


本文由匹兹堡大学智能系统实验室(Intelligent Systems Laboratory)的研究团队完成。第一作者为匹兹堡大学的一年级博士生薛琪耀。
当前文本生成视频(T2V)技术正在从注重视觉质量与模型规模的扩展阶段,迈向更关注物理一致性与现实合理性的推理驱动阶段。
物理规律作为建模现实世界的基本知识体系,是实现高质量视频生成的关键约束。提升大模型对现实物理动态的理解与遵循能力,成为推动 T2V 技术落地的重要突破方向。
为推动物理一致性驱动的 T2V 生成研究,来自匹兹堡大学的研究团队提出了 PhyT2V 框架,并在最新论文中系统阐述了该方法的核心机制,该论文已被 CVPR 2025 接收。

-
论文标题:PhyT2V: LLM-Guided Iterative Self-Refinement for Physics-Grounded Text-to-Video Generation
-
论文地址:https://arxiv.org/abs/2412.00596
该方法不依赖模型重训练或大规模外部数据,而是通过引入大型语言模型引导的链式推理与迭代自我修正机制,对文本提示进行多轮物理一致性分析与优化,从而有效增强主流 T2V 模型在现实物理场景中的泛化与生成能力。
此框架可以被广泛地应用到任何已有的 T2V 模型上,而且不需要用户任何的手动干预就可以实现完全自动化的 T2V 增强,因此拥有极低的落地门槛和非常好的泛化性,在实际应用中有非常广阔的应用前景。

近年来,文本到视频(Text-to-Video,T2V)生成技术取得了显著进展,出现了基于 Transformer 扩散模型的 Sora、Pika 和 CogVideoX 等模型。这些模型能够生成复杂且逼真的场景。
然而,尽管单帧视频质量很高,当前的 T2V 模型在遵守现实世界常识和物理规则方面存在显著不足。例如,它们可能无法正确处理物体的数量、材质特性、流体动力学、重力、运动、碰撞和因果关系。

现有让 T2V 模型生成内容更符合物理规则的方法主要存在以下局限性,尤其是在处理训练数据未涵盖的分布外(out-of-distribution,OOD)场景时:
-
数据驱动方法局限:大多数现有方法是数据驱动的,依赖于大规模多模态 T2V 数据集来训练扩散模型。然而,这高度依赖于数据集的数量、质量和多样性。由于物理规则并未在训练过程中被显式嵌入,这些方法在训练数据未覆盖的分布外领域泛化能力受限,视频生成质量会大幅下降。真实世界场景的巨大多样性进一步限制了这些模型的通用性。
-
注入物理知识方法的局限:也有研究尝试使用现有的 3D 引擎(如 Blender、Unity3D、Unreal)或数学模型将物理知识注入到 T2V 模型中。但这些方法通常受限于固定的物理类别和模式,如预定义的物体和运动,同样缺乏通用性。
-
现有提示增强方法的局限:虽然有研究表明通过细化提示可以改善分布外提示下的视频生成质量,但现有许多提示增强方法仅仅是基于主观经验简单地增强或修改提示,而缺乏一个有效的反馈机制来判断生成的视频在多大程度上偏离了现实世界知识和物理规则,以及当前的提示增强是否有效提升了视频的物理真实度。
-
额外输入方法的局限:一些方法尝试通过提供额外输入模态为 T2V 模型提供反馈。但这会引入大量的额外计算开销并且缺乏通用性。
为了实现可泛化的物理真实的 T2V 生成,匹兹堡大学的研究人员提出了 PhyT2V。
PhyT2V 不通过扩展数据集或复杂化模型架构,而是通过将现实世界知识和物理规则嵌入到文本提示中,提供足够的上下文,从而将现有 T2V 模型的生成能力扩展到分布外领域。
为了避免模糊不清的提示工程,PhyT2V 的核心思想是在 T2V 提示过程中启用思维链(Chain-of-Thought,CoT)和回溯推理(step-back reasoning)。通过应用分步指导和迭代自修正,确保 T2V 模型遵循正确的物理动态和帧间一致性。
其核心贡献在于:无需任何额外训练或模型结构更改,而是仅仅通过结合 LLM 的推理与回溯能力,进行逐轮提示修正,从而显著提升现有 T2V 模型在物理一致性任务中的性能。该方法可泛化适用于不同架构和训练背景的 T2V 模型,尤其在分布外提示下展现出强大的增强效果。
方法介绍
PhyT2V 利用经过良好训练的大型语言模型(LLM),例如 ChatGPT-4o,来促进 CoT 和回溯推理。这种推理以迭代方式进行,每一轮都自主修正 T2V 提示和生成的视频,包含三个步骤:
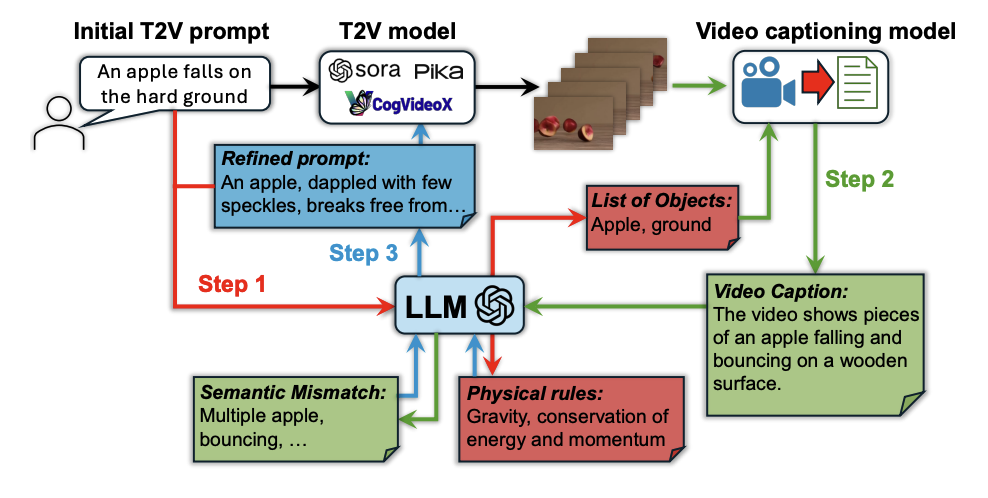
步骤 1:识别物理规则和主要对象
LLM 分析用户提示,通过「上下文学习」提取视频中应显示的对象和应遵循的物理规则。这一步的提示会给出详细的任务说明和少量示例。LLM 的输出描述物理规则但不提供公式。消融研究表明此步骤是必要的。
步骤 2:识别提示与视频之间的语义不匹配
首先,使用视频字幕模型(例如 Tarsier)将生成的视频的语义内容转换为文本。然后,LLM 使用 CoT 推理评估视频字幕与当前 T2V 提示之间的不匹配之处。使用视频字幕是因为 CoT 方法更适合处理单模态数据,它强调线性分解和分步推理。通过将视频内容转化为文本,可以在文本域中进行 CoT 和回溯推理。消融研究证实此步骤对于识别和纠正视频中与期望不符的细节至关重要。
步骤 3:生成修正后的提示
LLM 通过结合步骤 1 总结的物理规则和解决步骤 2 得出的不匹配之处,使用回溯提示来修正当前的 T2V 提示。回溯推理有助于从更高层次的抽象中导出问题。这一步骤的提示结构也包含任务说明、示例和当前任务信息。此外,还会提供上一轮提示修正效果的量化反馈(例如,使用 VideoCon-Physics 评估器的得分),指导 LLM 采取不同的推理路径。修正后的 T2V 提示将作为新的用户提示再次用于 T2V 模型生成视频,开始新一轮的修正。这种迭代修正会持续进行,直到生成的视频质量令人满意或视频质量的改进收敛。整个过程通常需要几轮,大多数改进发生在最初两轮,3-4 轮通常足够。
PhyT2V 的优势
与现有提示增强方法相比,PhyT2V 的关键贡献在于分析当前生成的视频与提示之间的语义不匹配,并基于不匹配与相关的物理知识进行修正,而之前的许多方法只是简单地增强或修改提示。PhyT2V 的主要优势包括:
-
无需训练、即插即用:无需修改任何 T2V 模型结构,也不需额外训练数据,即可直接增强不同 T2V 模型的物理一致性。
-
提示修正具备反馈闭环:不只是修改提示文本,而是基于真实生成结果的语义偏差反馈,进行有针对性的优化。
-
跨领域通用性强:在多个物理场景(固体、流体、重力、运动等)尤其是分布外场景下表现优异,具备广泛适配性。
实验
研究人员在多个基于 Diffusion Transformer 的开源 T2V 模型上应用了 PhyT2V,包括 CogVideoX 2B & 5B、OpenSora 和 VideoCrafter。
评估使用了 VideoPhy 和 PhyGenBench 这两个强调物理定律和遵守度的提示基准数据集,使用 VideoCon-Physics 评估器衡量生成的视频对物理常识(PC)和语义遵守度(SA)的遵守情况,并在 VBench 评测基准上也取得了领先的表现。
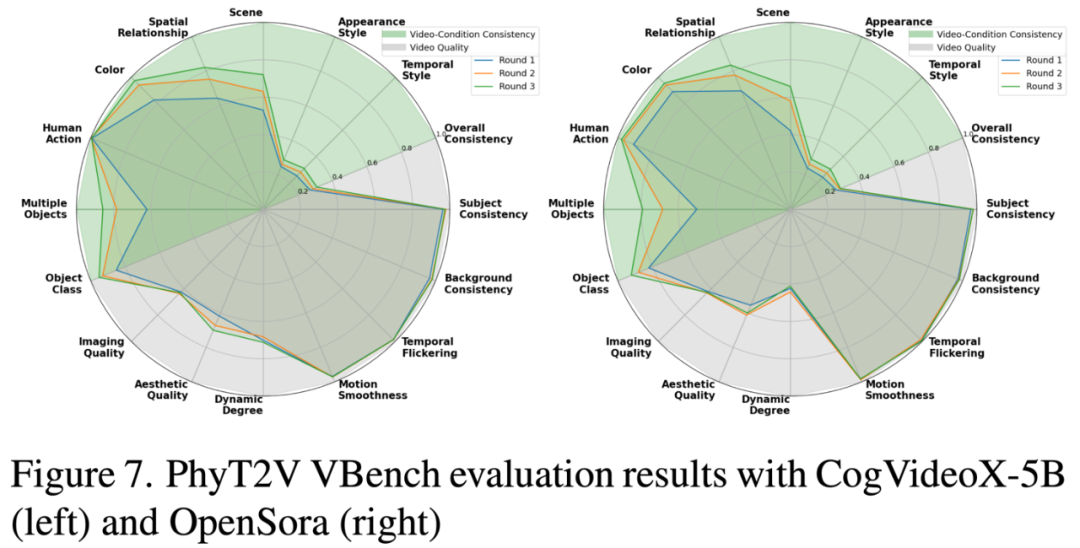


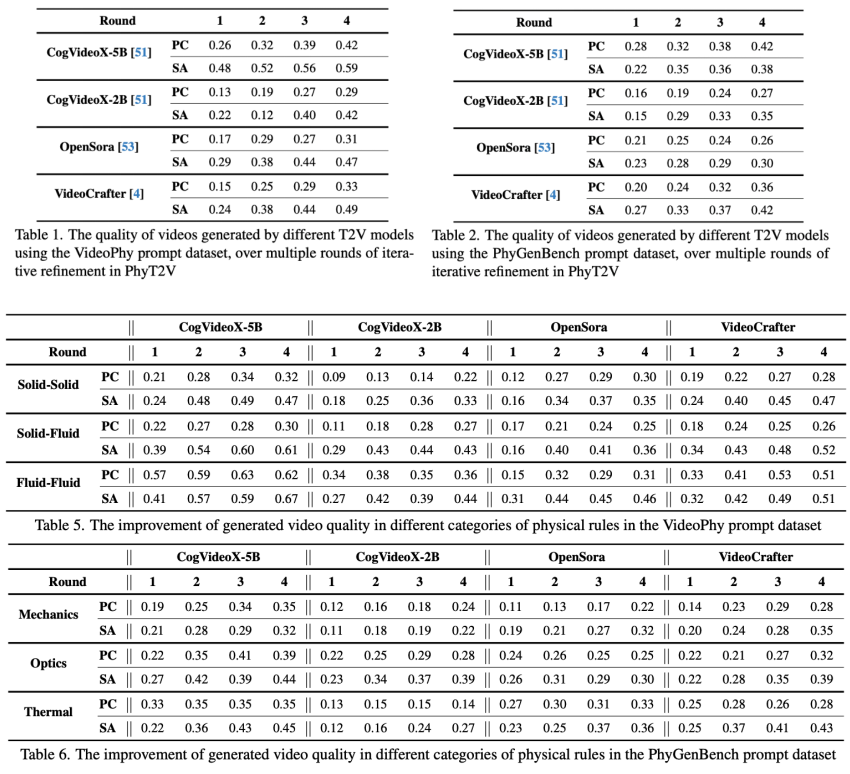
实验结果表明,PhyT2V 显著提高了生成的视频对文本提示本身以及现实世界物理规则的遵守程度。
这种改进在 CogVideoX-5B 模型上最为显著,PC 提高可达 2.2 倍,SA 提高可达 2.3 倍。在其他模型上也有显著提升。迭代修正过程收敛速度快,通常 3-4 轮足够。
PhyT2V 大幅领先于直接使用 ChatGPT 4 或 Promptist 等现有提示增强方法至少 35%。消融研究证实了步骤 1(物理规则推理)和步骤 2(不匹配推理)在 PhyT2V 工作流程中的必要性。模型尺寸也会影响 PhyT2V 的表现,在较大的模型上 PhyT2V 性能更好。


总结
总而言之,PhyT2V 是一种新颖的、数据独立的 T2V 生成框架。通过结合 CoT 推理和回溯提示,PhyT2V 系统地修正 T2V 提示,以确保生成的视频遵守现实世界物理原理,而无需额外的模型重新训练或依赖额外条件。这项工作为构建更理解物理世界、能生成更逼真视频的 T2V 模型迈出了重要一步。

©
(文:机器之心)