
Datawhale分享
开源周:Day 02,编辑:Datawhale
信息来源|X,机器之心,APPSO

「很高兴向大家介绍 DeepEP——首个专为 MoE(专家混合)模型训练和推理打造的开源 EP 通信库。
✅ 高效优化的全对全(all-to-all)通信
✅ 支持节点内(intranode)和节点间(internode)通信,兼容 NVLink 和 RDMA
✅ 训练与推理预填充(prefilling)阶段的高吞吐率计算核
✅ 推理解码(decoding)阶段的低延迟计算核
✅ 原生支持 FP8 数据调度
✅ 灵活的 GPU 资源控制,实现计算与通信的重叠处理」
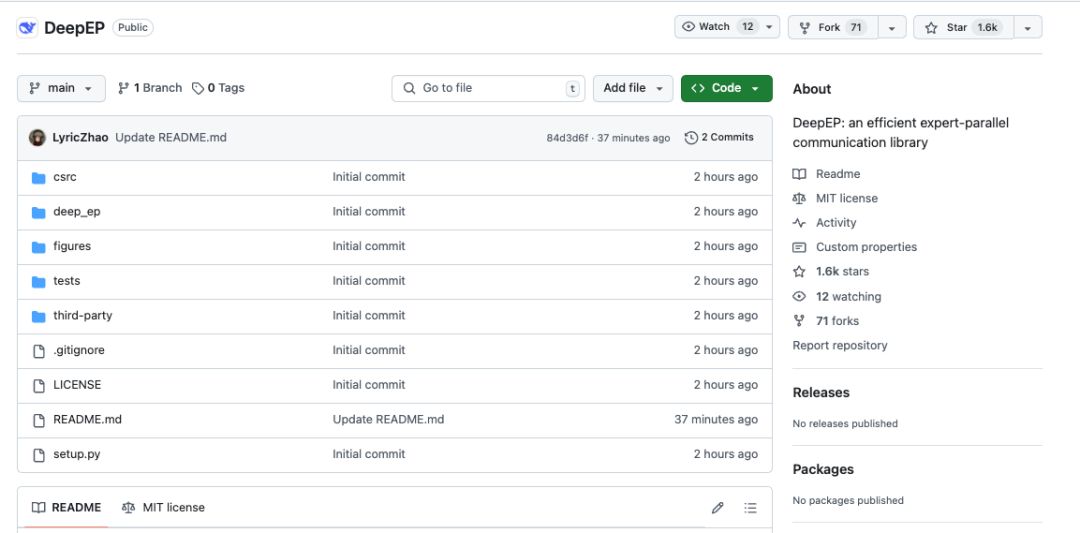
说人话就是,DeepEP 是 MoE 模型的「通信管家」,通过软硬件协同优化,让专家之间的数据传递又快又省资源,大幅提升训练和推理效率。
另外,DeepEP 为支持 DeepSeek-V3 论文中的组限门控(group-limited gating) 算法,开发了专门的计算模块,这些模块能够高效处理不同网络连接之间的数据传输,比如从 GPU 之间的 NVLink 连接传输到服务器之间的 RDMA 连接。
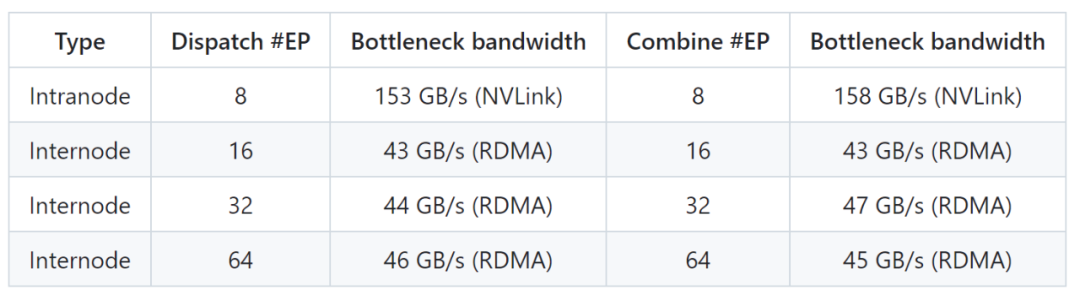
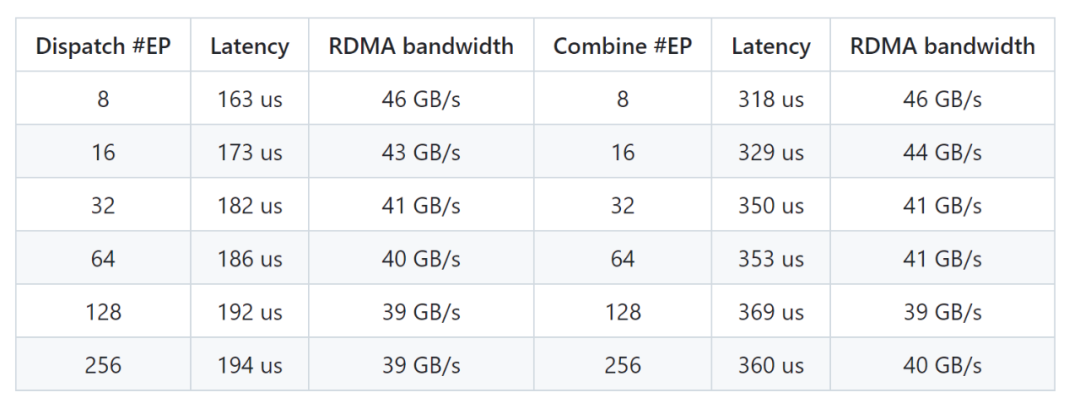
DeepEP 提供了两种主要类型的计算模块。
一种是高吞吐量模块,它们在训练和推理预填充阶段表现出色,并且可以灵活调整 GPU 处理器资源;另一种是专为推理解码阶段设计的低延迟模块,完全基于 RDMA 技术,能够最大限度减少响应时间。
 一起“点赞”三连↓
一起“点赞”三连↓
(文:Datawhale)