


当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。
我们认为,要真正提升 GUI 智能体的能力,关键在于从「反应式」迈向「深思熟虑的推理者」(Deliberative Reasoners)。为此,浙江大学联合香港理工大学等机构的研究者们提出了 InfiGUI-R1,一个基于其创新的 Actor2Reasoner 框架训练的 GUI 智能体,旨在让 AI 像人一样在行动前思考,行动后反思。

-
论文标题:InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
-
论文链接:https://arxiv.org/abs/2504.14239
-
项目仓库:https://github.com/Reallm-Labs/InfiGUI-R1
-
模型地址:https://huggingface.co/Reallm-Labs/InfiGUI-R1-3B
从「反应行动」到「深思熟虑」:GUI 智能体面临的挑战
想象一下,你让 AI Agent 帮你完成一个多步骤的手机操作,比如「预订明天下午去北京的高铁票」。一个简单的「反应行动」式 Agent 可能会按顺序点击它认为相关的按钮,但一旦遇到预期外的界面(如弹窗广告、加载失败),就容易卡壳或出错,因为它缺乏「规划」和「反思」的能力。
为了让 GUI 智能体更可靠、更智能地完成复杂任务,它们需要具备深思熟虑的推理能力。这意味着智能体的行为模式需要从简单的「感知 → 行动」转变为更高级的「感知 → 推理 → 行动」模式。这种模式要求智能体不仅能看懂界面,还要能:
-
理解任务意图:将高层指令分解为具体的执行步骤 -
进行空间推理:准确理解界面元素的布局和关系,定位目标 -
反思与纠错:识别并从错误中恢复,调整策略
Actor2Reasoner 框架:两步走,打造深思熟虑的推理者
为了实现这一目标,研究团队提出了 Actor2Reasoner 框架,一个以推理为核心的两阶段训练方法,旨在逐步将 GUI 智能体从「反应式行动者」培养成「深思熟虑的推理者」。
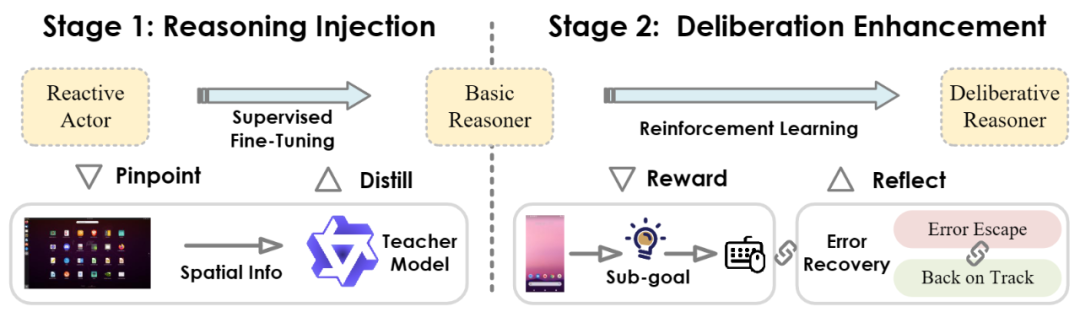
图:Actor2Reasoner 框架概览
第一阶段:推理注入(Reasoning Injection)—— 打下推理基础
此阶段的核心目标是完成从「行动者」到「基础推理者」的关键转变。研究者们采用了空间推理蒸馏(Spatial Reasoning Distillation)技术。他们首先识别出模型在哪些交互步骤中容易因缺乏推理而出错(称之为「推理瓶颈样本」),然后利用能力更强的「教师模型」生成带有明确空间推理步骤的高质量执行轨迹。
通过在这些包含显式推理过程的数据上进行监督微调(SFT),引导基础模型学习在生成动作前,先进行必要的逻辑思考,特别是整合 GUI 视觉空间信息的思考。这一步打破了「感知 → 行动」的直接链路,建立了「感知 → 推理 → 行动」的基础模式。
第二阶段:深思熟虑增强(Deliberation Enhancement)—— 迈向高级推理
在第一阶段的基础上,此阶段利用强化学习(RL)进一步提升模型的「深思熟虑」能力,重点打磨规划和反思两大核心能力。研究者们创新性地引入了两种方法:
-
目标引导:为了增强智能体「向前看」的规划和任务分解能力,研究者们设计了奖励机制,鼓励模型在其推理过程中生成明确且准确的中间子目标。通过评估生成的子目标与真实子目标的对齐程度,为模型的规划能力提供有效的学习信号。
-
错误回溯:为了培养智能体「向后看」的反思和自我纠错能力,研究者们在 RL 训练中有针对性地构建了模拟错误状态或需要从错误中恢复的场景。例如,让模型学习在执行了错误动作后如何使用「返回」等操作进行「逃逸」,以及如何在「回到正轨」后重新评估并执行正确的动作。这种针对性的训练显著增强了模型的鲁棒性和适应性。
InfiGUI-R1-3B:小参数,大能量
基于 Actor2Reasoner 框架,研究团队训练出了 InfiGUI-R1-3B 模型(基于 Qwen2.5-VL-3B-Instruct)。尽管只有 30 亿参数,InfiGUI-R1-3B 在多个关键基准测试中展现出了卓越的性能:
-
在跨平台(移动、桌面、网页)的 ScreenSpot 基准上,平均准确率达到 87.5%,在移动、桌面、Web 平台的文本和图标定位任务上全面领先,达到同等参数量模型中 SOTA 水平。
-
在更具挑战性、面向复杂高分屏桌面应用的 ScreenSpot-Pro 基准上,平均准确率达到 35.7%,性能比肩参数量更大且表现优异的 7B 模型(如 UI-TARS-7B),证明了其在复杂专业软件(例如 CAD、Office)界面上的指令定位准确性。
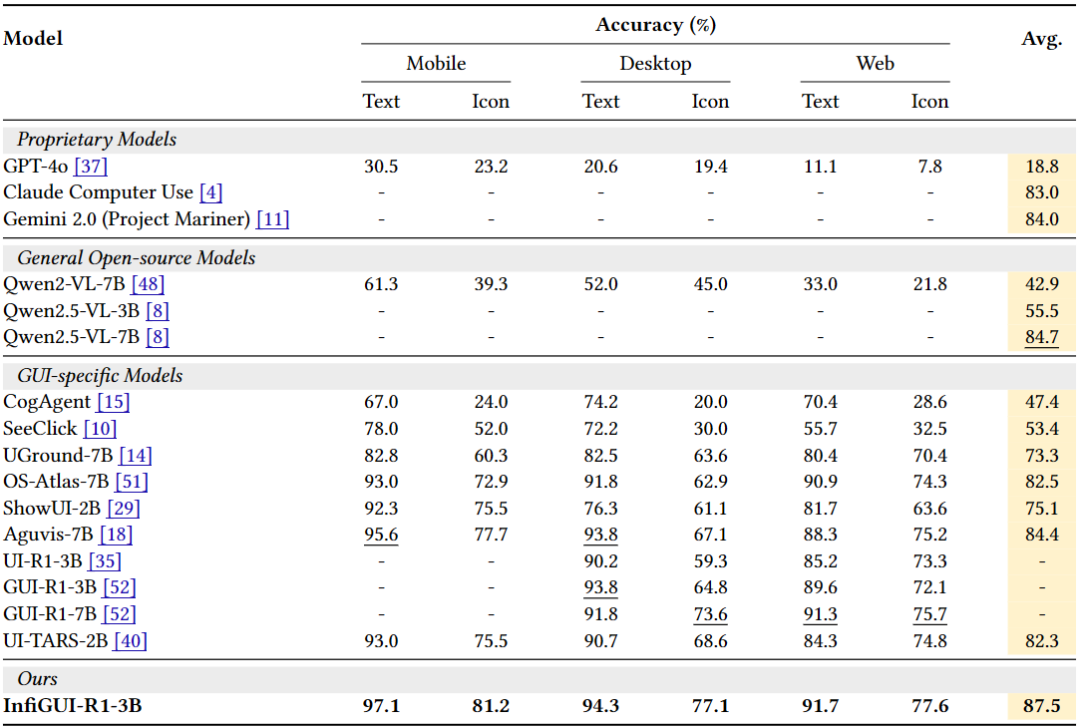
表:ScreenSpot 性能对比
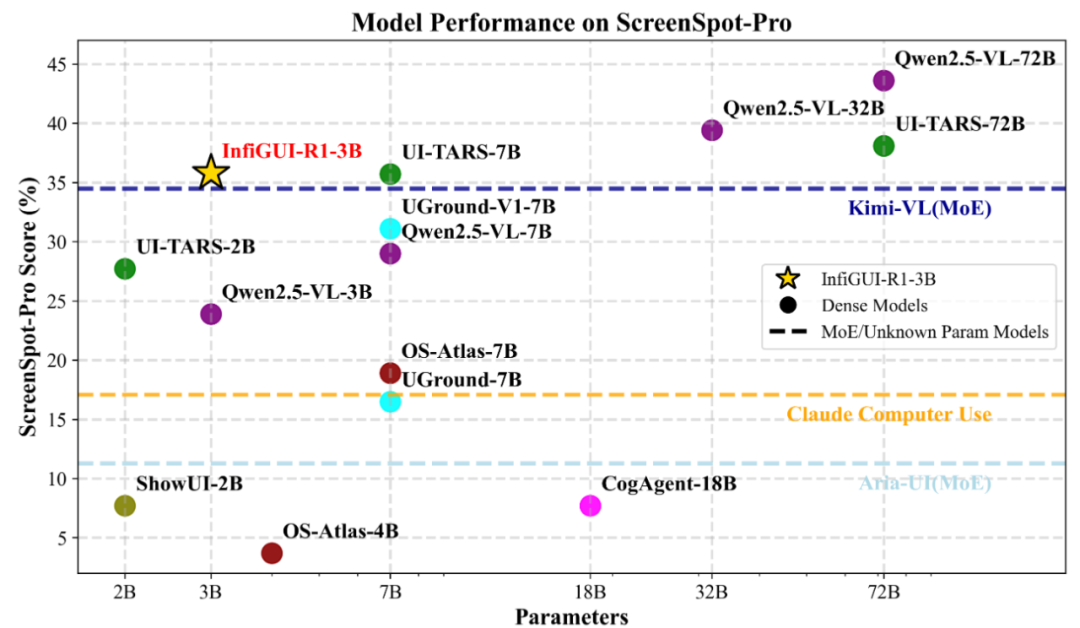
图:ScreenSpot-Pro 性能对比
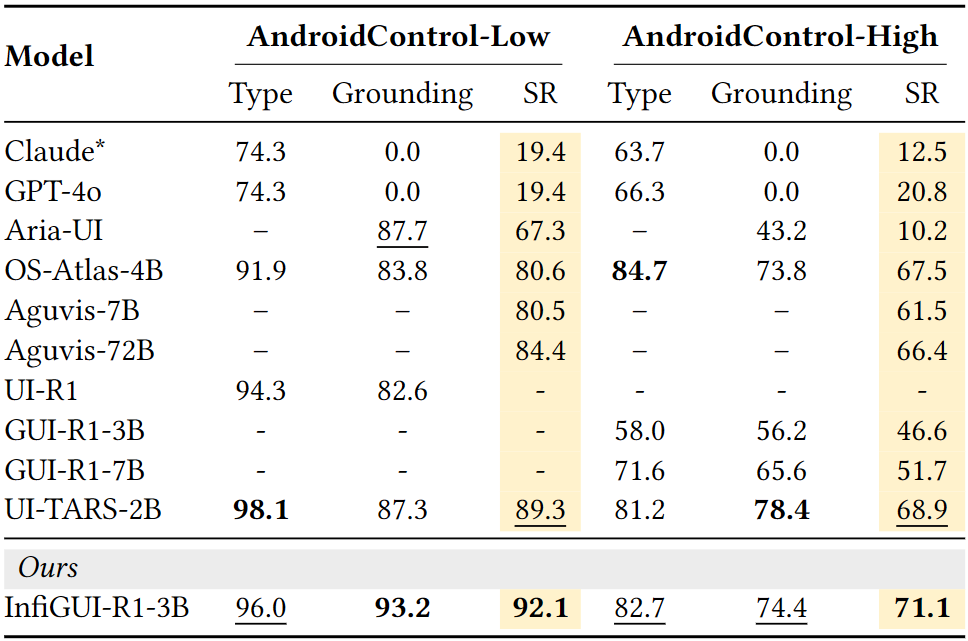
表:AndroidControl 性能对比
这些结果充分证明了 Actor2Reasoner 框架的有效性。通过系统性地注入和增强推理能力,特别是规划和反思能力,InfiGUI-R1-3B 以相对较小的模型规模,在 GUI 理解和复杂任务执行方面取得了领先或极具竞争力的表现。
结语
InfiGUI-R1 和 Actor2Reasoner 框架的提出,为开发更智能、更可靠的 GUI 自动化工具开辟了新的道路。它证明了通过精心设计的训练方法,即使是小规模的多模态模型,也能被赋予强大的规划、推理和反思能力,从而更好地理解和操作我们日常使用的图形界面,向着真正「能思考、会纠错」的 AI 助手迈出了坚实的一步。
©
(文:机器之心)