


AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
论文题目:Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs
-
论文地址:https://arxiv.org/pdf/2501.18585

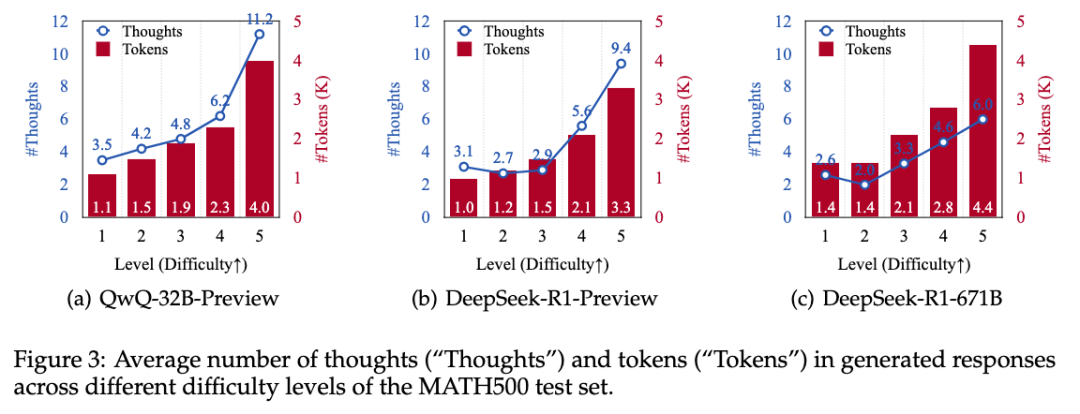
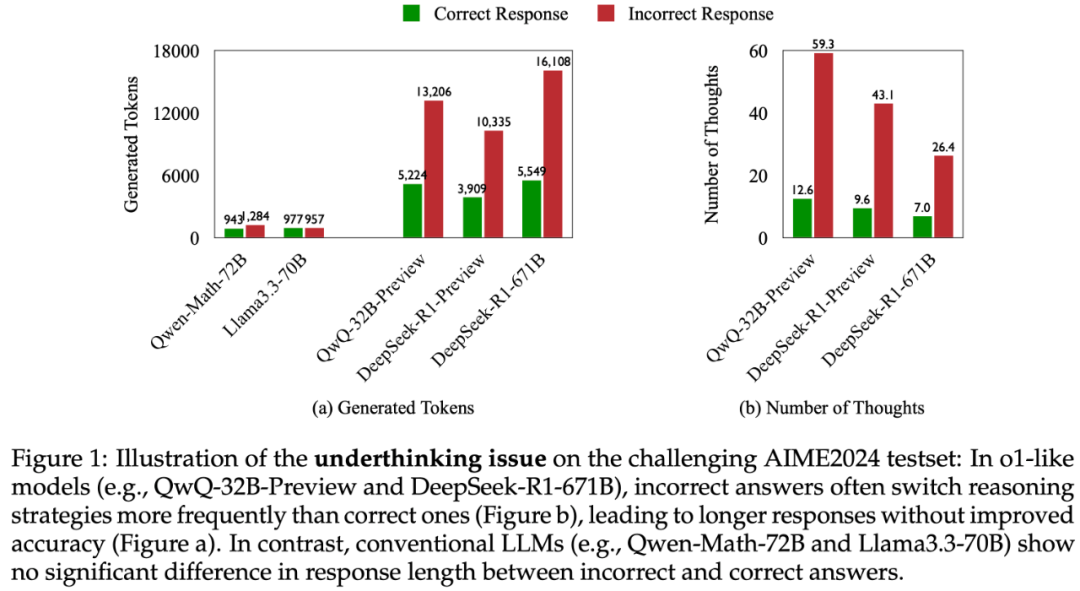
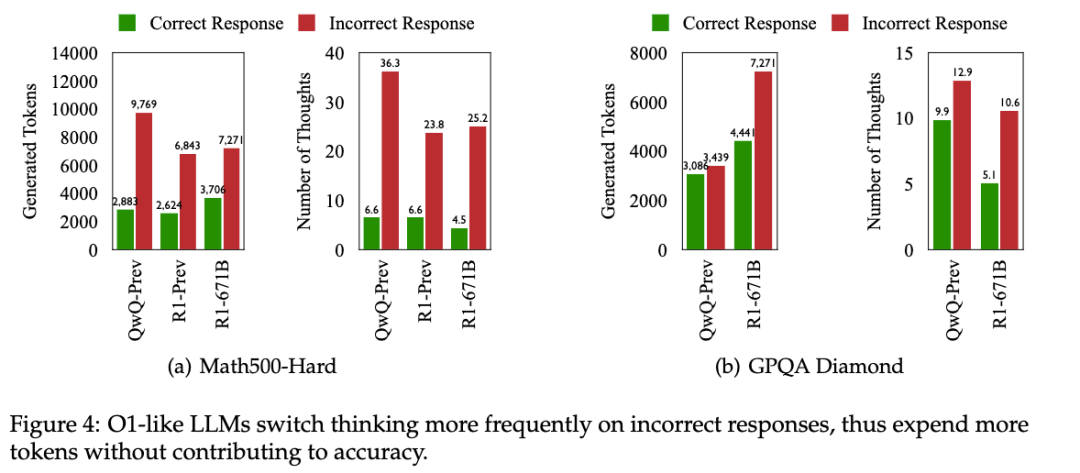
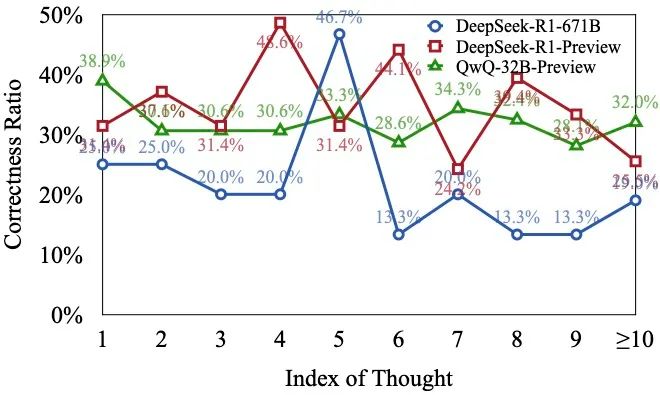
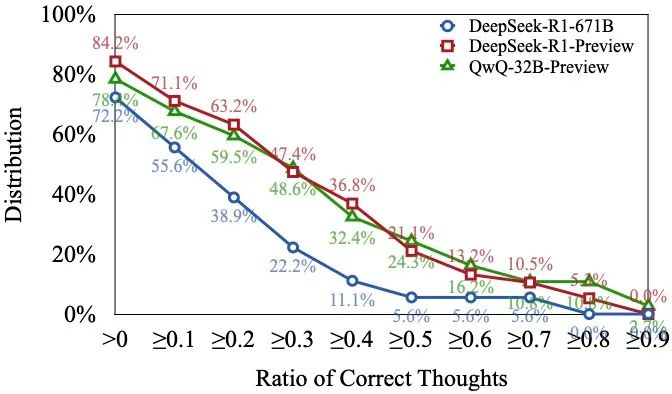
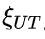 。该指标的计算公式为:
。该指标的计算公式为: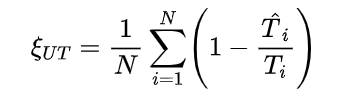
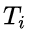 是第 i 个错题的回答 token 数量,
是第 i 个错题的回答 token 数量,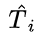 是从该回答开始到第一个正确想法为止的 token 数量(包括第一个正确想法)。如果第 i 个回答中没有正确的思路,则
是从该回答开始到第一个正确想法为止的 token 数量(包括第一个正确想法)。如果第 i 个回答中没有正确的思路,则 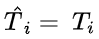 ,表示模型对该问题缺乏理解,因此无法认为是 “思考不足”。直观地说,如果一个模型在回答过程中最初产生了正确的思路,但随后转向其他思路并最终未能得出正确答案,那么此后生成的 token 对于最终达到正确答案并无实质性贡献。这种情况下,由于缺乏足够的思考深度,模型的推理过程被认为是低效的。具体而言,
,表示模型对该问题缺乏理解,因此无法认为是 “思考不足”。直观地说,如果一个模型在回答过程中最初产生了正确的思路,但随后转向其他思路并最终未能得出正确答案,那么此后生成的 token 对于最终达到正确答案并无实质性贡献。这种情况下,由于缺乏足够的思考深度,模型的推理过程被认为是低效的。具体而言,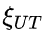 值低表示更高的推理效率,这意味着在错误回答中,有更大比例的 token 能够为正确思路的形成提供支持;值高表示较低的推理效率,意味着有更大比例的 token 未能有效助力于正确思路的生成,即模型可能因频繁切换思路而生成大量冗余或不相关的 token。(越小越能充分思考):
值低表示更高的推理效率,这意味着在错误回答中,有更大比例的 token 能够为正确思路的形成提供支持;值高表示较低的推理效率,意味着有更大比例的 token 未能有效助力于正确思路的生成,即模型可能因频繁切换思路而生成大量冗余或不相关的 token。(越小越能充分思考):

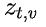 是位置 t 关于 token v 的 logit(未归一化的分数)。为了鼓励模型在切换思路之前更深入地探索当前思路,研究团队引入了一个对与思路转换相关的表达惩罚。具体而言,设
是位置 t 关于 token v 的 logit(未归一化的分数)。为了鼓励模型在切换思路之前更深入地探索当前思路,研究团队引入了一个对与思路转换相关的表达惩罚。具体而言,设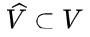 是与思路切换相关的词汇集合(例如,“alternatively”),作者们修改了 logits 如下:
是与思路切换相关的词汇集合(例如,“alternatively”),作者们修改了 logits 如下:
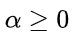 (惩罚强度)是一个控制对思路切换标记施加惩罚强度的参数。较大的
(惩罚强度)是一个控制对思路切换标记施加惩罚强度的参数。较大的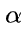 会导致这些词语的 logits 减少更多,使它们被选中的可能性降低;
会导致这些词语的 logits 减少更多,使它们被选中的可能性降低;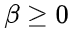 (惩罚持续时间)指定了从思路开始位置
(惩罚持续时间)指定了从思路开始位置 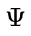 起的惩罚生效的位置数。较大的
起的惩罚生效的位置数。较大的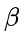 会延长惩罚的范围,进一步阻止过早的思路切换;当
会延长惩罚的范围,进一步阻止过早的思路切换;当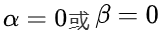 时,惩罚被禁用,解码过程退化为标准解码算法。
时,惩罚被禁用,解码过程退化为标准解码算法。 减少了在指定窗口内生成思路切换标记的概率,从而鼓励模型在继续扩展当前思路之前不进行切换。新的概率分布变为:
减少了在指定窗口内生成思路切换标记的概率,从而鼓励模型在继续扩展当前思路之前不进行切换。新的概率分布变为: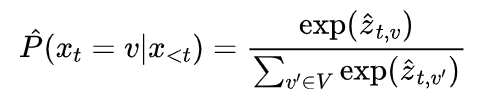
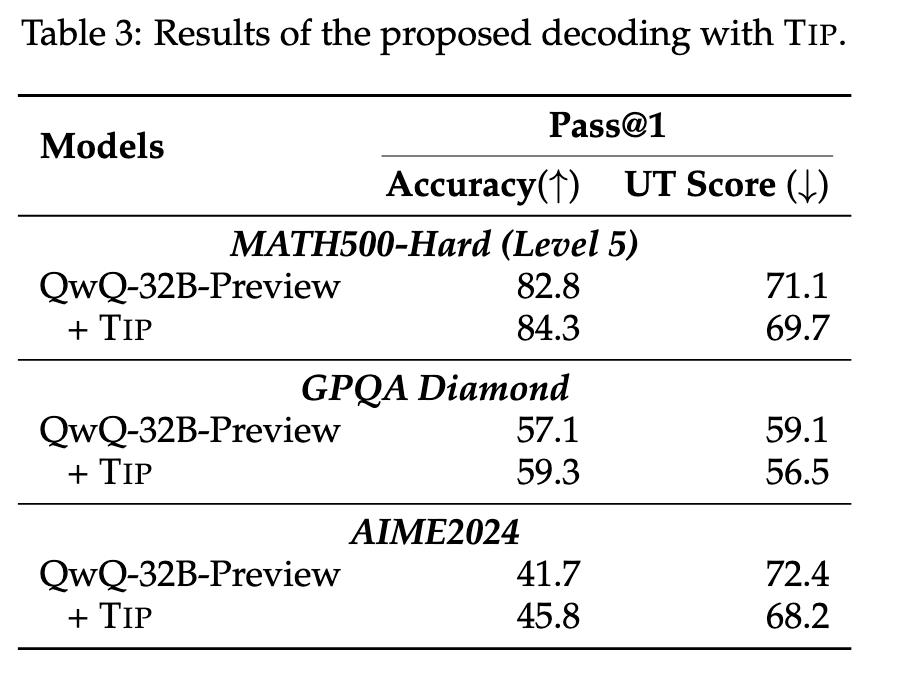
(文:机器之心)