

大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
国产AI领域中,DeepSeek是比较独特的一个存在。
DeepSeek对于用户来说,可能有两个极端。不关注国内AI领域的小伙伴,可能听都没听说过它,毕竟不像Kimi和豆包铺天盖地打广告;但用过它的,可能对它的表现赞不绝口,推崇备至,毕竟它的基座模型,很强!
DeepSeek,严格意义上来说,是一家专注于研究AI模型底层技术的公司,以至于它在宣传方面几乎没有任何广告,全靠口口相传,竟然效果还不错,甚至在海外都有了一众粉丝群体,被称作“来自东方的神秘力量”;在产品上DeepSeek更是显得非常单薄,甚至到了简陋的地步,DeepSeek网页版除了一个logo和输入框,什么都没有。
然而,DeepSeek在模型方面颇有建树。它打响了国内大模型价格战的第一枪,甚至因此被网友称为“AI界的拼多多”。它陆续发布了通用模型DeepSeek V2,DeepSeek V2.5,以及昨天刚刚发布,今天这篇文章的主角:DeepSeek V3。除此之外,DeepSeek还发布了一系列视觉模型和一个推理模型DeepSeek-R1-Lite,这个模型严格意义来说是国内首个对标o1的推理模型,我在《国内首个对标o1的推理模型发布:DeepSeek-R1-Lite初体验!》这篇文章中有过详细介绍和测评。
DeepSeek V3
今天要说的是昨天刚刚正式发布并开源的通用模型DeepSeek V3。
先来看看各项技术指标。
DeepSeek-V3采用了自主研发的MoE(Mixture-of-Experts)架构,模型参数高达671B,激活参数为37B(即在实际推理过程中,每个token仅激活其中的37B参数,在保证性能的同时提升推理效率)。这个参数量是什么概念?在此之前,开源模型中的王者Llama 3.1的最大参数为405B。DeepSeek-V3的671B比Llama 3.1多了一半的参数。
在训练过程中,DeepSeek-V3使用了FP8混合精度训练,并首次在如此超大规模的模型上验证了FP8训练的可行性和有效性。通过算法、框架和硬件层面的协同设计,克服了跨节点MoE训练中的通信瓶颈,实现了近乎完全的计算与通信重叠,从而提高训练效率的同时,大幅降低了训练成本。最终,DeepSeek-V3在14.8万亿tokens的数据集上完成了预训练,而仅消耗266万H800GPU小时。
再来看DeepSeek-V3在基准测试中的表现。
这个通用模型的表现只能说是:相当厉害!DeepSeek-V3成功吊打了Qwen2.5-72B和Llama-3.1-405B这两个开源模型;闭源模型上,和GPT-4o以及Claude-3.5-Sonnet打得有来有回。但需要指出的上,此处的GPT-4o指的是0513版本,并不是最新版本。
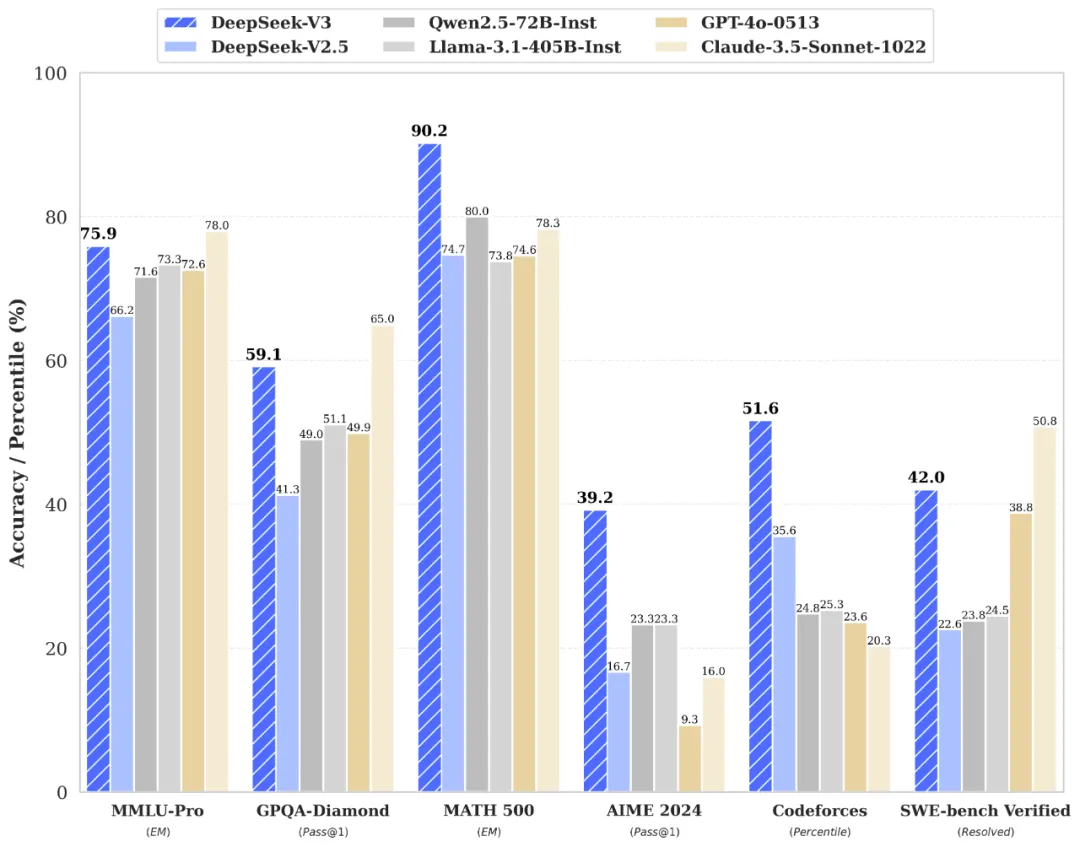
代码领域则是DeepSeek系列模型一直以来的强项,DeepSeek-V3的代码能力更是几乎可以和也是以代码能力著称的Claude-3.5-Sonnet相媲美。

另外值得一提的是DeepSeek-V3的响应速度。DeepSeek之前的模型一直因为“响应速度”被诟病,而根据DeepSeek官方的说法,DeepSeek-V3的生成速度从20TPS大幅提高至60TPS,相比较前代模型2.5实现了3倍提升。
如何使用DeepSeek V3
DeepSeek官网:https://chat.deepseek.com/
DeepSeek开发者平台:https://platform.deepseek.com/
DeepSeek V3 GitHub仓库:https://github.com/deepseek-ai/DeepSeek-V3
DeepSeek V3 抱抱脸链接:https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
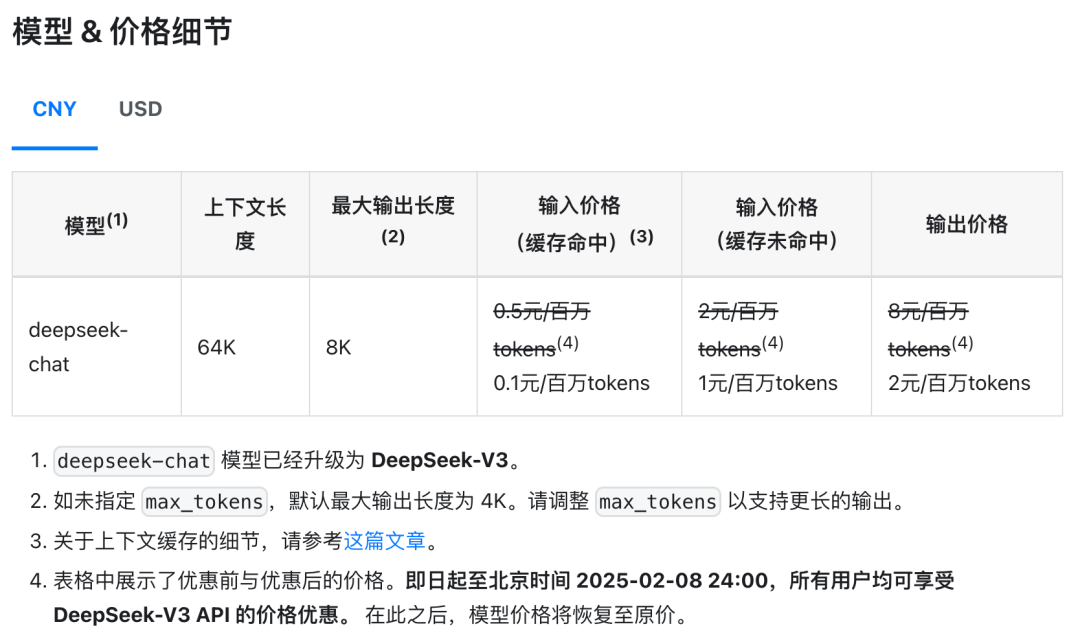
三个方式体验DeepSeek-V3模型。:在线、API、本地部署。在线最简单快捷,登录上面DeepSeek官网就行,还能使用最近上线的联网搜索以及推理模式。API调用更适合有定制化需求的小伙伴,DeepSeek-V3API价格每百万输入tokens 2元(缓存未命中),每百万输出tokens 8元,单位都是人民币,明年2月8日前有优惠。本地部署灵活性更高,可完全控制,适用于对性能、安全性、隐私有很高要求的用户。
结语
DeepSeek,你可真是国内AI领域的一股清流。
(文:AI信息Gap)