

机构: 中国人民大学高瓴人工智能学院
论文标题:FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research
论文链接:https://arxiv.org/abs/2405.13576
项目链接 (Paddle版本): https://github.com/RUC-NLPIR/FlashRAG-Paddle
数据集链接: https://huggingface.co/datasets/RUC-NLPIR/FlashRAG_datasets

产品亮点
1. FlashRAG-Paddle:组件化、模块化的RAG框架
全面且可定制的RAG框架,集成检索器、重排序器、生成器和压缩器等核心组件,提供36个基准数据集和9种先进算法,辅以高效预处理脚本,简化流程,轻松实现复杂RAG场景下的模型测试与验证。
2. PaddleNLP: 超大Batch嵌入表示学习和多硬件高性能推理
PaddleNLP提供一站式大语言模型解决方案,支持超大Batch嵌入学习,多硬件高性能推理,涵盖了 INT8/INT4量化技术,以及PageAttention、FlashDecoding等高效的注意力机制优化和TensorCore深度优化,从而大幅提升训练与推理效率,全方位满足多样化的应用需求。
3. FlashRAG & PaddleNLP:检索增强生成结合高性能推理,更准更快,提升用户体验
基于飞桨框架3.0版本,PaddleNLP内置了全环节算子融合等技术,使得FlashRAG推理性能相较于 transformers动态图推理实现了70%以上的显著提升,结合检索增强知识,输出结果更加准确,为FlashRAG框架使用者带来了敏捷高效的使用体验。
1. 背景介绍
为解决上述问题,中国人民大学高瓴人工智能学院联合百度共同发布了FlashRAG-Paddle框架,其中内置36个经过预处理的RAG数据集以及9种预实现的RAG算法,能够帮助研究⼈员高效地在RAG领域进行复现、基准测试和开发新算法。同时,借助基于飞桨框架3.0版本打造的PaddleNLP大语言模型套件,通过极致的全流程优化,为RAG中的检索器、生成器、重排器、精炼器提供从组网开发、预训练、精调对齐、模型压缩以及推理部署的一站式解决方案。
目前,FlashRAG已在Github平台获得近1.3K星标,欢迎大家持续关注、使用和贡献代码!
2. FlashRAG-Paddle框架
为了能够灵活高效地搭建各类RAG系统,FlashRAG采用了 组件化、模块化 的设计理念,将整个框架的设计包括三个层面:组件层、流程层、数据层。
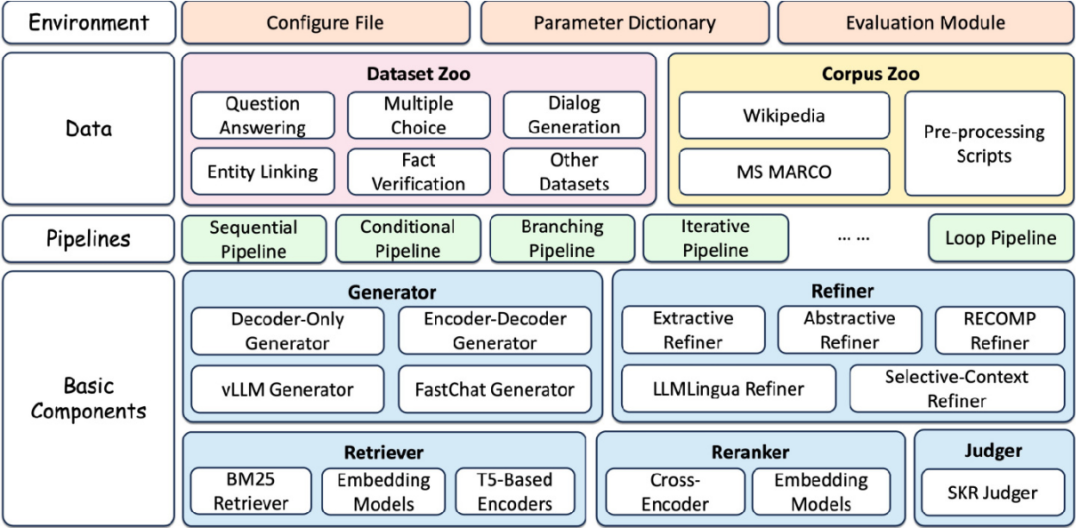
2.1. 组件层
组件层位于框架的最底层,提供了构建RAG系统所需的各类基础组件,主要包括:
•检索器(Retriever):负责从知识库中检索与查询最相关的文档。FlashRAG支持使用embedding模型以及基于词项匹配的BM25方法等。
•生成器(Generator):根据给定的文本(通常是查询和检索结果的拼接)生成最终的回复。框架支持使用各类LLM模型,并⽀持FastChat、vllm等加速方案。
•重排器(Reranker):对检索结果进行重新排序,以进一步提升与查询的相关性。重排器分为交叉编码器和双塔编码器两种类型。
•精炼器(Refiner):对输入的文本进行进一步的精炼和压缩,去除冗余信息。目前已支持抽取式、生成式、基于LLMLingua和基于Selective-Context的多种精炼器。
基于实现的组件库,用户可以自由选择需要使用的组件来完成自己的特定需求。
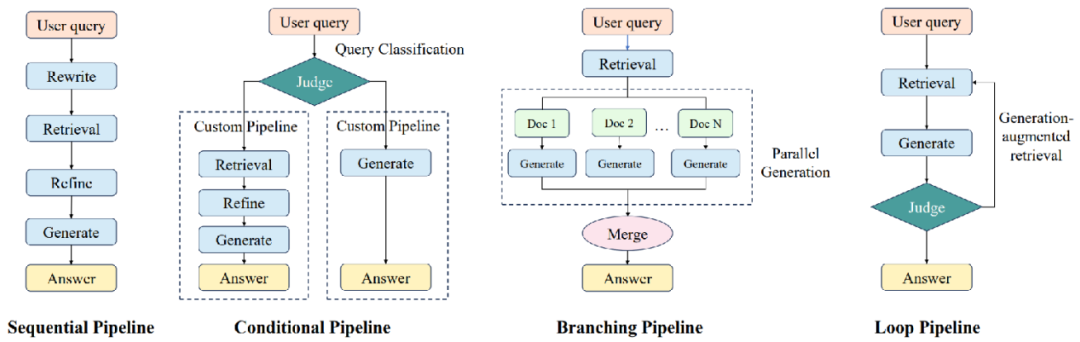
2.2. 流程层
流程层位于组件层之上,通过组装各类组件实现端到端的RAG流程。
基于各种方法的推理路径,我们将RAG流程分为了四⼤类:
•Sequential:顺序执行retriever、refiner、reranker、generator等组件,是最基础的RAG流程。
•Conditional:通过judger模块判断不同类型的查询,并选择不同的执行路径。
•Branching:并行执行多条路径,并将各路径的生成结果进行整合,代表工作如REPLUG、SuRe等。
•Loop:通过迭代的方式交替执行retriever和generator,代表工作如Self-Ask、Self-RAG、FLARE、IRCoT等。
2.3. 数据层
最上层为数据层,包括用于检索的语料数据以及用于评估的各种任务数据。在RAG流程运行完成后,会自动计算相关的评价指标并保存评测结果。我们收集并处理了RAG研究中广泛使用的35个数据集,并对其进行了预处理,以确保格式一致,便于使用。对于某些数据集,我们根据社区中常用的方法对其进行了调整以满足 RAG任务的要求。所有数据集均可在Huggingface平台上进行下载。
3. PaddleNLP: 超大Batch嵌入表示学习和多硬件高性能推理助力检索增强生成
•模型组网简化与参数多样:PaddleNLP通过统一分布式表示与自动并行技术,显著简化了组网开发的流程,减少了分布式核心代码量50%以上,结合多种并行策略Llama 3.1 405B等超大规模模型能够开箱即用。此外,PaddleNLP预置了80多个主流模型的训练、压缩、推理全流程方案,满足了不同应用场景下的多样化需求。
•精调与对齐性能提升:借助飞桨框架独有的FlashMask高性能变长注意力掩码计算机制和Zero Padding零填充数据流优化技术,PaddleNLP有效减少了无效数据填充带来的计算资源浪费,显著提升了精调和对齐的性能。以Llama 3.1 8B模型为例,其性能相较于LLaMA-Factory方案实现了1.2倍的提升,单机即可轻松完成128K长文的SFT/DPO任务。
•硬件适配⼴泛与⾼效:PaddleNLP基于飞桨插件式松耦合统一硬件适配方案(CustomDevice),仅需适配30余个接口即可实现大模型的基础适配,支持英伟达GPU、昆仑芯XPU、昇腾NPU、燧原GCU和海光 DCU等多款主流芯片的⼤模型训练和推理。依托框架提供的多种算子接入模式和自动并行调优技术,PaddleNLP实现了框架与芯片间的软硬协同性能优化,为用户提供了更加高效、稳定的模型训练和推理体验。
3.1. 超大Batch嵌入表示学习
嵌⼊表示学习采⽤In-batch negative策略,即将 batch 内的所有其他样本视作负样本,定义Contrastive loss 函数如下:
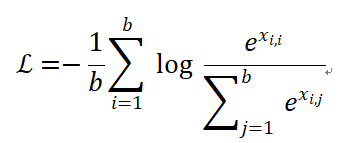
其中 是第个文本和第个文本之间的余弦相似度,是匹配样本的相似度。从公式中可以看出随着batch size的增⼤,模型能接触并学习更多负样本,进而提取出更具判别性的特征。因此在大模型训练过程中,需要更大的Batch提升模型性能。
PaddleNLP通过在数据并行中支持In-batch negative策略以及flashmask等显存优化策略,在训练embedding模型时,提升每次训练的batch size, 进而显著提高训练效率和效果。
为了扩大全局batch,PaddleNLP采⽤gradient cache策略。该策略首先执行模型前向传播,计算micro-batch输出并舍弃中间隐藏状态。随后,累计这些输出以计算Contrastive loss,实现超大batch的对⽐学习效果。最后,针对各micro-batch重新计算隐藏状态,进行前向与反向传播,并依据对比学习梯度优化模型参数来提升训练效果。
3.2. 多硬件高性能推理
特点一:高性能推理优化,支持Llama 3.1 405B高性能推理
PaddleNLP构建了大模型高性能推理方案,支持Llama 3.0、Llama 3.1、Mixtral等一系列大语言模型推理。当前支持技术包含:
•Weight Only INT8及INT4推理,支持权重、激活、Cache KV进行INT8、FP8量化的推理;
•注意力机制支持PageAttention、FlashDecoding等优化;
•支持基于TensorCore深度优化。
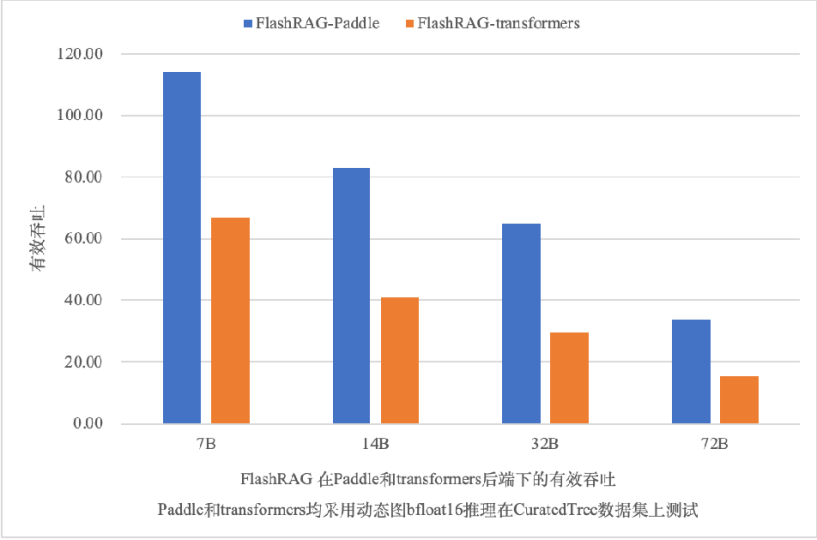
PaddleNLP高性能推理通过内置全环节算子融合策略,获取更优推理性能。在7B、14B、32B和72B模型的推理性能上,PaddleNLP后端相比transformers后端动态图推理提速70%至119%。同时,Llama 3.1 405B作为开源社区中的最大模型,PaddleNLP推理也快速支持了此模型,单机8卡即可实现快速推理能力。
特点⼆:多硬件大模型推理支持
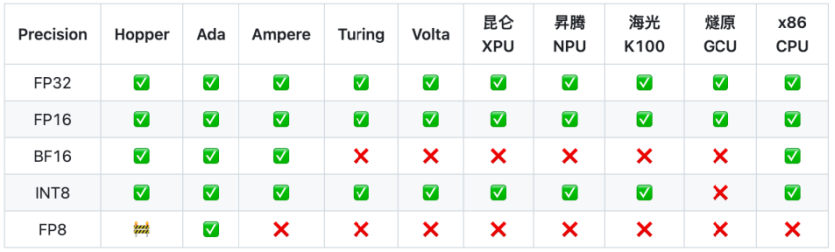
在硬件支持方面,飞桨推理引擎展现出了强大的兼容性和灵活性。当前在支持英伟达GPU的基础上,还支持了国产及国际领先的AI芯片生态,包括昆仑XPU、昇腾NPU、海光DCU、燧原GCU、英特尔X86 CPU等多种硬件的大模型推理,不同硬件的推理入口保持统一,仅需修改device即可支持不同硬件推理。
PaddleNLP的这一特性强化了RAG在更广泛的多硬件环境下的部署场景,满足不同用户的多样化需求,推动RAG在更多实际业务中的应用与落地。
4. FlashRAG + PaddleNLP 快速打造RAG文档问答应用
RAG(检索增强生成)技术巧妙融合了信息检索与先进的生成模型,通过从丰富的外部知识库中精准检索相关信息,为大型语言模型提供强有力的回答辅助。这一创新技术充分发挥了信息检索的精准性与生成模型的创造力,能够自动生成既高质量又准确,同时紧密贴合上下文的文档总结。接下来,我们将为您详细介绍如何仅需三步,即可轻松构建RAG文档总结应用。
4.1. 构建自己的语料数据库
步骤1:准备语料
首先需要准备预料库来作为检索召回的基础,预料库保存为 jsonl 以下格式,
1{"id": "0", "contents": "contents for building index"}2{"id": "1", "contents": "contents for building index"}
更多语料制作细节,请前往https://github.com/RUC-NLPIR/FlashRAG-Paddle查看。
步骤2:索引
然后,使用以下代码构建您自己的索引。
•对于密集检索方法,通过使用embedding模型,将文档嵌入到密集向量中,之后使⽤ faiss 来建立密集向量索引。
•对于稀疏检索方法,基于Pyserini或bm25s,依据词频将语料构建为Lucene的倒排索引。
密集检索⽅法1python -m flashrag.retriever.index_builder \2--retrieval_method e5 \3--model_path intfloat/e5-base-v2/ \4--corpus_path indexes/sample_corpus.jsonl \5--save_dir indexes/ \6--use_fp16 \7--max_length 512 \8--batch_size 256 \9--pooling_method mean \10--faiss_type Flat
稀疏检索⽅法(BM25)1python -m flashrag.retriever.index_builder \2--retrieval_method bm25 \3--corpus_path indexes/sample_corpus.jsonl \4--bm25_backend bm25s \5--save_dir indexes/
4.2. 配置检索器和生成器
步骤1: 配置检索模型和生成模型
通过这段代码,我们指定了检索模型和生成模型的具体设置,为RAG运行提供了必要的配置信息。
1# 定义⼀个配置字典,包含所有必要的设置2config_dict = {3"save_note": "demo", # 保存备注,用于标识这次配置4"model2path": { # 模型名称及其对应的路径5"e5": "intfloat/e5-base-v2", # 检索模型e5的路径6"llama3-8B-instruct": "meta-llama/Meta-Llama-3-8B-Instruct" # ⽣成模型llama3-8B-instruct的路径7 },8"retrieval_method": "e5", # 指定使⽤的检索模型9"generator_model": "llama3-8B-instruct", # 指定使⽤的⽣成模型10 "corpus_path": "indexes/general_knowledge.jsonl", # 知识库⽂件的路径,检索模型会从这⾥查找信息11"index_path": "indexes/e5_Flat.index", # 索引⽂件的路径,⽤于加速检索过程12 }1314# 使⽤配置字典和⼀个配置⽂件路径来初始化配置对象15config = Config("my_config.yaml", config_dict=config_dict)
步骤2: 定义对话模板
为了让AI助手更加⼈性化,我们需要为它设定一些对话模板。这些模板会指导AI如何回应用户的输⼊,并确保回复既友好又准确。
# 定义⼀个带有引⽤信息(reference)的系统提示,AI在回应时会参考这些信息system_prompt_rag = ("你是⼀个友好的AI助⼿。""像⼈类⼀样回应输⼊,如果输⼊中有指令,请遵循指令进⾏回应。""\n以下是⼀些提供的参考信息。你可以使⽤这些信息来回答问题。\n\n{reference}")# 定义⽤户输⼊的基本模板,{question}会被实际的问题所替换base_user_prompt = "{question}"# 使⽤前⾯定义的配置和模板,创建⼀个带有引⽤信息的对话模板对象prompt_template_rag = PromptTemplate(config, system_prompt=system_prompt_rag, user_prompt=base_user_prompt)
步骤3: 加载检索模型和生成模型
在配置好对话模板之后,接下来我们需要加载之前配置的检索模型和生成模型。这两种模型在PaddleNLP库中已经集成,所以我们可以直接调用它们,无需从头开始训练或编写复杂的代码。
# 根据配置加载检索模型,这是RAG⽤于从知识库中查找信息的模型retriever = load_retriever(config)# 根据配置加载⽣成模型,这是RAG⽤于⽣成输出的模型generator = load_generator(config)
4.3. 检索增强,生成输出
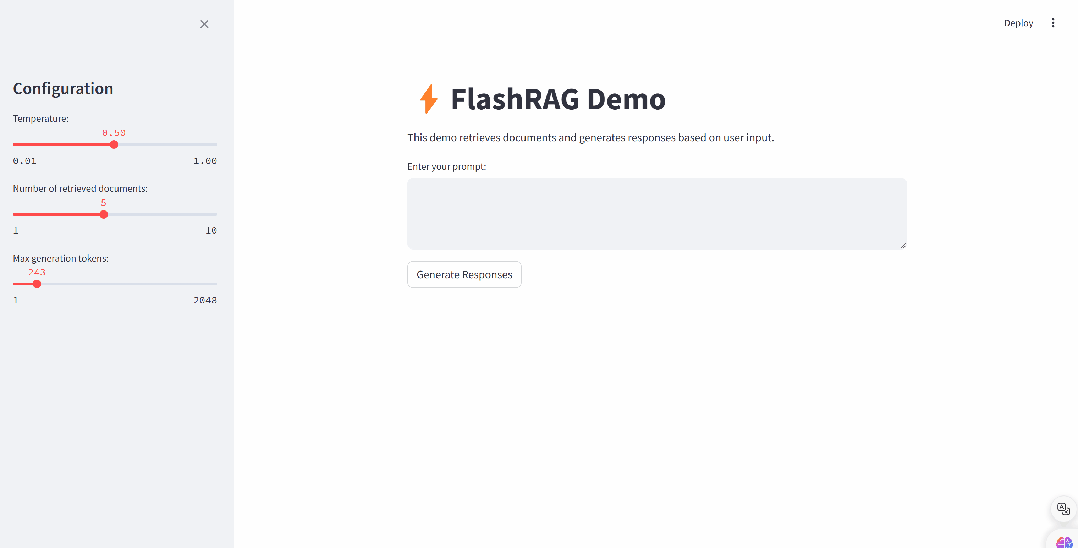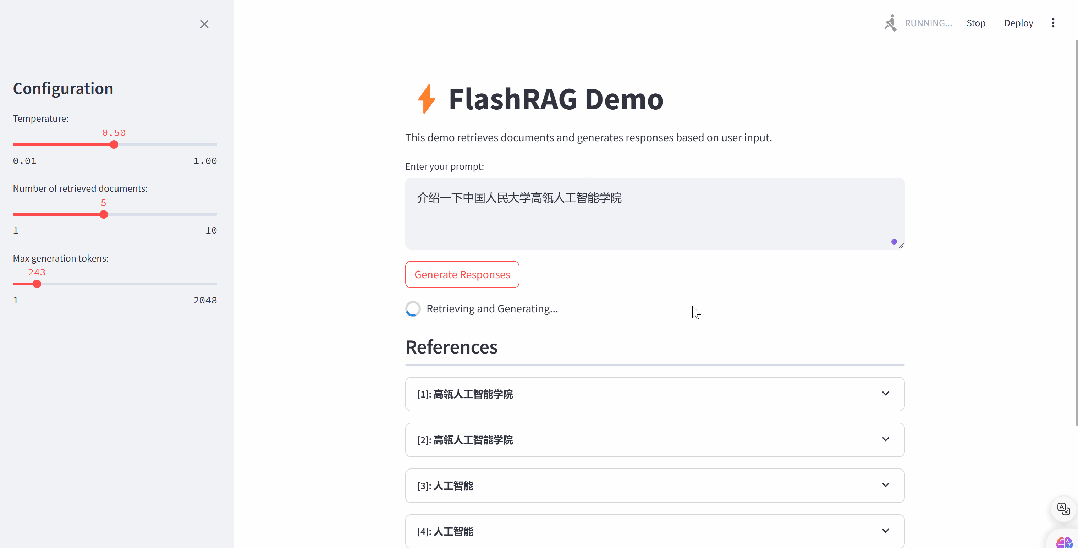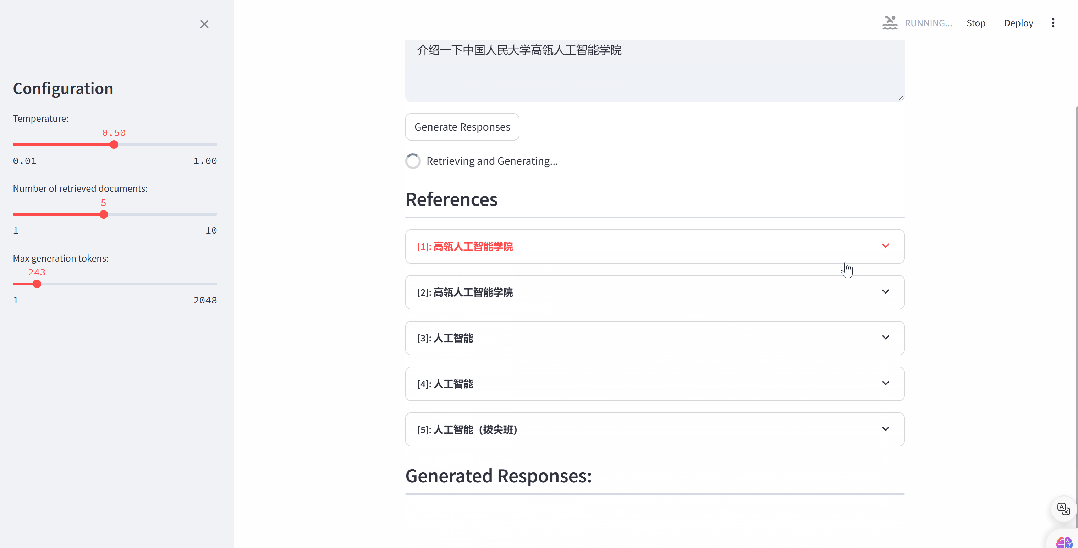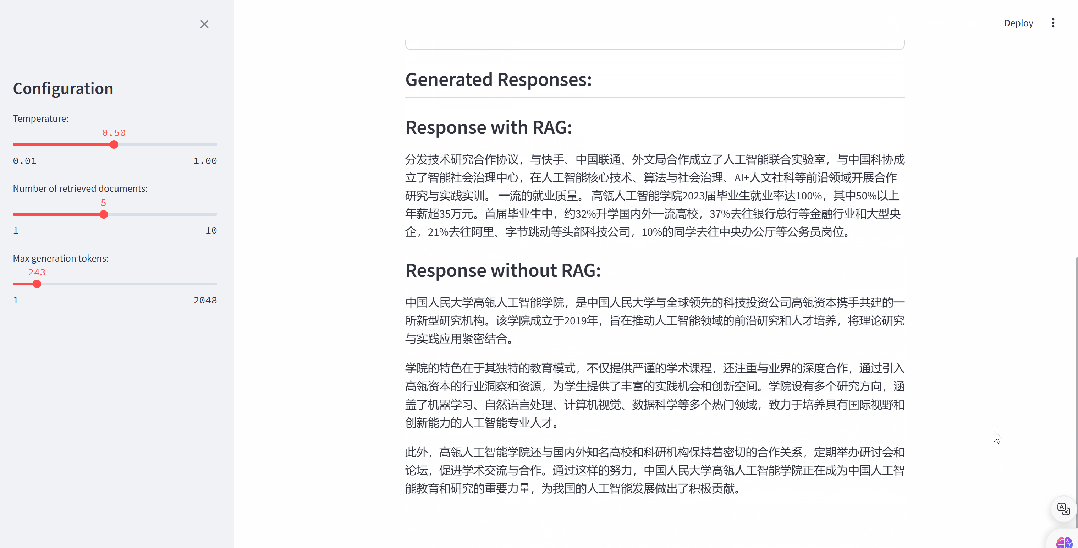
通过这段代码,RAG首先使用检索模型根据用户的查询找到最相关的文档。然后,它将这些文档信息整合到对话模板中,形成一个包含引用信息的输入提示。最后,使用生成模型根据这个输入提示来生成智能化的回应,并打印出来。
# 使⽤检索模型,根据⽤户的查询(query)来检索最相关的topk个⽂档retrieved_docs = retriever.search(query, num=topk)# 将检索到的⽂档信息整合到对话模板中,形成带有引⽤信息的输⼊提示input_prompt_with_rag = prompt_template_rag.get_string(question=query, retrieval_result=retrieved_docs)# 使⽤⽣成模型,根据带有引⽤信息的输⼊提示来⽣成回应# 这⾥可以设置⼀些⽣成参数,如temperature控制⽣成的随机性,max_new_tokens控制⽣成的最⼤⻓度response_with_rag = generator.generate(input_prompt_with_rag, temperature=temperature, max_new_tokens=max_new_tokens)[0]# 打印⽣成的回应print(response_with_rag)
5. 总结
FlashRAG-Paddle这一工具包不仅有助于现有 RAG 技术的复现,还支持新方法的开发,更重要的是,它为基于国产硬件和软件的AI应用提供了更广泛、更灵活的开发和部署选项,从而推动了AI技术的自主创新和国产化进程。
FlashRAG和FlashRAG-Paddle的所有资源已开源,我们诚挚邀请国内外的研究⼈员和开发者使用、复现和贡献代码,共同推动RAG技术的发展和国产化进程!
FlashRAG论文链接:https://arxiv.org/abs/2405.13576
FlashRAG-Paddle 链接: https://github.com/RUC-NLPIR/FlashRAG-Paddle
PaddleNLP 链接:https://github.com/PaddlePaddle/PaddleNLP
精彩活动预告
为了让您能够迅速且深入地了解高效开发与评测框架FlashRAG-Paddle,我们在官方交流群内为大家提供了核心技术解读视频课程。同时为了帮助大家更好地上手体验复杂RAG场景下的模型测试与验证,官方交流群内提供了详细的全流程使用教程文档,参与实战营活动体验任务算力全免费,成功打卡全部任务还将额外获得AI Studio算力会员卡,官方技术人员也会提供技术答疑。机会难得,立即扫描下方二维码预约吧!

(文:开源AI项目落地)