
 PaperWeekly
PaperWeekly


视频理解“隐秘的角落”:多任务视频文本理解评测新基准VidText发布

VidText 提出了一套全面的视频文本理解基准,覆盖 27 个真实场景和多种语言。它包含从视觉感知到跨模态推理的多个任务,评估模型在不同粒度上的表现,并揭示了影响性能的关键因素。

ICML 2025 Agentic时代唤醒NAS”第二春”!智能体超网动态组队,推理成本暴降55%

大语言模型驱动的多智能体系统在构建时面临手动设计和调试的瓶颈。新加坡国立大学等团队推出MaAS框架,利用智能体超网技术实现按需定制的动态智能体服务,提高效率并降低成本。
视觉感知驱动的多模态推理:阿里通义提出VRAG-RL,定义下一代检索增强生成

VRAG-RL 是一种基于强化学习的视觉检索增强生成方法,通过引入多模态智能体训练,实现了视觉语言模型在检索、推理和理解复杂视觉信息方面的显著提升。
ACL 2025 多维阅卷,智识觉醒:打开多模态大模型看图写作评估的认知之门

研究构建首个面向MLLM的细粒度AES基准EssayJudge,采用10项细粒度评分维度,涵盖词汇、句子和文章三个层级,评价作文质量。
建议所有博士都去学一遍,赢麻了!

文章介绍了如何通过掌握正确的科研方法和导师指导快速发表顶会顶刊论文。强调了执行能力和实战经验的重要性,并推荐了一堂由顶级期刊主席主讲的系统课程,涵盖了论文选题、写作与投稿全流程的知识点和方法论。
地铁换乘都搞不定?ReasonMap基准揭示多模态大模型细粒度视觉推理短板
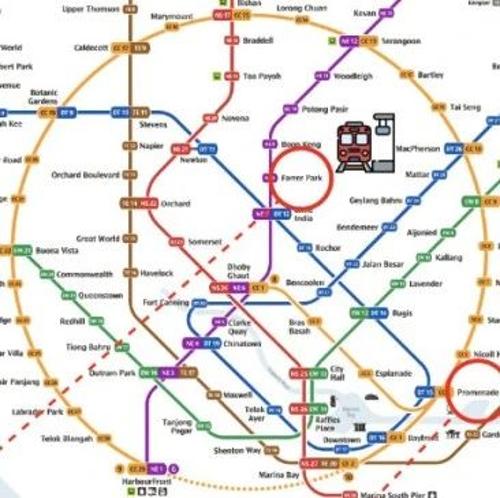
ReasonMap 是首个聚焦于高分辨率交通图的多模态推理评测基准,用于评估大模型在理解图像细粒度结构化空间信息方面的能力。
