

项目简介
E2M 是一个能够把多种文件类型解析并转换成 Markdown 格式的 Python 库,通过解析器+转换器的架构,实现对 doc, docx, epub, html, htm, url, pdf, ppt, pptx, mp3, m4a 等多种文件格式的转换。
✨E2M 项目的终极目标是为了 RAG 和模型训练、微调,提供高质量的数据。
项目的核心架构:
-
解析器:负责将各种文件类型解析为文本或图片数据
-
转换器:负责将文本或图片数据转换为 Markdown 格式
一般来说,对于任意类型的文件,需要先运行解析器,获取文件内部的 text、image 等数据,然后再运行转换器,将数据转换为 Markdown 格式。
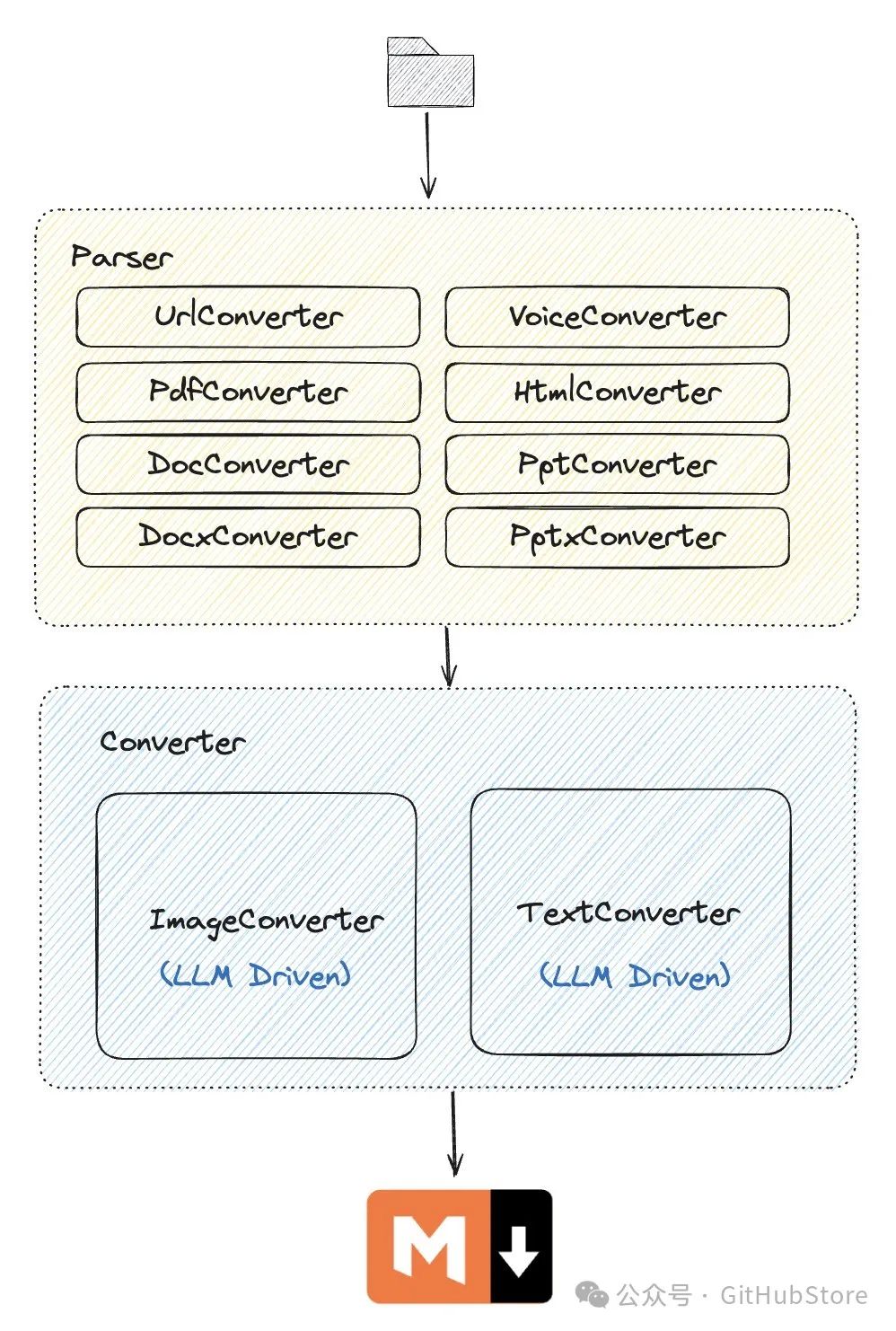
所有的 Parser 和 Converter
| Parser | ||
|---|---|---|
| Parser Type | Engine | Supported File Type |
| PdfParser | surya_layout, marker, unstructured | |
| DocParser | pandoc, xml | doc |
| DocxParser | pandoc, xml | docx |
| PptParser | unstructured | ppt |
| PptxParser | unstructured | pptx |
| UrlParser | unstructured, jina, firecrawl | url |
| EpubParser | unstructured | epub |
| HtmlParser | unstructured | html, htm |
| VoiceParser | openai_whisper_api, openai_whisper_local, SpeechRecognition | mp3, m4a |
| Converter | ||
|---|---|---|
| Converter Type | Engine | Strategy |
| ImageConverter | litellm, zhipuai (图像识别表现不佳,不推荐) | default |
| TextConverter | litellm, zhipuai | default |
转换器支持的模型:
-
Litellm: https://docs.litellm.ai/docs/providers/
-
Zhipuai: https://open.bigmodel.cn/dev/howuse/model
📦 安装
创建环境:
conda create -n e2m python=3.10conda activate e2m
更新 pip:
pip install --upgrade pip使用 pip 安装 E2M:
# 选项 1: 通过git安装,最推荐pip install git+https://github.com/wisupai/e2m.git --index-url https://pypi.org/simple# 选项 2: 通过pip安装pip install --upgrade wisup_e2m# 选项 3: 手动安装git clone https://github.com/wisupai/e2m.gitcd e2mpip install poetrypoetry buildpip install dist/wisup_e2m-0.1.63-py3-none-any.whl
启动API服务
gunicorn wisup_e2m.api.main:app --workers 4 --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0:8000查看API文档:
-
http://127.0.0.1:8000/docs
CLI 命令行工具
使用marker转换pdf
转换单个pdf:
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10 批量转换pdf:
marker /path/to/input/folder /path/to/output/folder --workers 4 --max 10 --min_length 10000⚡️ 解析器: 快速开始
以下是使用 E2M 解析器的简单示例:
📄 PDF 解析器
Note
如果没有科学上网,可能连接huggingface失败,可以使用设置以下镜像:
import osos.environ['CURL_CA_BUNDLE'] = ''os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from wisup_e2m import PdfParserpdf_path = "./test.pdf"parser = PdfParser(engine="marker") # pdf 引擎: marker, unstructured, surya_layoutpdf_data = parser.parse(pdf_path)print(pdf_data.text)
📝 DOC 解析器
from wisup_e2m import DocParserdoc_path = "./test.doc"parser = DocParser(engine="pandoc") # doc 引擎: pandoc, xmldoc_data = parser.parse(doc_path)print(doc_data.text)
📜 DOCX 解析器
from wisup_e2m import DocxParserdocx_path = "./test.docx"parser = DocxParser(engine="pandoc") # docx 引擎: pandoc, xmldocx_data = parser.parse(docx_path)print(docx_data.text)
🌐 HTML 解析器
from wisup_e2m import HtmlParserhtml_path = "./test.html"parser = HtmlParser(engine="unstructured") # html 引擎: unstructuredhtml_data = parser.parse(html_path)print(html_data.text)
🔗 URL 解析器
from wisup_e2m import UrlParserurl = "https://www.example.com"parser = UrlParser(engine="jina") # url 引擎: jina, firecrawl, unstructuredurl_data = parser.parse(url)print(url_data.text)
🖼️ PPT 解析器
from wisup_e2m import PptParserppt_path = "./test.ppt"parser = PptParser(engine="unstructured") # ppt 引擎: unstructuredppt_data = parser.parse(ppt_path)print(ppt_data.text)
🖼️ PPTX 解析器
from wisup_e2m import PptxParserpptx_path = "./test.pptx"parser = PptxParser(engine="unstructured") # pptx 引擎: unstructuredpptx_data = parser.parse(pptx_path)print(pptx_data.text)
🎤 语音解析器
from wisup_e2m import VoiceParservoice_path = "./test.mp3"parser = VoiceParser(engine="openai_whisper_local", # 语音引擎: openai_whisper_api, openai_whisper_localmodel="large" # 可用模型: https://github.com/openai/whisper#available-models-and-languages)voice_data = parser.parse(voice_path)print(voice_data.text)
🔄 转换器: 快速开始
以下是使用 E2M 转换器的简单示例:
📝 文本转换器
from wisup_e2m import TextConvertertext = "从任何解析器解析的文本数据"converter = TextConverter(engine="litellm", # 文本引擎: litellmmodel="deepseek/deepseek-chat",api_key="你的 API 密钥",base_url="你的基础 URL")text_data = converter.convert(text)print(text_data)
🖼️ 图片转换器
from wisup_e2m import ImageConverterimages = ["./test1.png", "./test2.png"]converter = ImageConverter(engine="litellm", # 图片引擎: litellmmodel="gpt-4o",api_key="你的 API 密钥",base_url="你的基础 URL")image_data = converter.convert(images)print(image_data)
🆙 下一步
🛠️ E2MParser
E2MParser 是一个集成解析器,支持多种文件类型。可以将各种文件类型解析为 Markdown 格式。
from wisup_e2m import E2MParser# 使用配置文件初始化解析器ep = E2MParser.from_config("config.yaml")# 解析指定文件data = ep.parse(file_name="/path/to/file.pdf")# 将解析的数据以字典格式打印print(data.to_dict())
🛠️ E2MConverter
E2MConverter 是一个集成转换器,支持文本和图片转换。可以将文本和图片转换为 Markdown 格式。
from wisup_e2m import E2MConverterec = E2MConverter.from_config("./config.yaml")text = "从任何解析器解析的文本数据"ec.convert(text=text)images = ["test.jpg", "test.png"]ec.convert(images=images)
你可以使用 config.yaml 文件来指定要使用的解析器和转换器。以下是一个 config.yaml 文件的示例:
parsers:doc_parser:engine: "pandoc"langs: ["en", "zh"]docx_parser:engine: "pandoc"langs: ["en", "zh"]epub_parser:engine: "unstructured"langs: ["en", "zh"]html_parser:engine: "unstructured"langs: ["en", "zh"]url_parser:engine: "jina"langs: ["en", "zh"]pdf_parser:engine: "marker"langs: ["en", "zh"]pptx_parser:engine: "unstructured"langs: ["en", "zh"]voice_parser:engine: "openai_whisper_local"model: "large"converters:text_converter:engine: "litellm"model: "deepseek/deepseek-chat"api_key: "你的 API 密钥"image_converter:engine: "litellm"model: "gpt-4o-mini"api_key: "你的 API 密钥"
项目链接
https://github.com/wisupai/e2m/blob/main/README-zh.md
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)