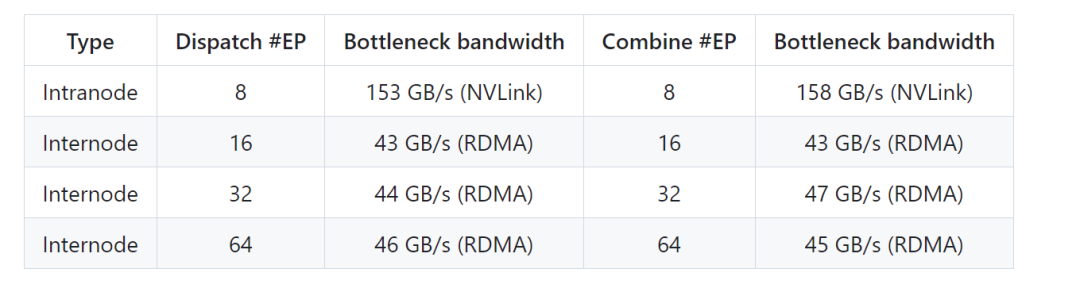
DeepEP在硬件层面进行了优化,特别是在数据转发的方式上。通过优化NVLink(NVIDIA的高带宽互联技术)和RDMA(远程直接内存访问)之间的数据传输,DeepEP能够在低延迟下进行高效的数据交换。这使得多个GPU在分布式训练中能够快速共享数据,减少了通信延迟,提高了训练效率。
4. 基于钩子的通信计算重叠
DeepEP引入了基于钩子的通信计算重叠方法。这意味着在进行计算时,通信任务能够并行进行,避免了计算过程中的资源浪费。例如,网络传输数据的同时,GPU计算也可以继续进行。这种并行机制不仅能够提高GPU的计算效率,还能减少等待时间,从而提升整体系统的性能。
使用要求
-
Hopper GPU
-
Python 3.8 及更高版本
-
CUDA 12.3 及以上版本
-
PyTorch 2.1 及更高版本
-
NVLink 用于节点内通信
-
用于节点间通信的 RDMA 网络
很期待接下来几天DeepSeek的大招。
开源社区最近因为DeepSeek又热闹了起来,而且还是国产的。
AI行业越来越热,从业者们也会越来越有干劲。
项目链接
https://github.com/deepseek-ai/DeepEP
关注「开源AI项目落地」公众号
(文:开源AI项目落地)