

现在,大语言模型的结构化生成有了一个更加高效、灵活的引擎。

-
论文标题:XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models -
论文地址:https://arxiv.org/pdf/2411.15100 -
代码地址:https://github.com/mlc-ai/xgrammar
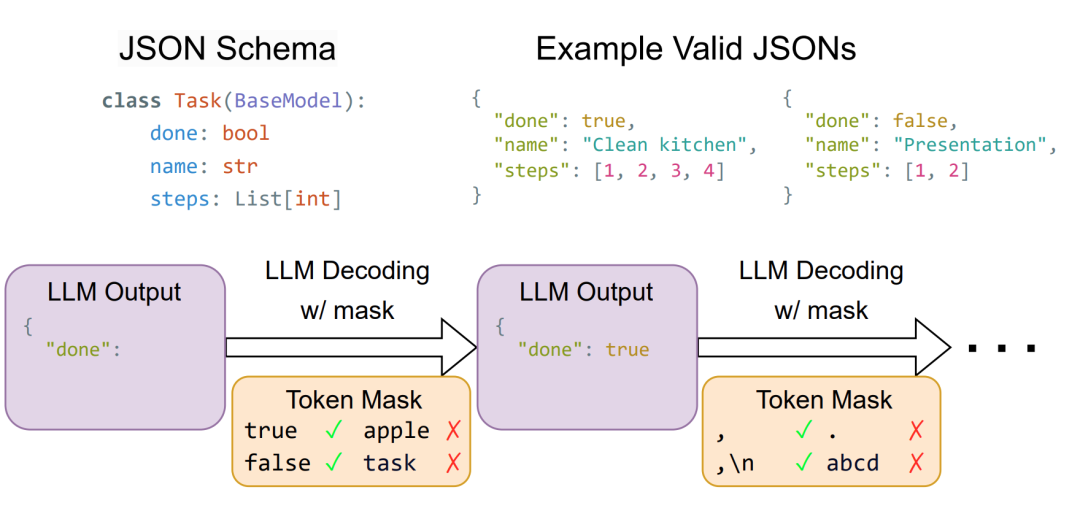
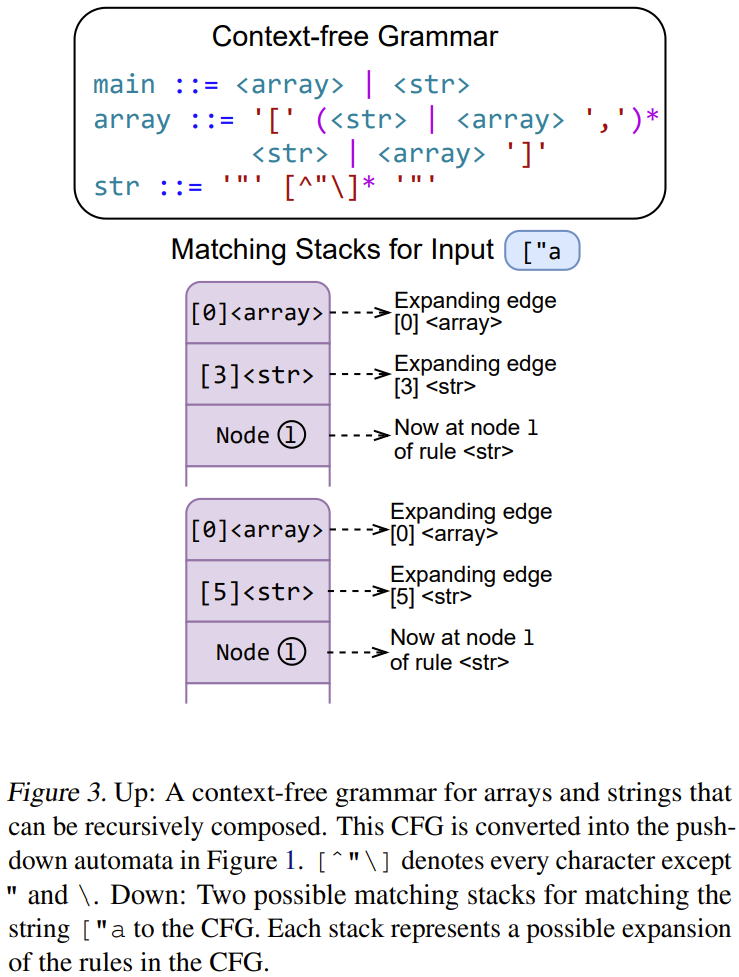
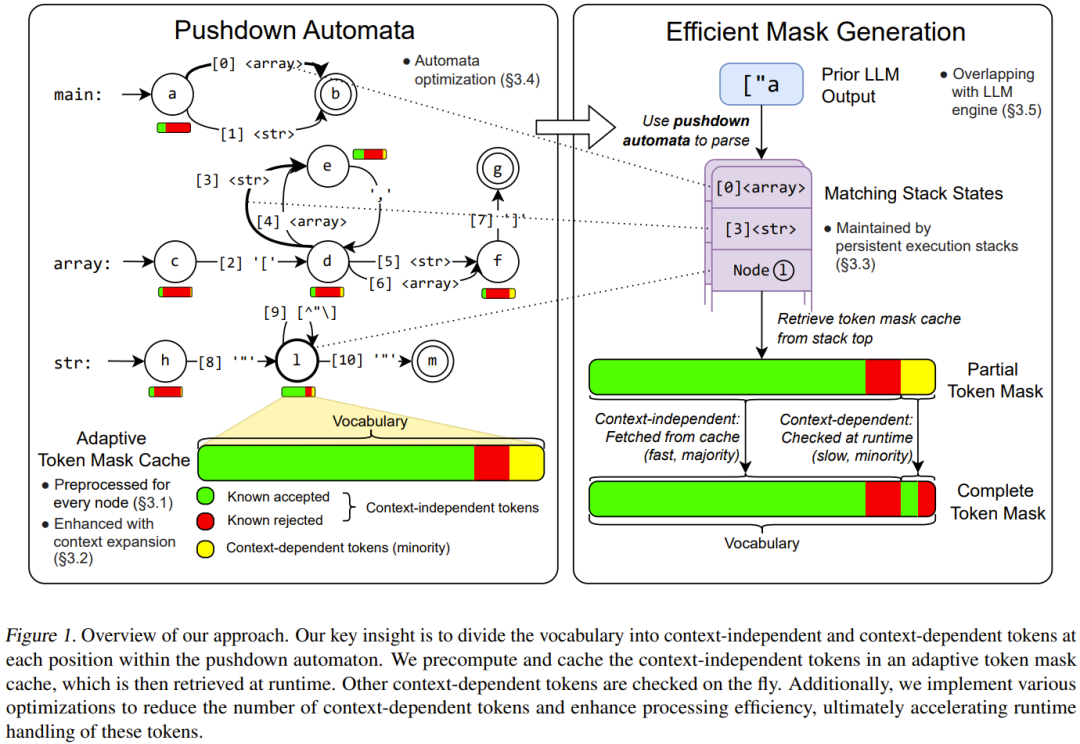
-
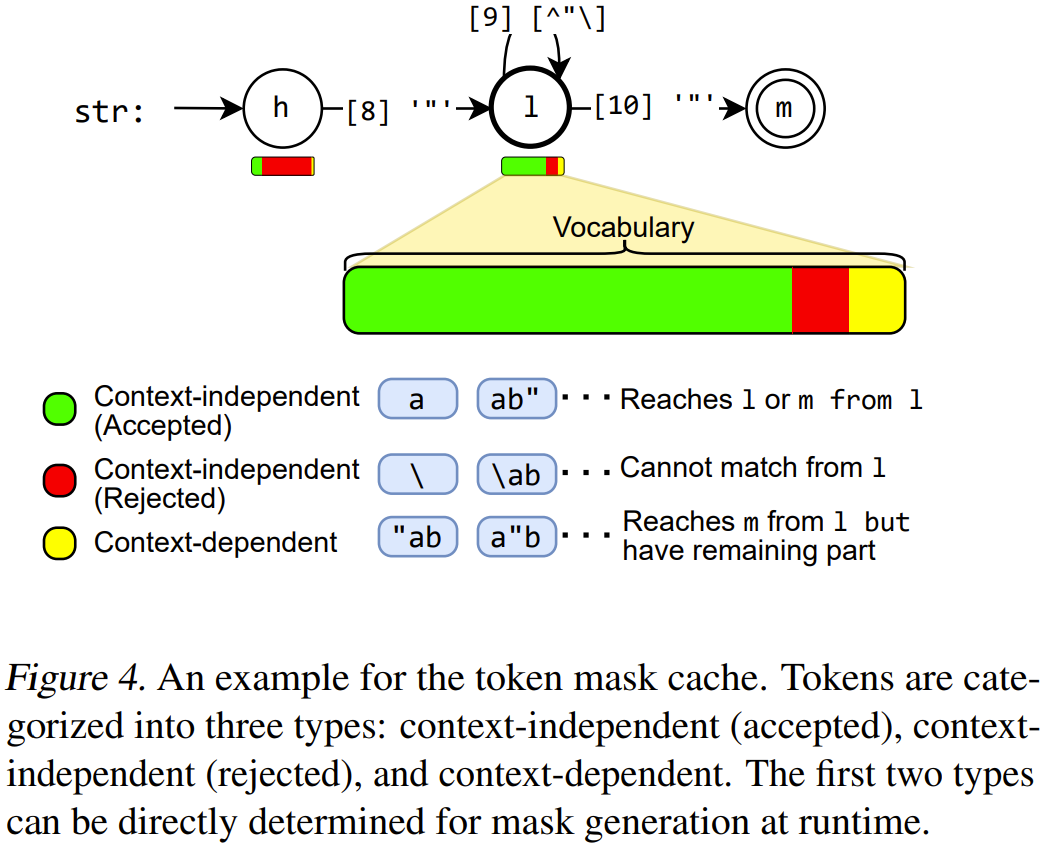
上下文无关 token:仅通过查看 PDA 中的当前位置而不是堆栈即可确定其有效性的 token。
-
上下文相关 token:必须使用整个堆栈来确定其有效性的 token。

-
XGrammar 能否高效支持约束解码的每个步骤?
-
XGrammar 能否在 LLM serving 中实现端到端结构化生成的最小开销?
-
XGrammar 能否部署在更广泛的平台上?
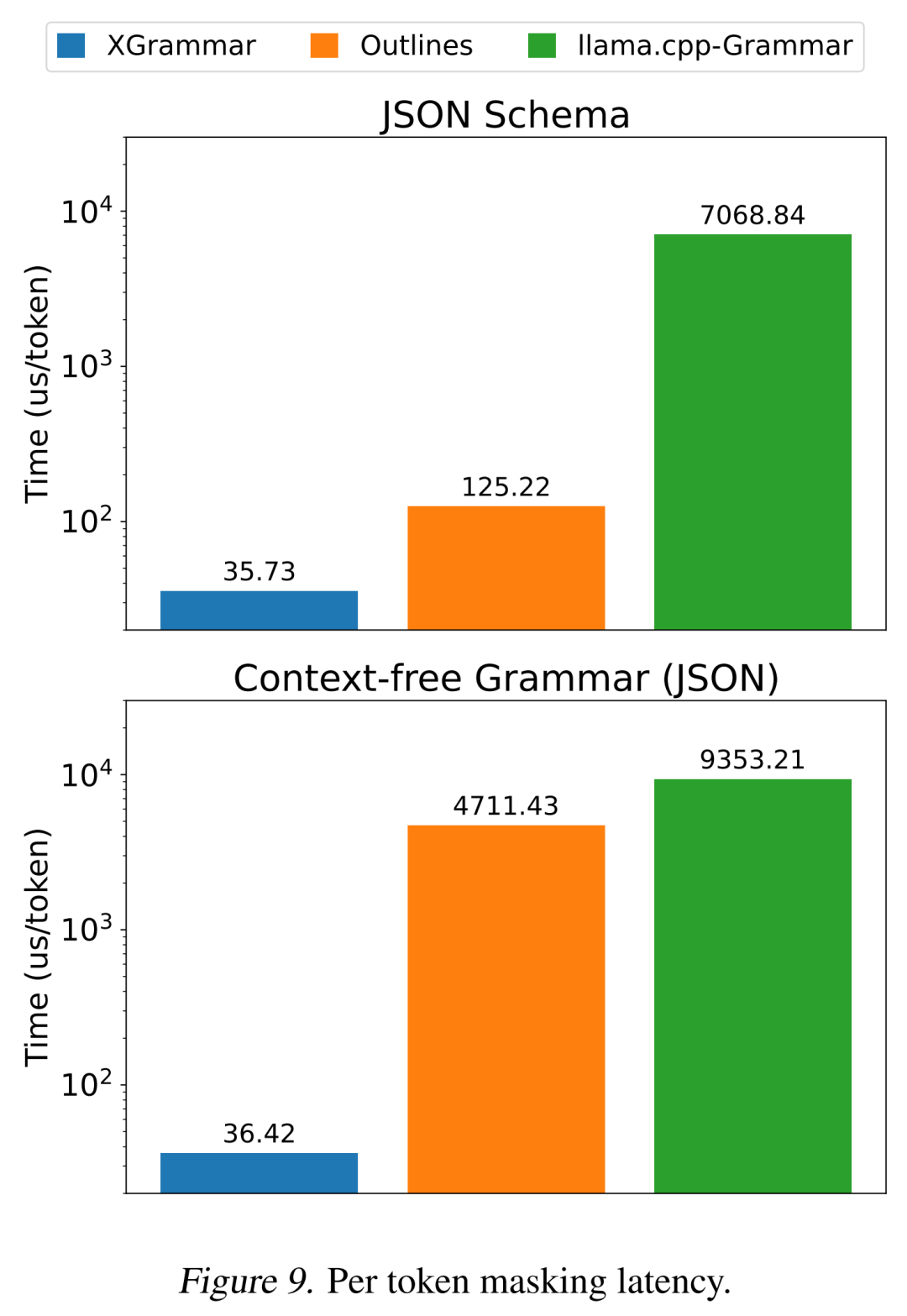
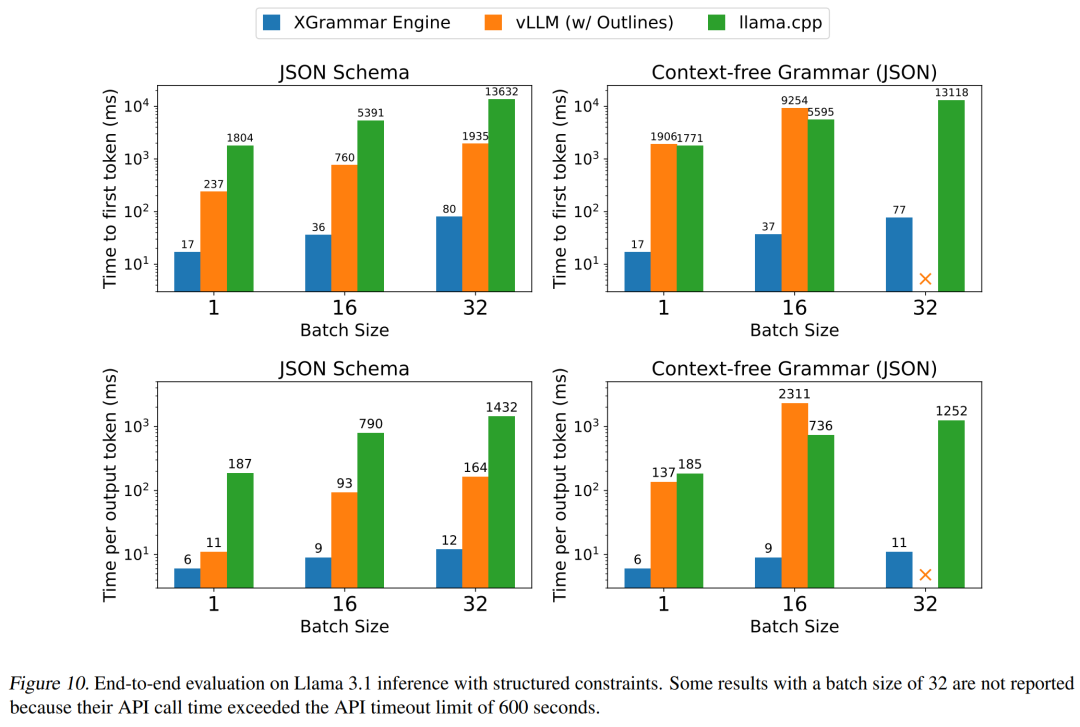
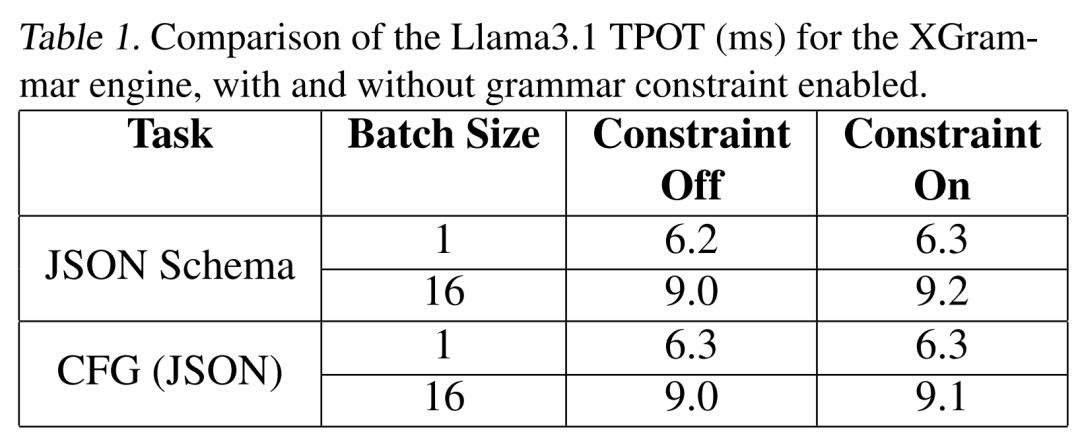
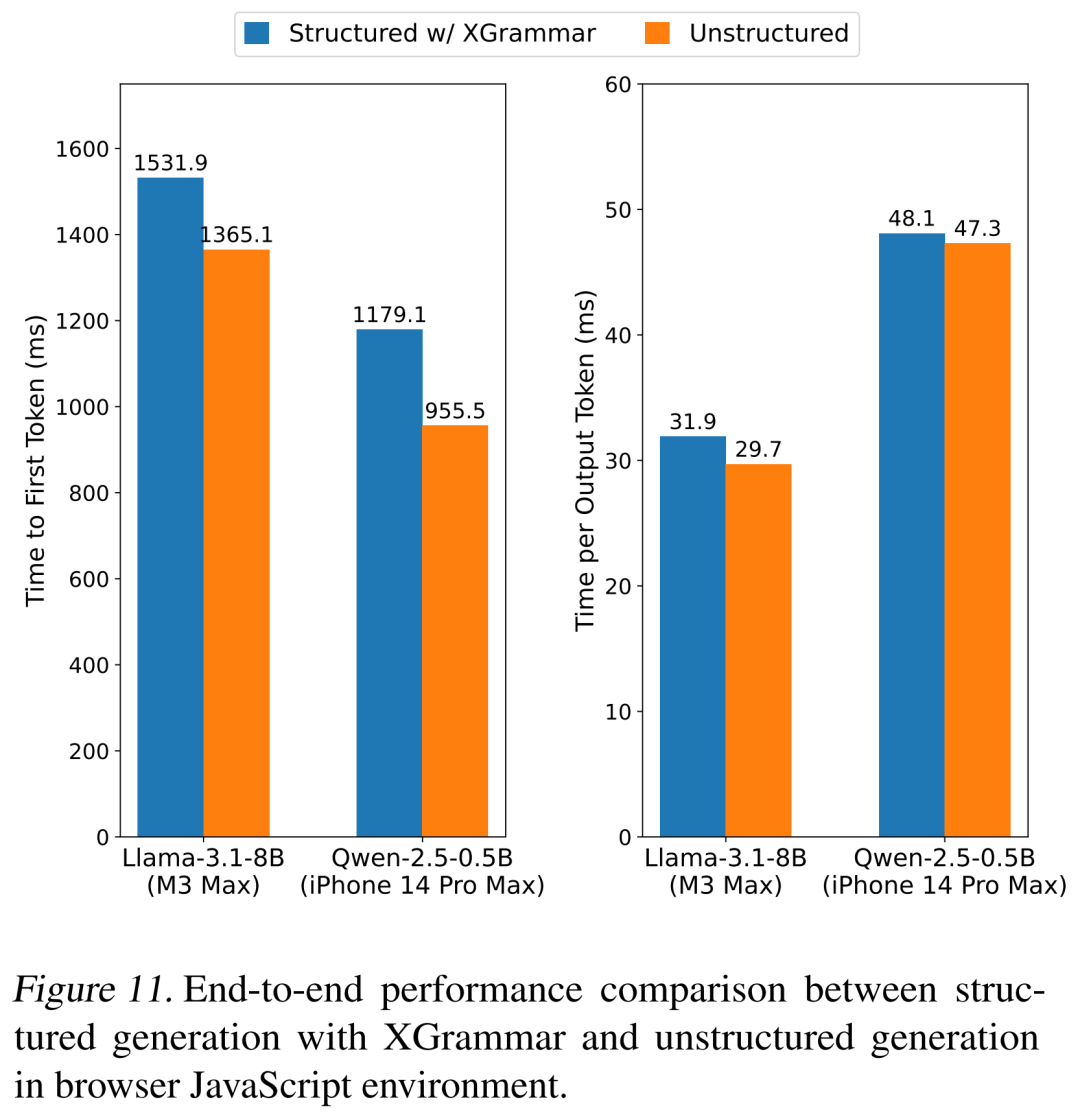
(文:机器之心)