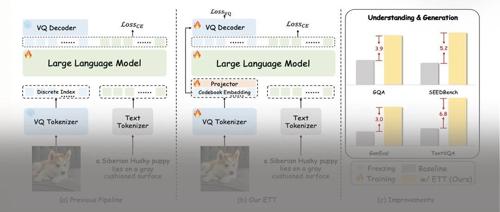
字节Seed新作:模型合并如何改变大模型预训练范式

字节跳动提出预训练模型平均(PMA)技术,在不增加计算成本的情况下显著提升大模型性能。通过合并稳定期检查点,PMA能预测衰减阶段表现,节省资源并加速训练进程。
字节跳动提出预训练模型平均(PMA)技术,在不增加计算成本的情况下显著提升大模型性能。通过合并稳定期检查点,PMA能预测衰减阶段表现,节省资源并加速训练进程。

ZIP Lab和Monash团队提出ZPressor模块,通过信息瓶颈原理解决了前馈3D高斯泼溅模型的信息过载问题。该方法显著提升了实时渲染能力、推理时间和显存占用,并在多种基准数据集上提高了模型的鲁棒性和性能表现。

上海交通大学和SII的研究表明,仅需312条人类标注轨迹,并通过合成更多动作决策的思维链补全与轨迹增强技术,就能显著提升电脑智能体(Operator)性能。这一方法使得模型性能提升了241%,超越了基础模型Claude 3.7 Sonnet extended thinking模式,成为Windows系统上开源电脑智能体的新一代SOTA。
MLNLP社区发布论文《Parallel Scaling Law for Language Models》提出ParScale技术,让模型在保持参数不变的情况下通过并行计算提升性能,推理效率提升22倍,实现高效省资源扩展。
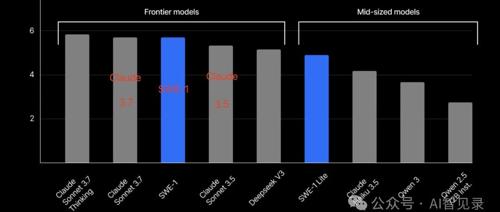
最近,Windsurf发布了其v1.9.0版本,并推出了一系列自研AI模型。其中包括SWE-1、SWE-1-Lite和SWE-1-Mini三个新成员。这些模型旨在提升开发者在软件工程任务中的表现,并展示Windsurf在人工智能技术上的实力。