


© 作者 | 张彧
单位 | 浙江大学
研究方向 | 音乐/空间音频
多模态沉浸式空间戏剧生成旨在基于多模态提示,创建具有戏剧韵律的连续多说话人双耳语音,在增强现实(AR)、虚拟现实(VR)等领域具有潜在应用。这项任务需要基于多模态输入同时对空间信息和戏剧韵律进行建模,且数据收集成本较高。
为此,浙江大学的学者团队构建了 MRSDrama,这是首个多模态录制的空间戏剧数据集,包含双耳戏剧音频、剧本、视频、几何姿态和文本提示。随后,该团队提出了 ISDrama,即首个通过多模态提示实现的沉浸式空间戏剧生成模型。目前数据已经开源。

论文链接:
https://arxiv.org/pdf/2504.20630
Demo链接:
https://aaronz345.github.io/ISDramaDemo/
数据集链接:
https://huggingface.co/datasets/AaronZ345/MRSDrama

任务动机
双耳听觉通过声场提供定位线索,增强人类对环境的空间感知能力。这种能力对于电影、虚拟现实(VR)、增强现实(AR)等需要深度沉浸感的应用而言至关重要。
与非语言类双耳音频相比,生成双耳语音更具挑战性,但也更具前景。具体而言,基于来自不同场景的多模态提示,生成具有戏剧韵律的连续多说话人双耳语音,能够打造出沉浸式空间戏剧。这项新任务增强了叙事效果,提供了沉浸式的情感与空间体验,以及虚拟与现实的融合。
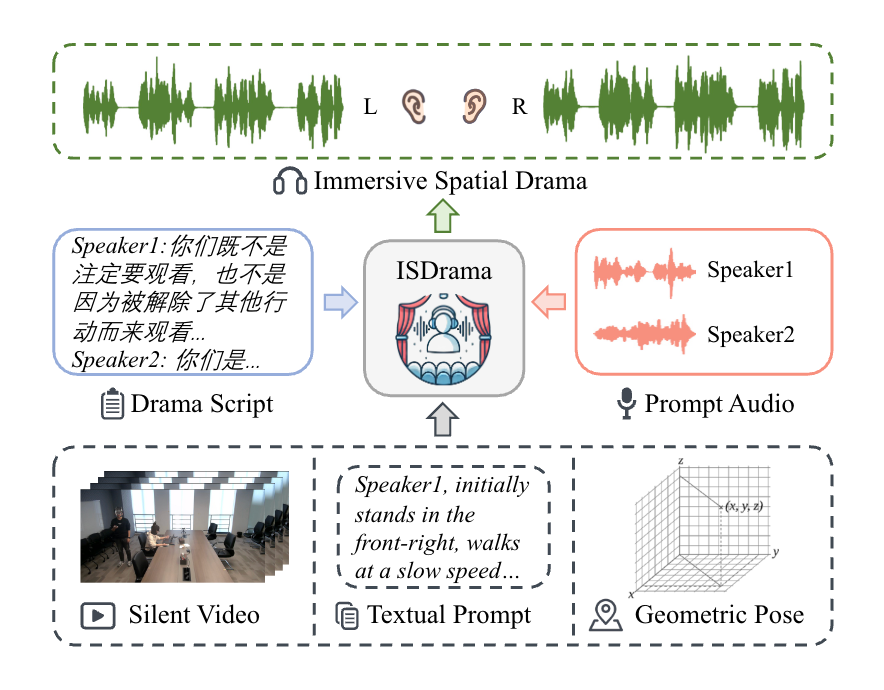
▲ 图1:ISDrama 以剧本为内容,以提示音频引导音色,并结合来自多模态提示的空间信息,生成具有戏剧韵律的连续多说话人双耳语音。
目前,多模态沉浸式空间戏剧生成面临三大挑战:
1. 缺乏高质量的带标注录制数据。模拟数据无法捕捉复杂的戏剧韵律,以及真实世界空间场景、位置和方向所产生的精确效果。
2. 难以从多模态提示中提取统一的姿态表征。无声视频、几何姿态和文本提示会提供空间信息,包括不同场景下的位置、方向和移动速度。
3. 难以在单阶段中对戏剧韵律和空间沉浸感进行建模。
为解决这些挑战,我们首先推出了 MRSDrama—— 首个多模态录制空间戏剧数据集,该数据集包含双耳戏剧音频、剧本、视频、几何姿态和文本提示。数据集涵盖了 21 名说话人在 3 个场景中录制的 97.82 小时语音数据。
接下来,我们提出了 ISDrama,首个基于多模态提示的沉浸式空间戏剧生成模型。在多模态提示的驱动下,ISDrama 能够生成高质量、连续的多说话人双耳语音,兼具戏剧韵律与空间沉浸感。
为从多模态提示中提取统一的姿态表征,我们设计了多模态姿态编码器。这是一个基于对比学习的框架,不仅对位置和头部朝向进行编码,还会对径向速度进行编码,以此考虑说话人移动产生的多普勒效应。
同时,我们研发了沉浸式戏剧转换器,这是一种基于流的 Mamba-Transformer 模型,能够高效且稳定地生成沉浸式空间戏剧。在该模型中,我们引入了 Drama-MOE(混合专家系统),它会选择合适的专家以增强韵律表现力并改进姿态控制。
此外,我们采用了上下文一致的无分类器引导(CFG)策略,以确保完整戏剧生成的质量和连贯性。

数据收集
首先,编码器利用对比学习从歌声、语音和文本提示中提取一致的表征。当从跨语言歌声或语音音频提示迁移风格时,它会提取富含风格的表征。当使用文本提示进行风格控制时,文本提示会被编码为多风格控制表征。最后,基于流的定制转换器生成预测的歌声。
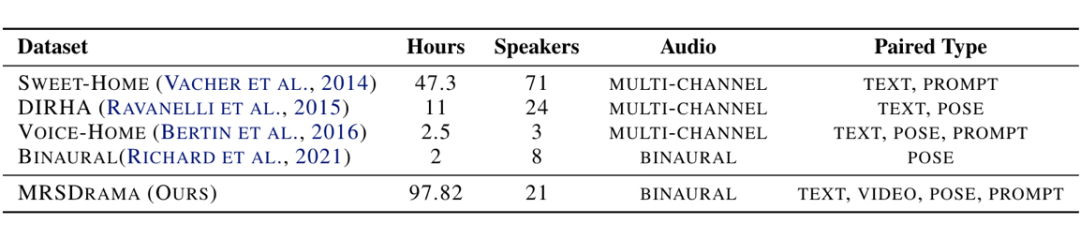
▲ 表1:现有开源录制空间语音数据集对比。多通道语音未考虑人耳的复杂结构,而双耳语音包含自然的耳间相位差(IPD)和耳间电平差(ILD),能够保证真实且具沉浸感的听觉体验。
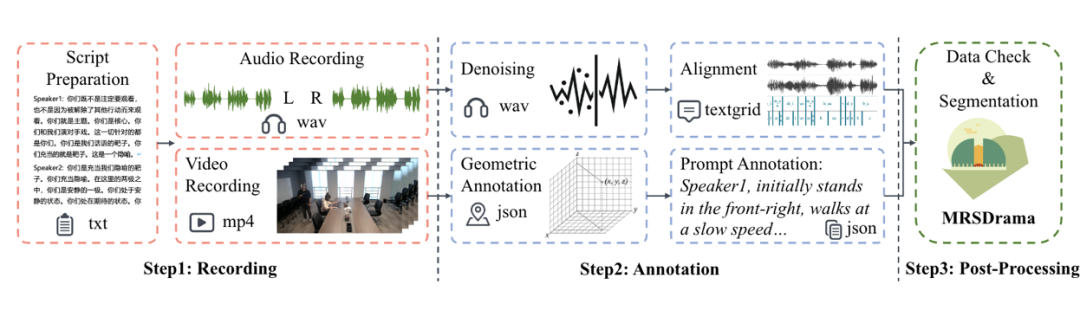
▲ 图2:MRSDrama 数据集的收集流程。每个环节都有人工双重检查。值得注意的是,所有数据均经过脱敏处理。
由于多模态空间语音的录制和标注成本较高,如表 1 所示,现有的开源录制数据集不足以支持多模态沉浸式空间戏剧的生成。同时,模拟数据无法反映真实世界空间环境中细腻的韵律变化和微妙的声学效果。
因此,我们提出了 MRSDrama—— 首个多模态录制空间戏剧数据集,其中包含双耳戏剧音频、视频、剧本、几何姿态和文本提示。我们的数据集涵盖了 21 名说话人在 3 个场景中录制的 97.82 小时语音数据。图 2 展示了其构建流程。
标注环节首先对录制好的双耳音频进行 FRCRN 去噪,然后借助 MFA 将脚本与语音做粗略音素级对齐,接着由人工在 Praat 里细致校正词与音素边界并纠正错误。
同时,视频端的标注员记录每一次移动的到达时间与空间坐标,逐帧测量说话人头部朝向和嘴部高度,提取三维位置与四元数姿态生成帧级声源位姿,并在此基础上利用 GPT-4o 自动生成体现方位、速度等要素的文本提示。
他们还同步标注摄像机的位姿及房间大小、声学效果等场景信息。整个流程设置人工双重校验以确保准确性,最后对脚本、对齐结果和位姿再次核查后,将 97.82 小时语料按说话人切分为 47 958 条、每条最长 16 秒的片段,为后续模型训练提供高质量、多模态对齐数据。
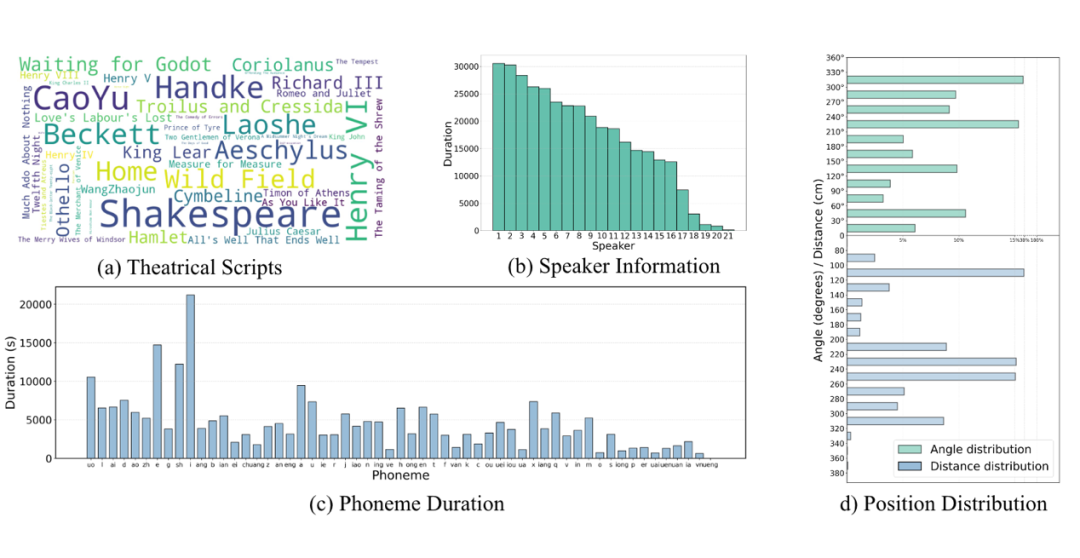
▲ 图3:MRSDrama 的统计数据。位置分布绘制在由听者的前方方向和耳朵所定义的平面上。

模型方法
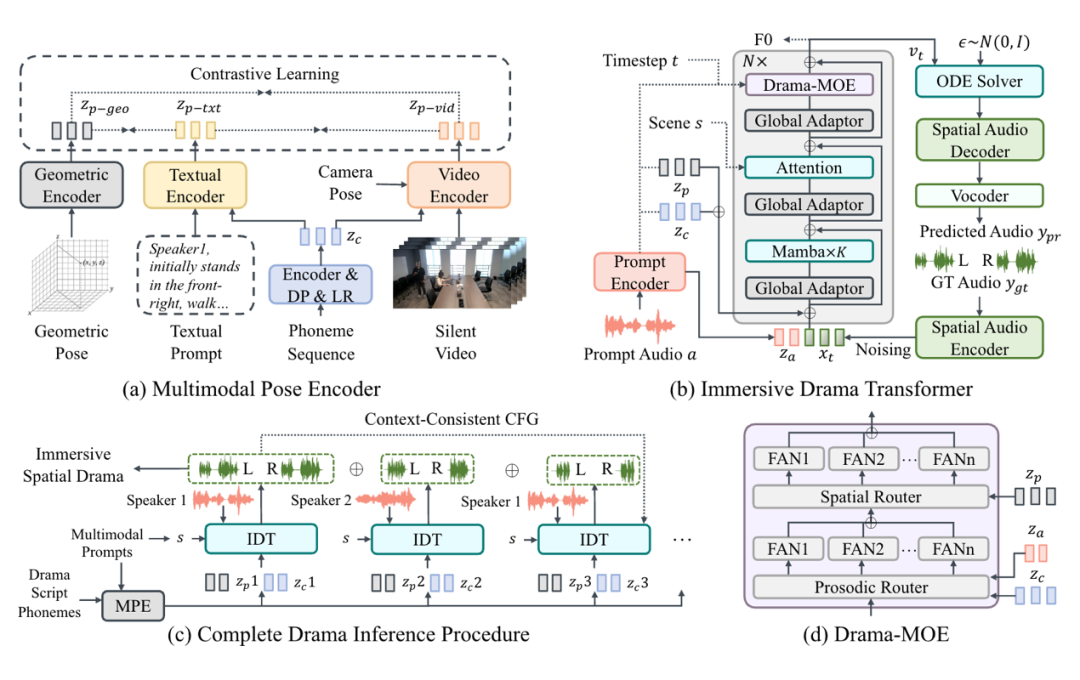
▲ 图4:ISDrama 的架构。在图(a)中,DP & LR 指时长预测器和长度调节器。在图(b)中,常微分方程求解器、自编码器解码器和声码器在推理过程中根据条件从高斯噪声生成预测音频。在图(c)中,MPE 是多模态姿态编码器,IDT 表示沉浸式戏剧转换器。MPE 预测内容时长并对输入进行分段,之后 IDT 连贯地生成完整戏剧。在图(d)中,FAN 指傅里叶分析网络。
多模态姿态编码器
我们设计了多模态姿态编码器,它能从多模态提示中预测出统一的姿态嵌入。如图 4(a)所示,我们的模型对三类多模态提示进行编码,并将它们嵌入到一个统一的空间中。
针对几何姿态,我们不仅对头部方向和以及声源相对于左右耳的三维坐标进行编码,还根据多普勒效应加入了径向相对速度,以用于相位估计。
具体来说,我们先计算移动声源在笛卡尔坐标系中的三维速度向量,然后通过相关公式,将其分别分解为左右耳球坐标系中的径向速度分量,其中是径向单位向量。最后,我们可以对相关参数进行编码并拼接,得到对应的结果。
为确定目标嵌入长度,并考虑语义、语速和动作之间的关系,我们对内容的发音和语义进行编码,并利用预测的音素时长对其进行扩展。内容作为输入并利用不同的模态条件。
对于文本提示,我们使用 FLAN-T5 对文本进行编码以作为条件。对于无声视频,我们将相机姿态、来自 Co-Tracker3 的嘴巴像素序列以及来自 CLIP 的嵌入向量进行拼接,以此作为条件。在获得这三种模态的姿态嵌入后,我们为对比学习损失来训练他们。
沉浸式戏剧Transformer
沉浸式戏剧 Transformer 是一种基于流匹配的 Mamba-Transformer 架构,在生成阶段首先向自动编码器输出添加高斯噪声,并将其与脚本内容向量、姿态向量及提示音频向量相加拼接,通过交替的自注意力层与轻量化的Mamba块捕捉长程时频与时空依赖,以实现对内容、姿态、音色和发音的联合建模。
同时,场景信息经跨注意力机制融入,模拟不同房间大小和声学效果对双耳信号的影响;在第一模块输出额外预测基音频率,为后续模块提供辅助监督以强化戏剧情感的节奏控制;为增强模型训练的稳定性与音色一致性,还引入 RMSNorm 和基于 AdaLN 的全局适配器。
在此基础上,Transformer 内部集成了 Drama-MOE 混合专家模块,分设戏剧韵律专家与空间专家,依据提示音频与姿态信息动态选取最适合的专家以细化语调与空间定位。我们使用 FAN 作为专家,从而捕捉语音信号的周期性特质。
我们通过注意力与 Mamba 层的比例平衡,该模型在处理长序列时既能保持内存与计算效率,也能快速、稳定地产出高质量的多说话人沉浸式双耳剧场语音。
完整戏剧推理流程
在推理阶段,用户提供完整的戏剧脚本并为每位角色指定提示音频,系统首先根据脚本中的说话人切换将目标戏剧切分为若干片段。
接着,多模态姿态编码器预测每段的内容时长并输出对应的内容向量和姿态向量,随后沉浸式戏剧 Transformer 从高斯噪声出发,通过交替的自注意力与 Mamba 块生成每段双耳语音。
为了增强段内及段间的韵律一致性,我们设计了上下文一致的无分类器指导(CFG)策略,该策略在推理时同时利用提示音频与同一说话人上一次预测的音,以两种比例系数对模型输出向量场加权。
从而提高了生成质量,并融入了先前生成的音频,以增强同一戏剧幕中同一说话人的韵律一致性。这在保持原始提示音频的音色和口音的同时,确保了连贯性。由于韵律可以从同一语境中先前的提示音频中习得,这种方法还能提升语义对齐韵律的表现力。

实验结果
首先,我们对单声道音频进行测试。
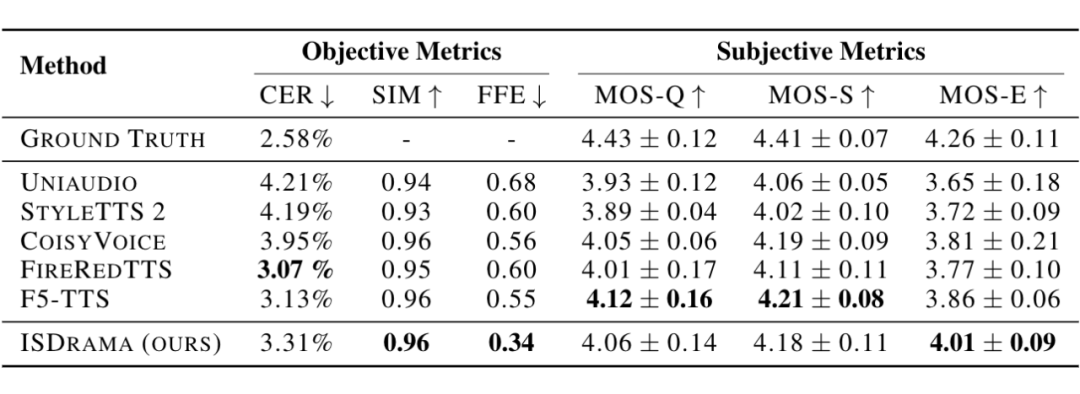
▲ 表2:单耳语音质量对比。为测试质量和说话人相似度,我们采用单句语音进行评估。
接着,基于 ITD、ILD 以及通过 SPATIAL-AST 预测的角度和距离,我们设计了空间化的指标,以衡量双耳生成的性能。这里对于 baseline 模型,我们使用 BinauralGrad 来进行单声道到多声道音频的转换。
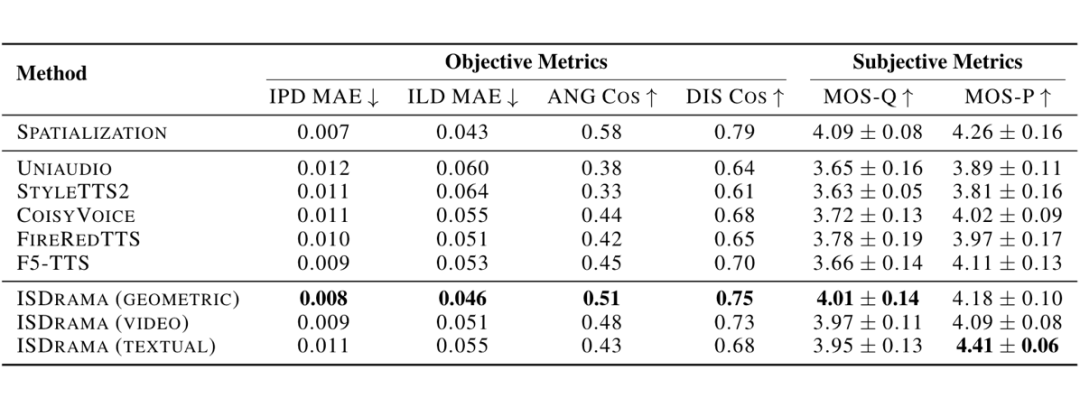
▲ 表3:双耳语音质量对比。我们使用完整戏剧进行空间评估。ANG 和 Dis 分别表示角度和距离。空间化是指基于几何姿态直接从真实单耳音频生成双耳音频。

总结展望
本文提出了一项新任务,多模态沉浸式空间戏剧生成,该任务旨在基于多模态提示生成具有戏剧化韵律的连续多说话人双耳语音。
为支持这项任务,我们构建了首个多模态录制空间戏剧数据集 MRSDrama,其中包含双耳戏剧音频、剧本、视频、几何姿态和文本提示。随后,我们提出了首个基于多模态提示的沉浸式空间戏剧生成模型 ISDrama。
实验结果表明,在客观和主观指标上,ISDrama 的性能均优于基线模型。
(文:PaperWeekly)