

Qwen2.5-VL可以识别超过1小时的长视频了。Qwen2.5-VL 已经发布了,目前官方放出来3个大小的模型:
-
Qwen2.5-VL-72B-Instruct-AWQ -
Qwen2.5-VL-7B-Instruct-AWQ -
Qwen2.5-VL-3B-Instruct-AWQ
这次的主要提升有:
-
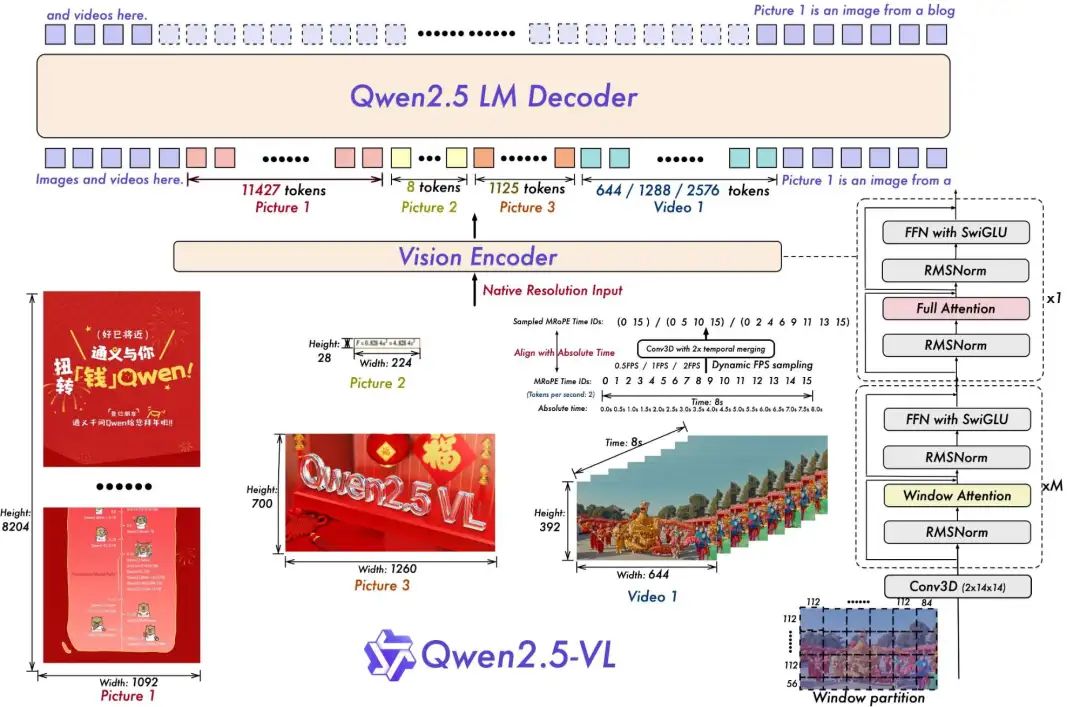
视觉理解:提高了图像中识别和分析对象,文本,图表和布局的能力。 -
代理功能:充当能够推理并与工具动态交互的视觉 Agent(例如,使用计算机或电话)。 -
长期的视频理解:可以了解超过1小时的视频,并查明相关段以进行事件检测。 -
视觉本地化:准确地识别并在具有边界框或点的图像中定位对象,从而提供稳定的JSON输出。 -
结构化输出生成:可以为复杂数据(例如发票,表单和表格)生成结构化输出,可用于金融和商业等领域。
参考文献:
[1] https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct
[2] https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct
[3] https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct
[4] https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct-AWQ
[5] https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct-AWQ
[6]https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct-AWQ
(文:NLP工程化)