


本工作由中科院计算技术研究所团队主导完成,旨在为未来的上下文感知智能体系统提供清晰的理论基础与系统蓝图。
论文标题:
A Survey of Context Engineering for Large Language Models
论文全文:
https://arxiv.org/abs/2507.13334
配套资源库:
https://github.com/Meirtz/Awesome-Context-Engineering
Hugging Face 页面:
https://huggingface.co/papers/2507.13334

Motivation与背景
大型语言模型(LLMs)的性能从根本上取决于其在推理过程中获得的上下文信息。随着 LLMs 从简单的指令遵循系统发展为复杂应用的推理核心,如何设计和管理其信息有效载荷已演变为一门正式的学科。
传统的“提示工程”(Prompt Engineering)概念已不足以涵盖现代AI系统所需的信息设计、管理和优化的全部范围。这些系统处理的不再是单一、静态的文本字符串,而是一个动态、结构化且多方面的信息流。
上下文工程(Context Engineering)的出现,旨在超越简单的提示设计,系统性地优化供给 LLMs 的信息有效载荷。
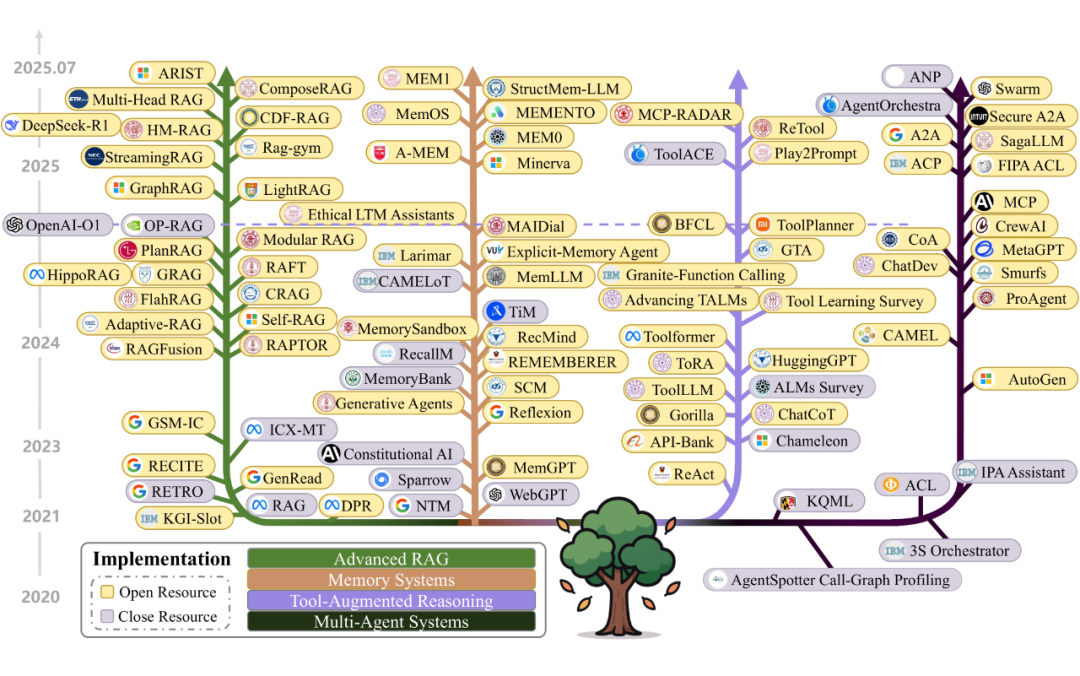
然而,上下文工程领域的研究虽然发展迅速,却呈现出高度专业化和碎片化的特点。现有研究大多孤立地探讨特定技术,如检索增强生成(RAG)、智能体系统(Intelligent Agent Systems)或长上下文处理等,缺乏一个统一的框架来系统地组织这些多样化的技术,阐明其内在联系。
为了应对这一挑战,本篇综述对超过 1400 篇研究论文进行了系统性分析,首次对 LLMs 的上下文工程进行了全面和系统的回顾,旨在为研究人员和工程师提供一个清晰的技术路线图,促进对该领域的深入理解,催化技术创新。

论文内容详解
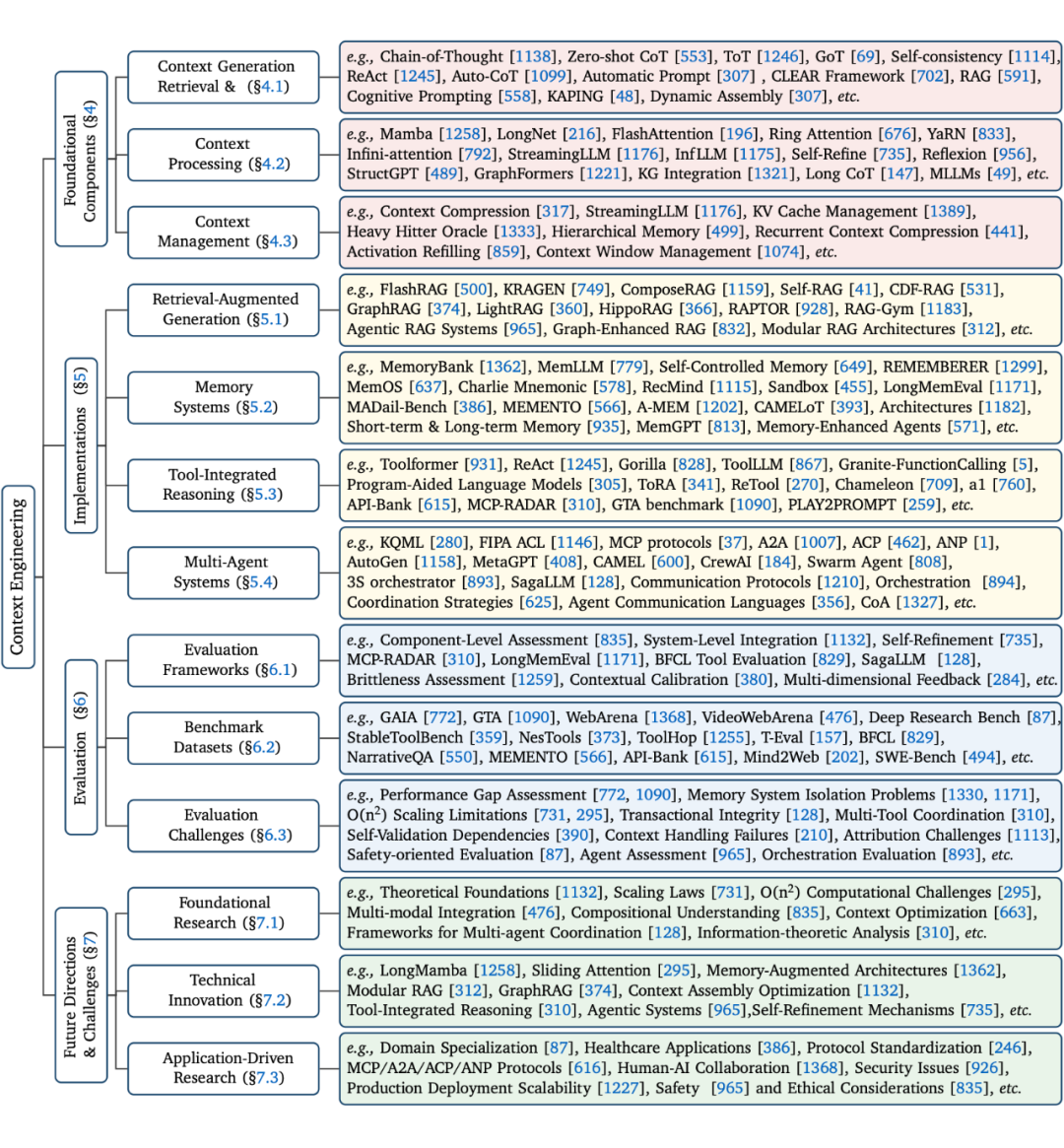
本综述的核心贡献是提出了一个将上下文工程分解为基础组件(Foundational Components)和系统实现(System Implementations)的分类框架。
2.1 上下文工程的定义与形式化
我们首先对上下文工程进行形式化定义。对于一个自回归的 LLM,其模型参数为 θ,在给定上下文 C 的条件下,生成输出序列 的过程可以表示为最大化条件概率:
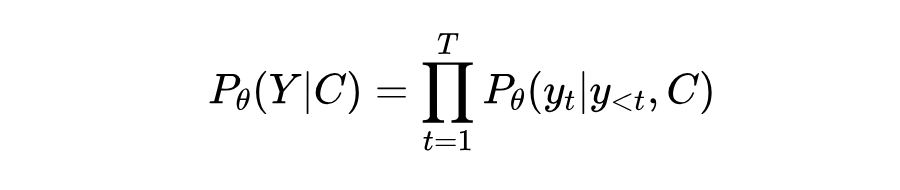
传统提示工程将上下文 C 视为一个单一的文本字符串,即 C=prompt。上下文工程则将 C 重新概念化为一个由多个信息组件 动态构成的结构化集合。
这些组件由一系列函数进行获取、过滤和格式化,并最终由一个高阶的组装函数 A 进行编排:
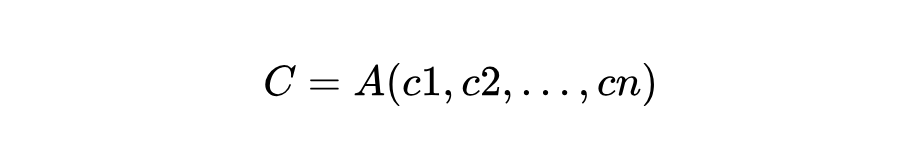
这些组件 对应了本综述的核心技术领域:
-
:系统指令和规则。 -
:通过 RAG 等功能检索到的外部知识。 -
:可用外部工具的定义和签名。 -
:来自先前交互的持久化信息。 -
:用户、世界或多智能体系统的动态状态。 -
:用户的即时请求。
基于此,上下文工程的优化问题可以定义为:寻找一组最优的上下文生成函数集合 F(包括 A、检索、选择等函数),以最大化 LLM 输出质量的期望值。给定任务分布 T,其目标是:
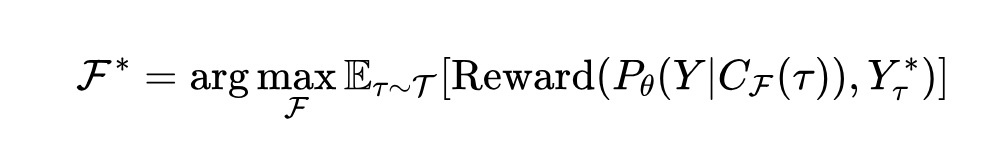
其中, 是一个具体的任务实例, 是由函数集 F 为该任务生成的上下文, 是理想的输出。这个优化过程受到模型上下文长度限制 等硬性约束。
2.2 上下文工程的基础组件
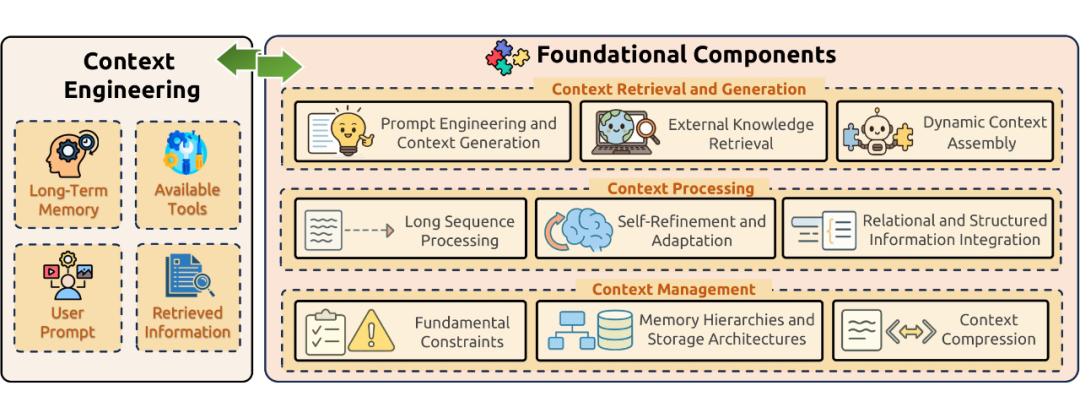
基础组件是上下文工程的基石,我们将其分为三个关键阶段:
2.2.1 上下文检索与生成(Context Retrieval and Generation)
该组件负责获取相关的上下文信息,包含三个主要机制:
-
提示工程与上下文生成:设计有效的指令和推理框架,如思维链(Chain-of-Thought, CoT)、思维树(Tree-of-Thoughts, ToT)和思维图(Graph-of-Thoughts, GoT)等,以引导模型的思考过程。
-
外部知识检索:通过检索增强生成(RAG)等技术,动态访问外部信息源,如数据库、知识图谱和文档集合,以克服模型参数化知识的局限性。
-
动态上下文组装:将获取到的不同信息组件(如指令、知识、工具)编排成一个连贯的、为特定任务优化的上下文。
2.2.2 上下文处理(Context Processing)
该组件负责转换和优化获取到的信息,主要包括:
-
长上下文处理:解决 Transformer 架构中自注意力机制带来的 O(n2) 复杂度问题,通过架构创新(如状态空间模型 Mamba)、位置插值和优化技术(如 FlashAttention)来处理超长序列。
-
上下文自精炼与适应:使 LLMs 能够通过迭代反馈循环(如 Self-Refine 框架)来改进输出,或通过元学习(Meta-Learning)和记忆增强机制实现对新任务的快速适应。
-
多模态及结构化上下文:将文本以外的数据模式(如图像、音频)和结构化数据(如知识图谱、表格)整合到统一的上下文中,是当前面临的核心挑战之一。
2.2.3 上下文管理(Context Management)
该组件关注上下文信息的有效组织、存储和利用,包括:
-
基本约束:应对有限上下文窗口带来的“中间遗忘”(lost-in-the-middle)现象和计算开销等根本性限制。
-
记忆层次与存储架构:借鉴操作系统的虚拟内存管理思想,设计分层的记忆系统(如 MemGPT),在有限的上下文窗口和外部存储之间进行信息交换。
-
上下文压缩:通过自编码器、循环压缩或基于记忆的方法减少上下文的计算和存储负担,同时保留关键信息。
2.3 上下文工程的系统实现
基础组件是构建更复杂的、面向应用的系统实现的基石。本综述探讨了四种主要的系统实现方式:
2.3.1 检索增强生成(Retrieval-Augmented Generation, RAG)
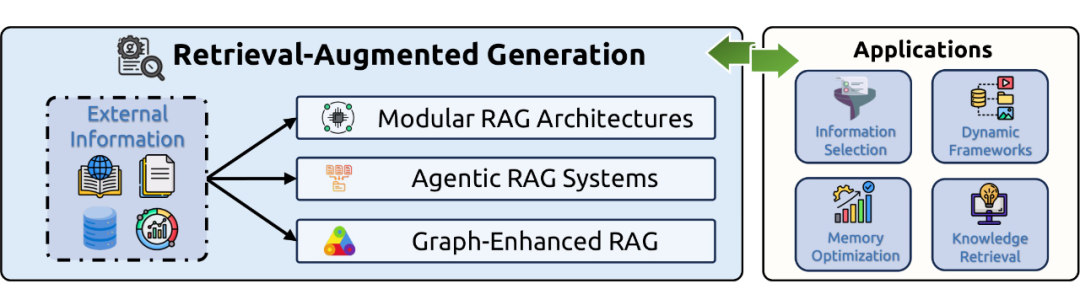
RAG 系统将外部知识源与 LLM 的生成过程相结合,已从简单的线性流程演变为更复杂的架构:
-
模块化 RAG:将 RAG 流程分解为可重新配置的模块,实现了灵活的组件交互和定制化。
-
智能体 RAG(Agentic RAG):将自主 AI 智能体嵌入 RAG 流程,通过持续的推理、规划和工具使用来动态管理检索策略。
-
图增强 RAG(Graph-Enhanced RAG):利用知识图谱等结构化知识表示来捕捉实体关系,支持多跳推理,并减少上下文漂移和幻觉。
2.3.2 记忆系统(Memory Systems)
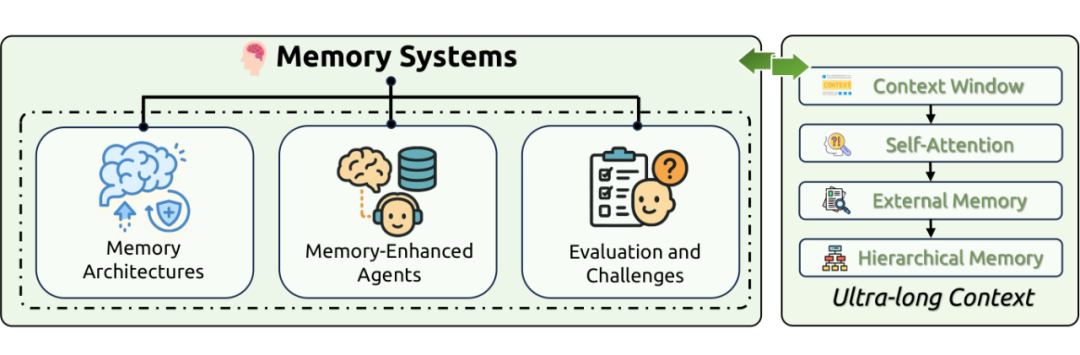
记忆系统使 LLMs 能够超越无状态的交互模式,实现信息的持久化存储、检索和利用。这些系统通常被划分为短期记忆(在上下文窗口内操作)和长期记忆(利用外部数据库或专用结构)。记忆增强的智能体在个性化对话、任务规划和社交模拟等领域展现了巨大潜力。
2.3.3 工具集成推理(Tool-Integrated Reasoning)
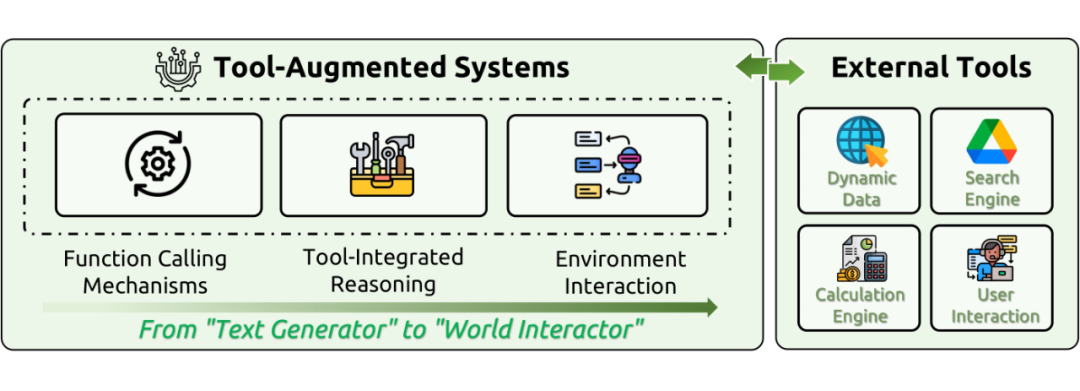
该实现将 LLMs 从被动的文本生成器转变为主动的世界交互者。通过函数调用(Function Calling)机制,LLMs 能够利用外部工具(如计算器、搜索引擎、API)来克服其内在的知识过时、计算不准确等局限性。这要求模型能够自主选择合适的工具、解释中间输出并根据实时反馈调整策略。
2.3.4 多智能体系统(Multi-Agent Systems)
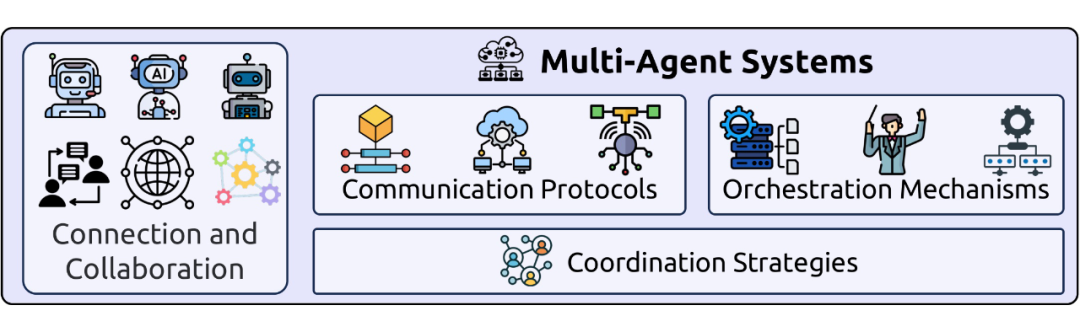
多智能体系统是协作智能的顶峰,允许多个自主智能体通过复杂的通信协议、编排机制和协调策略进行协作,以解决单个智能体无法完成的复杂问题。LLMs 的引入极大地增强了智能体在规划、专业化和任务分解方面的能力。

小结与未来展望
本综述通过建立一个统一的分类框架,系统性地梳理了上下文工程这一新兴领域。我们的分析揭示了一个关键的研究空白:当前模型在理解复杂上下文方面表现出色,但在生成同等复杂的长篇输出方面存在明显局限。弥合这一“理解-生成”差距是未来研究的重中之重。
未来的研究方向和挑战包括:
-
基础研究挑战: 建立统一的理论基础和数学框架,研究上下文工程的缩放定律,并解决多模态信息的整合与表示问题。
-
技术创新机遇: 探索新一代架构(如状态空间模型),发展更高级的推理与规划能力,并实现智能化的上下文组装与优化。
-
应用驱动的研究: 针对特定领域(如医疗、科研)进行深度专业化,实现大规模多智能体的协调,并促进人与AI的协同。
-
部署和社会影响: 解决可扩展性、安全性、鲁棒性和伦理等在生产部署中面临的实际问题。
总之,上下文工程是推动 AI 系统从理论走向现实、从单一能力走向综合智能的关键。我们希望这篇综述能为从事大模型系统、Agent 设计、RAG 架构、结构化数据融合等研究的读者提供系统性参考,也欢迎关注我们的持续更新和后续研究进展。
(文:PaperWeekly)