
今天这篇文章,我们一起来看看如何使用pytorch memory snapshot,分析模型训推中的显存消耗。在阅读本文前,推荐大家先阅读这篇blog:https://huggingface.co/blog/train_memory,从中大致了解这个工具的使用流程。
本文不会讨论怎么用这个工具,而是侧重于“如何解读这个工具所记录的内容”。本文以混合精度训练为例:
-
介绍了如何解读“数据加载-fwd-bwd-权重更新”中,每个步骤下显存管理的所有细节。
-
介绍如何根据显存记录的堆栈信息,有针对性地复查源码
(为了尽可能大白话讲解,本文对一些术语的使用并不严谨,请读者见谅)
一、1个简单的例子
import torch
from torch.cuda import memory
# 开启memory snapshot记录
memory._record_memory_history(max_entries=100000)
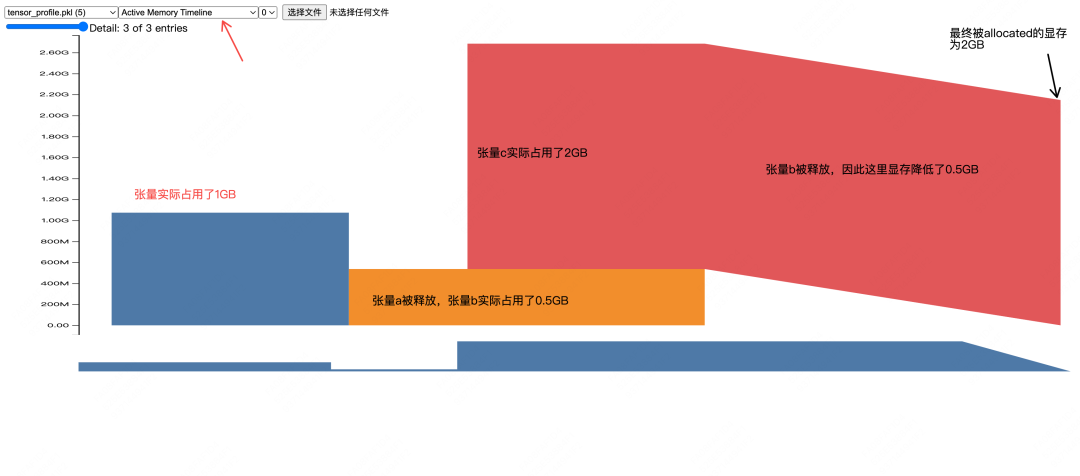
# (1) 分配缓存区:分配一个大小为1GB的缓存区,记为cache1
# (2) 往缓存区中装入张量:往cache1中放入大小同样为1GB的张量a
a = torch.ones((1024, 1024, 256), device='cuda')
# (1)删除该张量的引用
# (2)对应张量的引用计数(reference count)变为0,自动启用python的垃圾回收机制,将该张量从cache1中释放
# (3)但cache1不会立刻被释放(即不会立刻被返还给系统),这块空间会留给后续的张量复用。
# 这样可以避免频繁向cuda driver申请存储空间,提升整体效率
del a
# (1) 复用缓存区:复用cache1
#(2)往缓存区中装入张量:往cache1中放入大小为0.5GB的张量b
b = torch.ones((1024, 1024, 128), device='cuda')
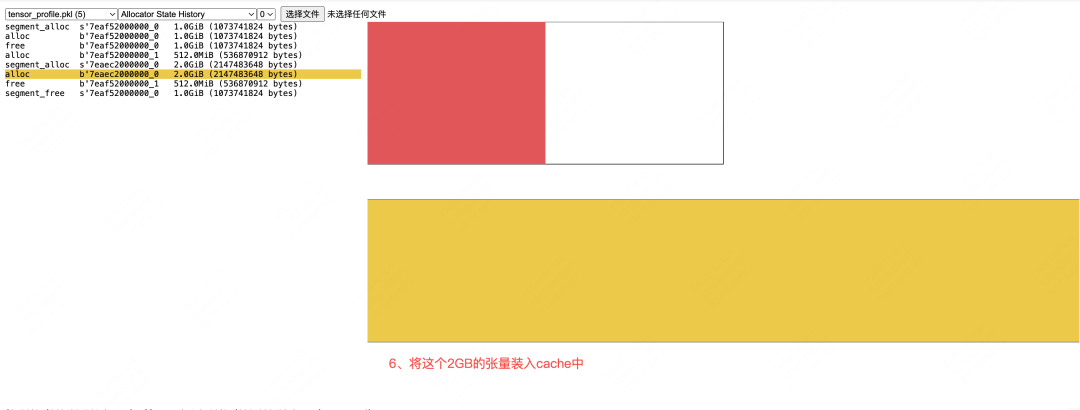
# (1) 新分配缓存区:由于张量c较大,所以新分配一个2GB的缓存区,记为cache2
# (2) 往缓存区中装入张量:往cache1中放入大小为2GB的张量c
c = torch.ones((1024, 1024, 512), device='cuda')
# 为这个2GB的张量多设置一个引用
d = c
# (1) 释放 b (被从缓存区中移除)
# (2) c无法释放,因为引用计数没有归0
del b, c
# (1) cache1中没有存放任何东西,可以释放了
# (2) cache2中存放的数据还有变量d引用,所以不可以释放
torch.cuda.empty_cache()
# 保存内存快照记录
memory._dump_snapshot("tensor_profile.pkl")
memory._record_memory_history(enabled=None) # 停止记录
注:在以上代码中,我们提到分配缓存区,这其实是不严谨的,具体来说首次执行segment_alloc时,我们分配的是一块连续的显存段,只是当这个显存段中没有数据时,我们不会立刻释放它,而是把它cache下来(这又是一个不严谨的描述,它进一步可以展开成若干流程,这边就不细说了),方便未来的数据复用它,这样节省了重新申请显存段所花费的时间。为了表达简便,我这里统一都把它喊成cache了。







二、AMP混合精度训练
2.1 单层模型
(1)代码
from torch.cuda import memory
import torch
import torch.nn as nn
import torch.optim as optim
from torch.cuda.amp import autocast, GradScaler
memory._record_memory_history(max_entries=100000)
# 设置设备(优先使用GPU)
torch.manual_seed(42)
weight_shape = [1024*8, 1024*32]
data_shape = [1024*16, 1024*8]
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
print(f"Using device: {device}")
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.weight = nn.Parameter(torch.randn(weight_shape, dtype=torch.float32))
def forward(self, x):
return x @ self.weight
# 初始化模型
model = CustomModel().to(device)
# 初始化优化器和混合精度工具
optimizer = optim.Adam(model.parameters(), lr=0.001)
scaler = GradScaler()
# 训练循环
num_epochs = 4
for epoch in range(num_epochs):
print(f"正在执行第{epoch}个epoch")
total_loss = 0.0
data = torch.randn(data_shape, device=device)
# 混合精度上下文
with autocast():
output = model(data)
# 简化损失函数:输出值的L1范数
loss = torch.mean(torch.abs(output))
# 反向传播
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# 保存内存快照记录
memory._dump_snapshot("pytorch_autocast.pkl")
memory._record_memory_history(enabled=None) # 停止记录
为了方便观测数据,我们设weight和data的大小如下:
(1)weight大小为1GB(fp32下)
(2)输入的data大小为512MB(fp32下)
[fwd过程如下]
output = data * weight
loss = mean(abs(output))
[bwd过程如下]
(1) 计算grad_mean_output
(2) 计算grad_abs_output
(3) 计算grad_output = grad_mean_output * grad_abs_output
(4) 计算grad_weight = grad_output * data
结合代码可知,我们给的原生weight和data都是fp32形式的,将由autocast自动做fp16的转换,以此实现混合
精度训练
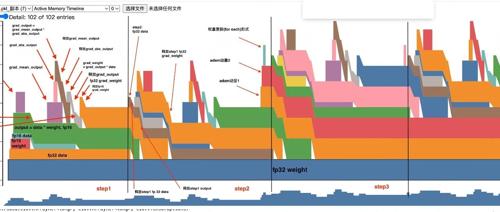
(2)Active Memory Timeline
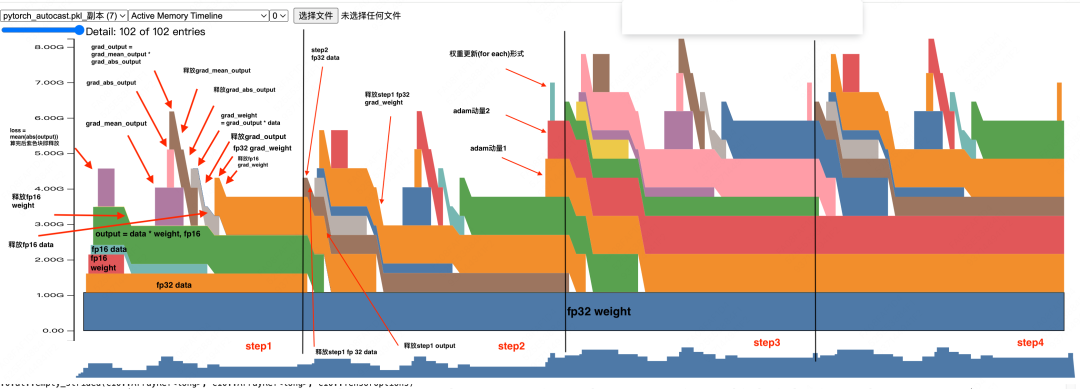
【fwd的显存分配如下】
-
Allocate fp32 weight, 1GB -
Allocate fp32 data, 512MB -
Allocate fp16 weight(由fp32 weight转换而来),512MB -
Allocate fp16 data(由fp32 data转换而来),256MB -
Allocate fp16 output = fp16_data * fp16_weight,1GB -
释放fp16 weight,但fp16 data不可以释放,因为后续在反向传播的过程中,还需要用到它来计算weight的梯度 -
Allocate fp16 `loss = mean(abs(ouput))“,1GB。这是用来计算loss所分配的临时显存,abs(output)不是原位操作,会开辟新的显存空间,算完之后这块空间可以释放(根据我们的代码,这里还会涉及到将loss转为fp32并做scaled的过程,这边也会涉及极小的一部分显存分配,这里略去不提)
【bwd的显存分配如下】
-
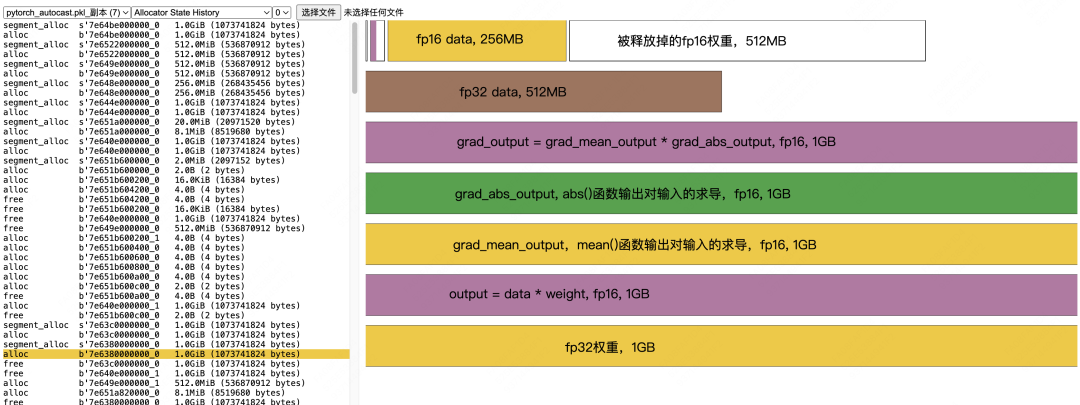
Allocate fp16 grad_mean_output, 1GB -
Allocate fp16 grad_abs_output, 1GB -
Allocate fp16 grad_output = grad_mean_output * grad_abs_output,1GB -
释放 fp16 grad_mean_output -
释放 fp16 grad_abs_output -
Allocate fp16 grad_weight = grad_output * fp16_data,512MB -
释放 fp16 grad_output -
释放fp16 data -
Allocate fp32 grad_weight,1GB。在混合精度训练中,我们需要把fp16的梯度转成fp32的梯度,用于模型权重更新 -
释放 fp16 grad_weight,一旦我们生成了fp32的梯度副本,就可以将原始fp16的梯度释放掉了
到此我们step1的整个过程就讲完了,但你心中必定会有如下疑问,我们一一解答。
【问题1:step1怎么没有权重更新呢?】
观察上图我们可以发现,直到step2的结尾,才开始对adam的2个动量做初始化(从此以后这2个动量一直固定在分配的这块显存里,正如fp32权重那样),而在step1结尾却没有做这样的事。
本质上,这是因为step1中算出的梯度出现了nan/inf的情况,所以我们无法走到权重更新这一步。而adam优化器的动量初始化又是惰性的(直到第一次权重更新才会做初始化),所以才出现了以上种种现象。
(注意:这里准确地应该说是adam一阶矩和二阶矩的初始化,我觉得拗口,统一都叫动量1和动量2了,没错简直是胡乱瞎叫,大家知道就好)
【问题2: output = data * weight为什么要等到step2才做释放?】
理论上,当我们算出grad_abs_output之后,output这个激活值就不再需要了。在我们的印象里,随着bwd过程的层层向下传播,已经被使用过的激活值就可以释放了,可是这个output又是为什么保存下来了呢?
本质上,这是因为我们的代码中出现了output = model(data),所以output对应的数据始终有output这个变量在引用它,所以它不会被释放。因此,直到step2执行到这行代码后,step1中的这块数据的变量引用才变为0,所以它是在step2中被释放的。
在后文的例子中,我们会给出一个含有2个linear层的模型的例子:
# forward计算
output1 = data * weight1
output2 = output1 * weight2
# loss计算
loss = mean(abs(output2))
在这个例子里你就会发现,同样是激活值,output1在step1中使用完毕后就被释放,但output2同样需要等到step2中才能被释放。
【问题3:fp32的grad_weight释放时机是什么?】
我们知道,在step1结尾,我们allocate了fp32 grad_weight,但是由于梯度出现了nan/inf,我们并没有用它来执行fp32的权重更新步骤。这个step1 fp32 grad_weight将等到step2的fwd结束后、bwd开始前才会被释放(参见图例),这个释放时机和amp内部的实现有关。
【问题4:Active Memory Timeline看着不好解读,我该怎么样才能找到尽可能多的细节呢】
大家可以发现,在这张图中,我对显存分配和释放的时机、以及对应的具体代码操作做了非常细致的标注,那么我是怎么知道这些细节的呢?这里给出我个人的一些tips:
-
首先,善用snapshot下方给出的调用堆栈信息,定位到具体的代码和算子上进行分析。 -
其次,除了Active Memory Timeline外,我还推荐大家配合Allocate State History具体阅读(在上面你可以看到具体的显存分配、数据装载、数据释放过程,我们在下文马上就来解读这个)。 -
最后,以训练为例,其实整个过程无非是 数据加载、fwd、bwd、权重更新。我们这个代码例子很简单,所以可以非常细致地分析整个过程。在实际操作中,我们可以配合其他分析结果,在自己认为需要分析的地方保存snapshot(有时候算子太多/代码太复杂,保存下来的文件太大,是打不开的,所以可以分段式进行保存)。
(3)Allocate State History
有了上面的一些介绍,大家看这块应该很容易了,这边我就给出一些直接的解读,从中你还可以看到分配的cache是如何重复被各种数据使用的。
data和weight的加载与精度转换:
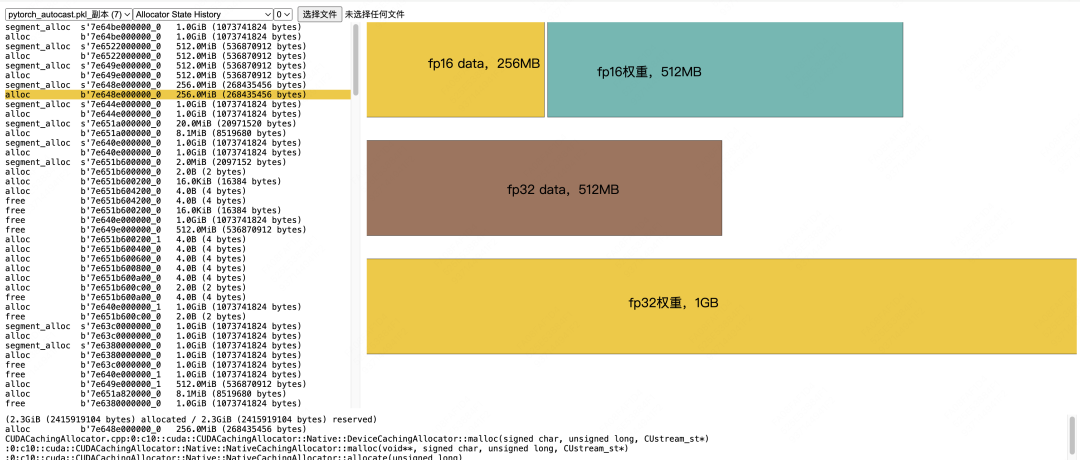
Output和loss计算:
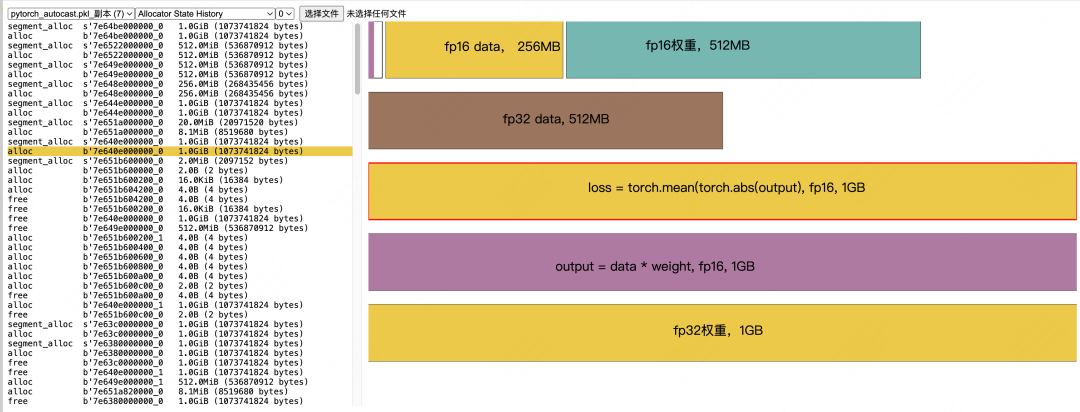
loss计算完毕后的显存释放:

grad_output的计算和计算完毕之后的显存释放:
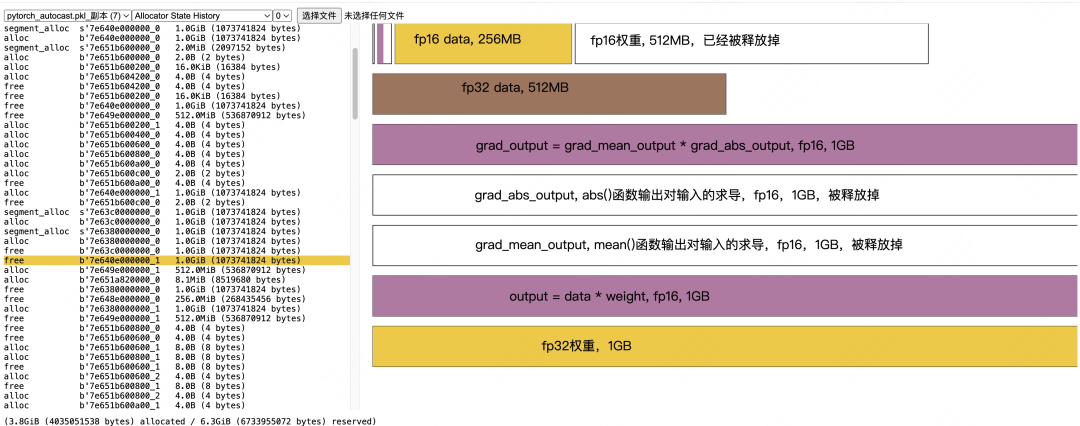
fp16 grad_weight计算,以及计算完毕后的数据释放
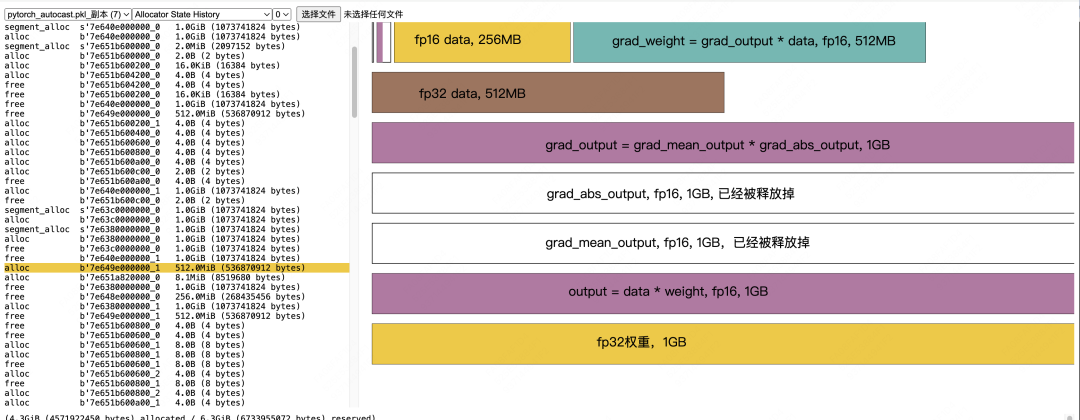
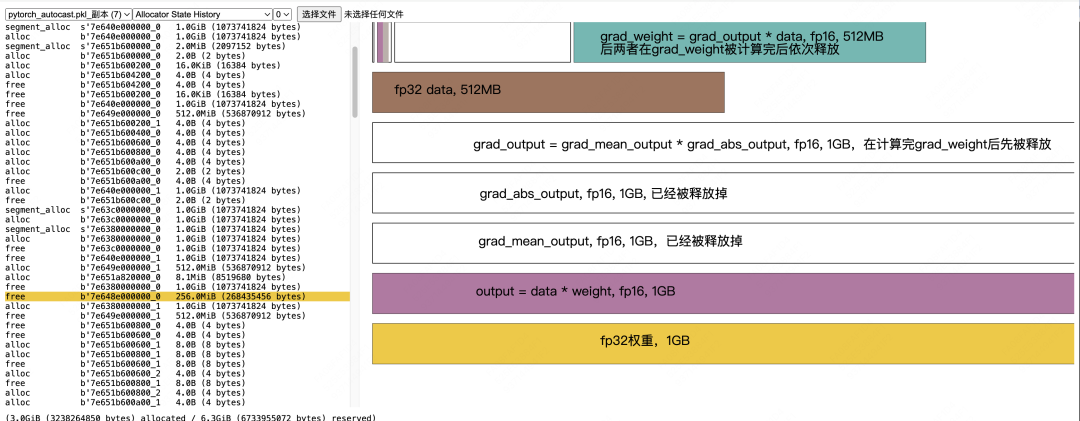
fp16 grad_weight -> fp32 grad_weight:

2.2 双层模型
(1)代码
from torch.cuda import memory
import torch
import torch.nn as nn
import torch.optim as optim
from torch.cuda.amp import autocast, GradScaler
memory._record_memory_history(max_entries=100000)
# 设置设备(优先使用GPU)
torch.manual_seed(42)
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
print(f"Using device: {device}")
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(1024*16, 1024*8, bias=False)
self.linear2 = nn.Linear(1024*8, 1024*16, bias=False)
def forward(self, x):
x = self.linear1(x)
x = self.linear2(x)
return x
# 初始化模型
model = CustomModel().to(device)
# 初始化优化器和混合精度工具
optimizer = optim.Adam(model.parameters(), lr=0.001)
scaler = GradScaler()
# 训练循环
num_epochs = 4
for epoch in range(num_epochs):
print(f"正在执行第{epoch}个epoch")
total_loss = 0.0
data = torch.randn((1024*4, 1024*16), device=device)
labels = torch.randn((1024*4, 1024*16), device=device) # 新增labels张量
# 混合精度上下文
with autocast():
output = model(data)
# loss:output和labels间的mean sqrt
# 计算平方根误差的平均值
sqrt_errors = torch.sqrt(torch.abs(output - labels))
loss = torch.mean(sqrt_errors)
# 反向传播
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# 保存内存快照记录
memory._dump_snapshot("pytorch_autocast_double_layer4.pkl")
memory._record_memory_history(enabled=None) # 停止记录
为了方便观测数据,我们设weight和data的大小如下:
(1)每层weight得大小都是512MB, 一共是1GB (fp32下)
(2)输入的data大小为256MB(fp32下)
(3)第一层输出output1,64MB(fp16下)
(4)第二层输出output2, 128MB(fp16下)
(2)Active Memory Timeline
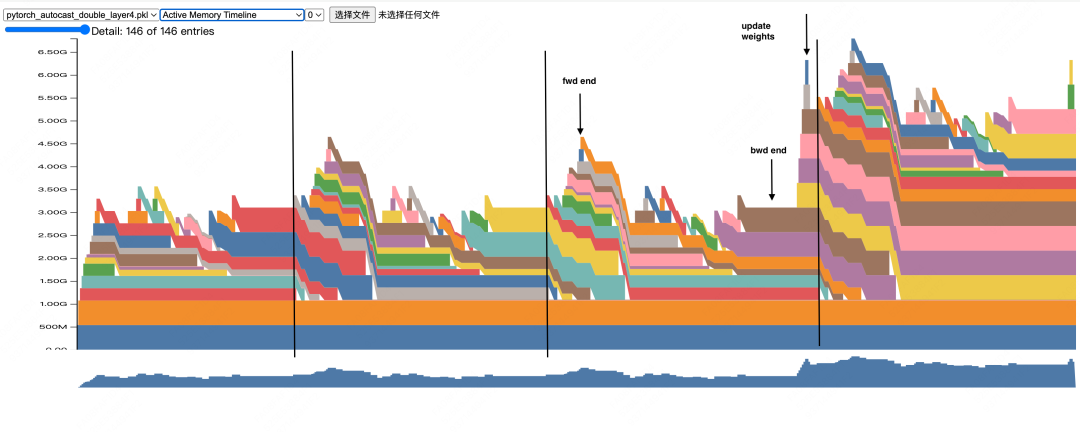
-
可以发现,在这次的训练中,直到step3结尾,梯度才没有出现nan/inf,因此可以做adam动量的初始化和更新。
-
数据占用的显存逐层累加,直到fwd结尾达到一个峰值
-
bwd的过程中,随着激活值的使用完毕后的释放,显存也呈下降趋势
-
权重更新过程中会出现一个新的峰值(细长的小竖条),这是在adam for each更新方式下会产生的临时额外显存(大小和fp32权重一致),这种方式可以减少算子调用,但缺点就是增加显存消耗。感兴趣的朋友可以自行搜索这块内容
-
从step4开始,整个训练过程的显存消耗模式就趋于稳定了,因此如果你想查看代码平稳运行期的显存消耗,你可以先做几个step的预热,然后再对后面的step记录snapshot。
更多的细节,不在这里赘述了,读者可以采用我之前说的方法,类比于2.1(2)中的文字说明,罗列出这个双层模型训练的整个细节(PS:不是重复工作哦,在罗列的过程中也可以发现一些新东西,比如fp32 grad_weight生成的时机,激活值的释放时机等等,大家试试~)
三、zero1
最后,我曾写过一个2卡toy example,描述了zero1训练中的显存消耗(以下snapshot来自rank1)
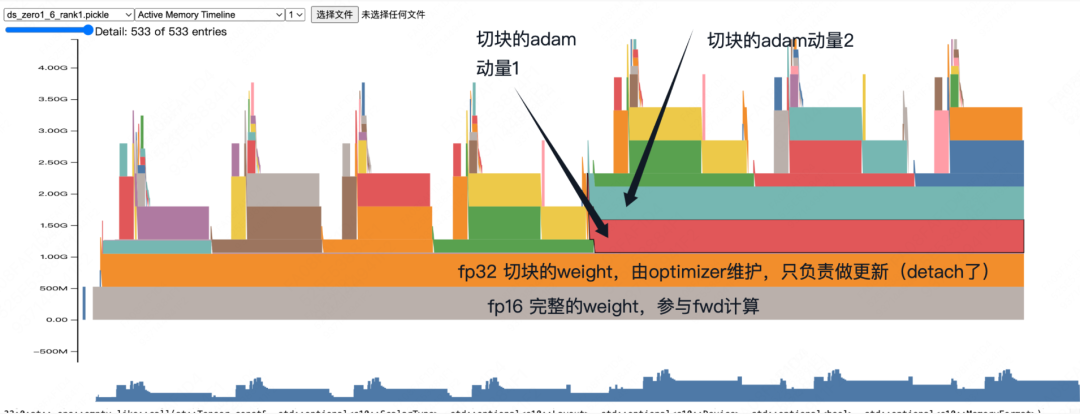
通过堆栈信息,有针对性地复查源码,我们可以大致罗列出整个过程:
(1)完整的模型大小是1000MB(fp32精度下)
(2)fp16:zero会开辟500MB显存,存放完整的fp16模型(每张卡上都有完整的fp16)
(3)fp32:fp32 = partiton_fp16.copy().float().detach(),即fp16模型切块,转fp32,放在optimizer中,占据500MB显存
(4)每次【成功】梯度更新后,单卡上fp16._copy(fp32),再做all-gather。
因为是原位copy,不需要分配新显存,所以你会看到那个灰色显存块从头到尾都在。
我们从中也会发现一些有趣的事情,比如在amp中,fp16的权重是临时分配,用完即废的,但是zero1中它会始终以一个大的、flatten形式的张量存放在显存上。由于使用了分布式通信,我们还可以在其中发现相关的显存分配等等。通过自己写toy代码的形式,了解分布式框架对显存的优化,进而有针对性地找到代码中的关键实践,也是一种快速掌握代码的好方法。
(文:GiantPandaCV)