

🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
怎么用?
在线体验: Qwen Chat 网页版 (https://chat.qwen.ai ) 和 APP 已经能直接试用。模型下载: Hugging Face, ModelScope 等平台已提供模型权重下载 (包括预训练和后训练版本)。部署框架推荐: SGLang, vLLM。本地运行工具推荐: Ollama, LMStudio, MLX, llama.cpp, KTransformers。

Benchmark 成绩单
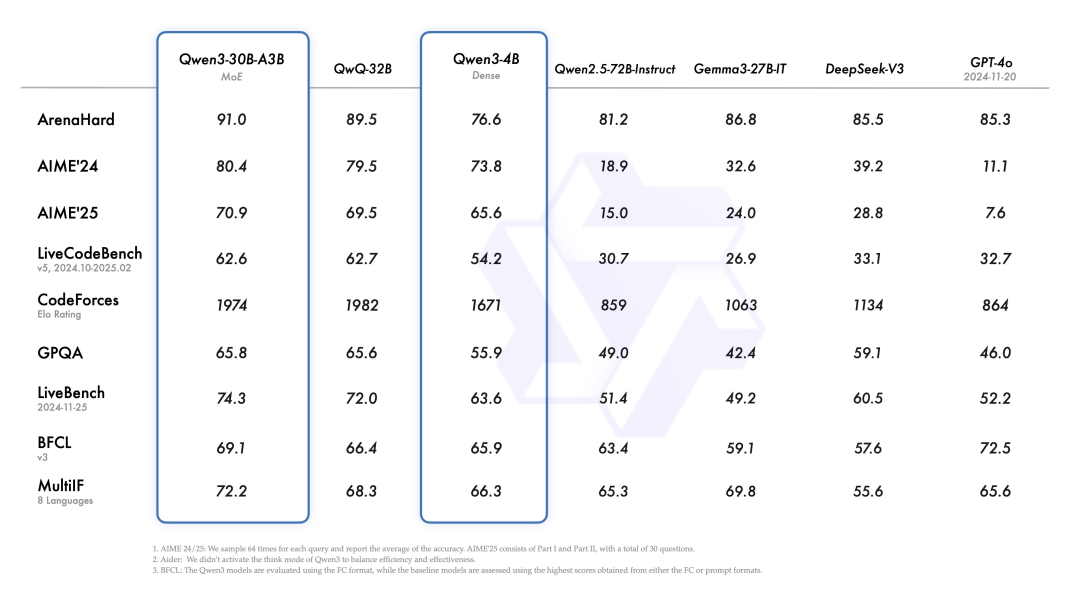
Qwen3-30B-A3B (MoE) vsQwQ-32B (老 MoE) : 新 MoE 全面小胜,尤其在 ArenaHard、AIME、GPQA、LiveBench、BFCL、MultiIF 这些项目上更明显。长江后浪推前浪。Qwen3-4B (Dense) vsQwen2.5-72B-Instruct (老 72B) : 4B 小钢炮有点猛,在 AIME、LiveBench、BFCL 这些地方甚至能跟老大哥 72B 打得有来有回,甚至反超。越级打怪了属于是。Qwen3-30B-A3B (MoE) vs竞品 (Gemma3, DeepSeek V3, GPT-4o) : 新 30B MoE 对比这些对手,在 AIME、CodeForces、GPQA、LiveBench、MultiIF 上都不虚,甚至小优。
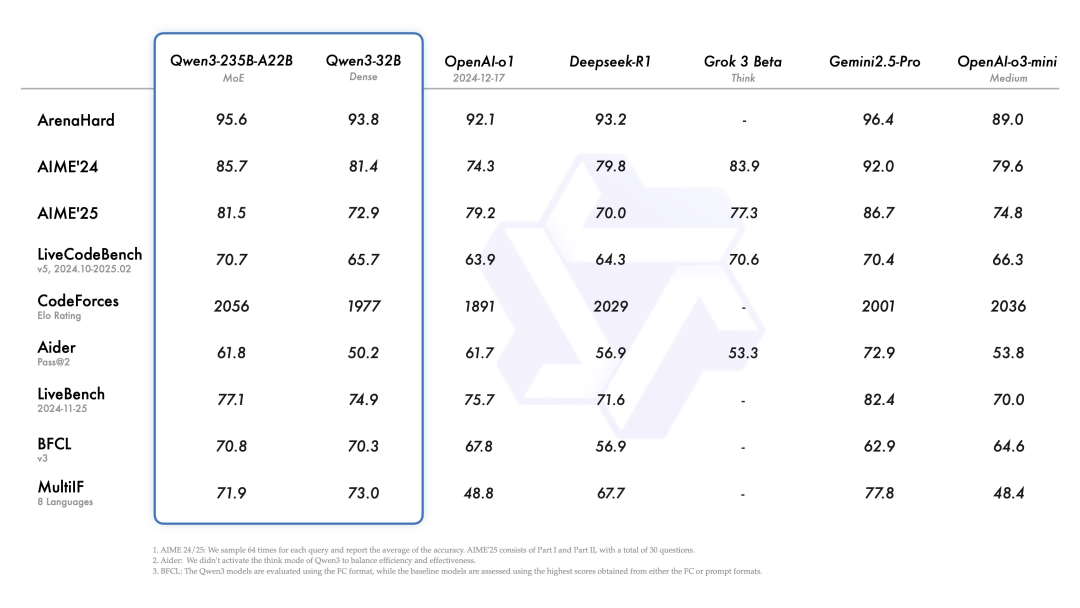
Qwen3-235B-A22B (旗舰 MoE) vs顶级选手 (Gemini 2.5 Pro, o1, DeepSeek-R1) : 旗舰 MoE 硬碰硬,跟 Gemini 2.5 Pro 在多个项目上打得难分难解 (AIME, CodeForces, LiveBench, BFCL),基本不落下风。对 o1 和 DeepSeek-R1 则优势比较明显。实力够顶。Qwen3-32B (Dense) vs竞品 (o1, DeepSeek-R1, o3-mini) : 32B Dense 也挺能打,跟 DeepSeek-R1、o3-mini 比,各有胜负,实力不俗。
可伸缩推理预算 (Scalable Reasoning Budget): 性能提升跟计算推理预算直接挂钩。用户可以根据任务需求,灵活配置预算,平衡成本和效果。 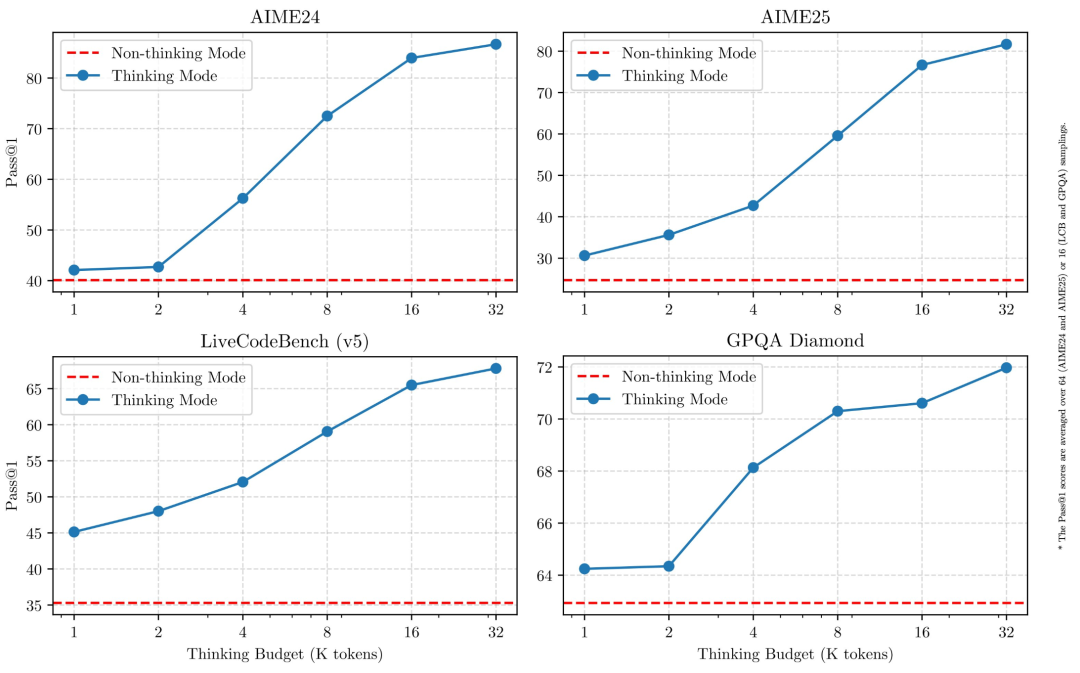
支持 119 种语言和方言,国际化拉满。 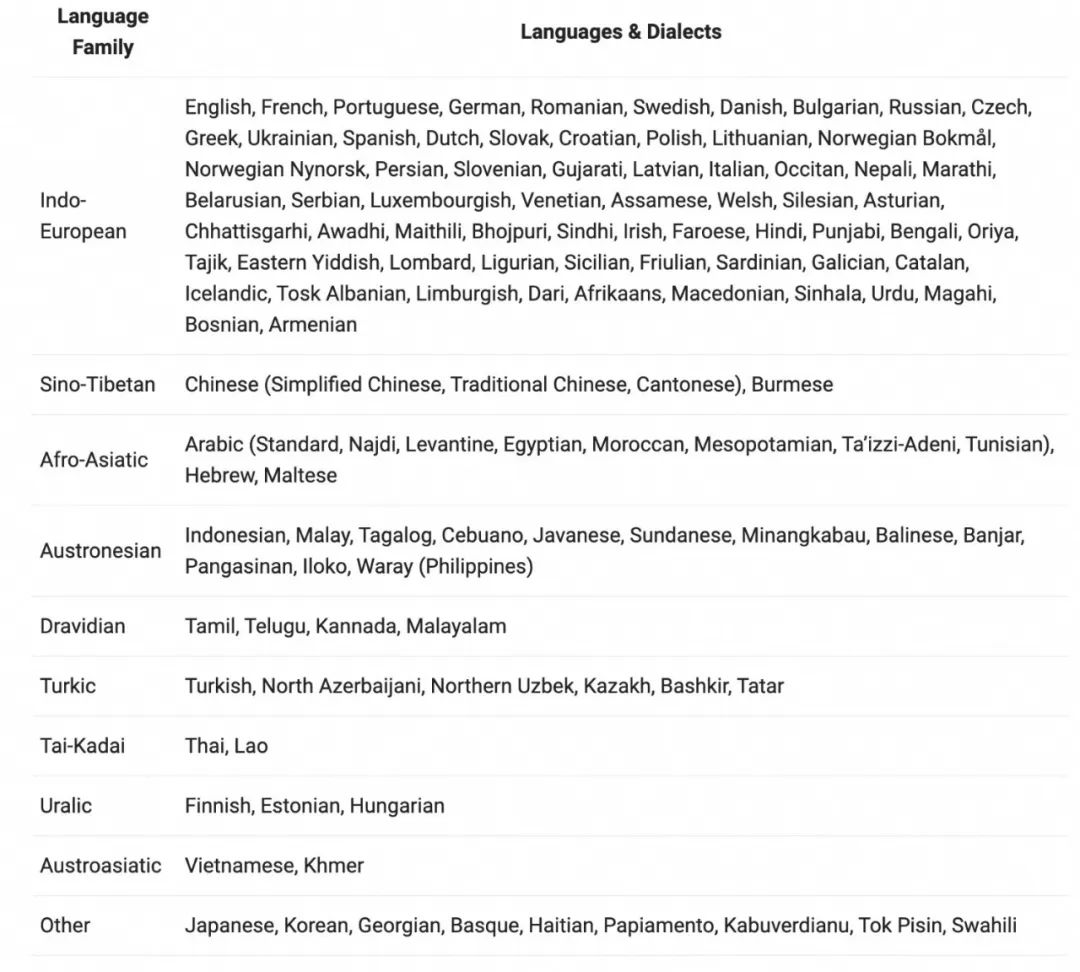
Coding & Agent 能力优化: 特别加强了编码和 Agent 能力,还强化了对 MCP (模型上下文协议) 的支持。官方给出了 Qwen3 如何思考并与环境交互的例子。
Qwen3 代码能力实测:结论——可以加显卡了,本地最强开源编码模型。
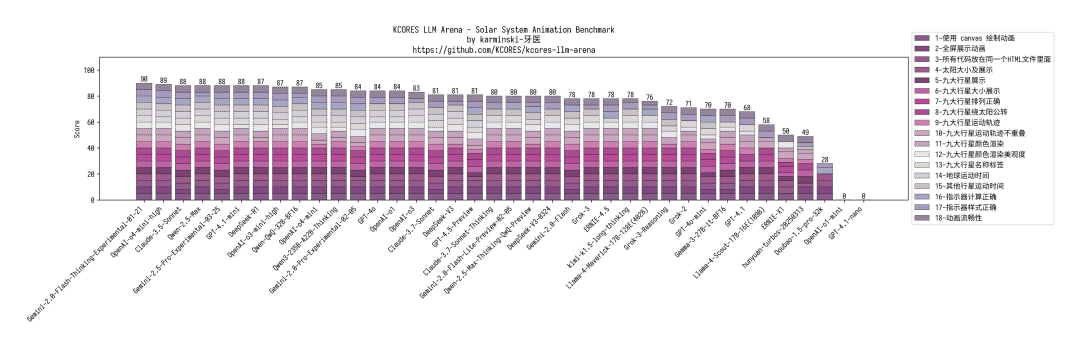
20 小球七边形 :小球会掉出来,摩擦力 casi 没有,但整体还行。得分 71,跟 Gemini-2.0-Flash 差不多。
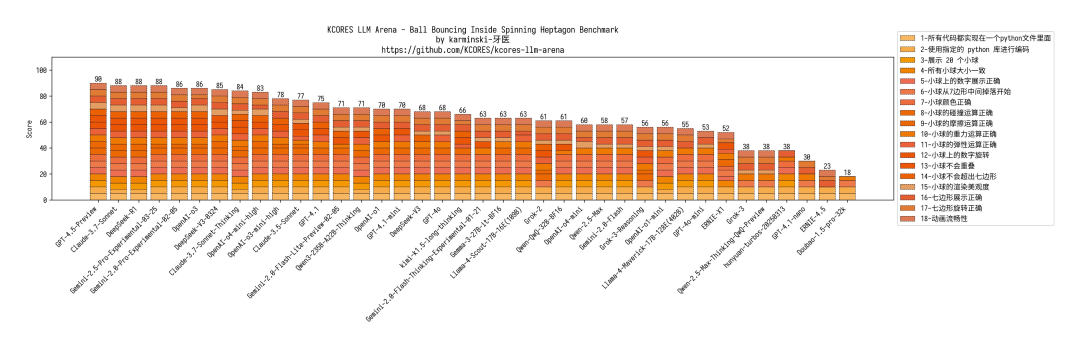
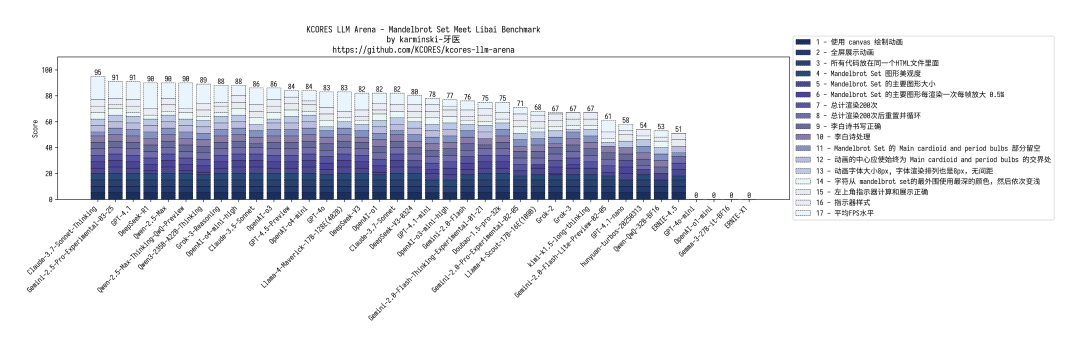
Mandelbrot 分形 :渲染范围太大,颜色搞反了。但渲染性能和准确度都不错。得分 89,追平自家 Qwen2.5-Max。

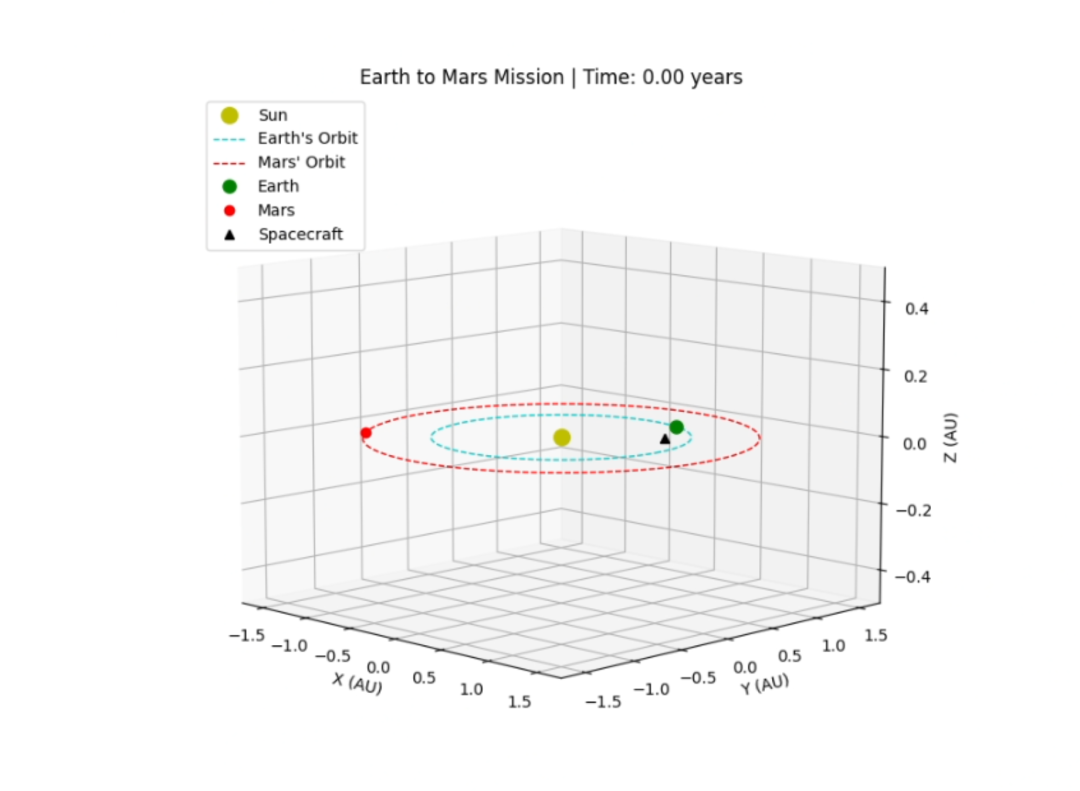
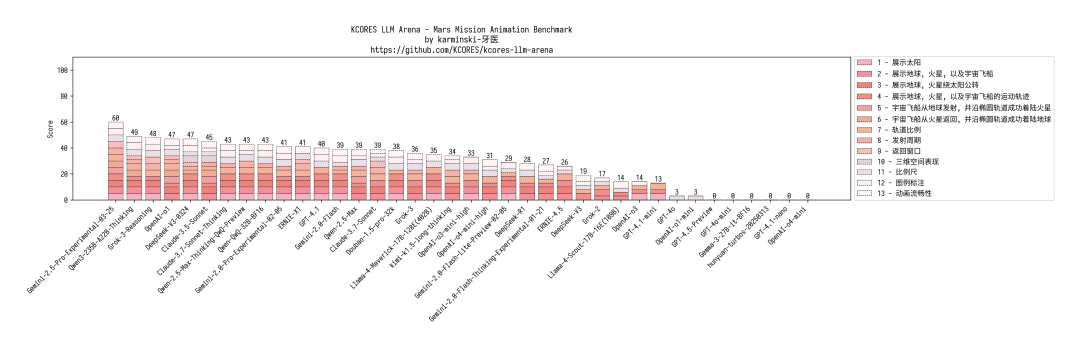
火星任务 :表现很顶!知道往返都要窗口期 (很多模型都不知道),误差不大。得分 49,仅次于 Gemini-2.5-Pro。
太阳系模拟 :效果平平无奇,没土星环,没特效。但胜在没犯大错。得分 85,和 OpenAI-o4-mini 一档。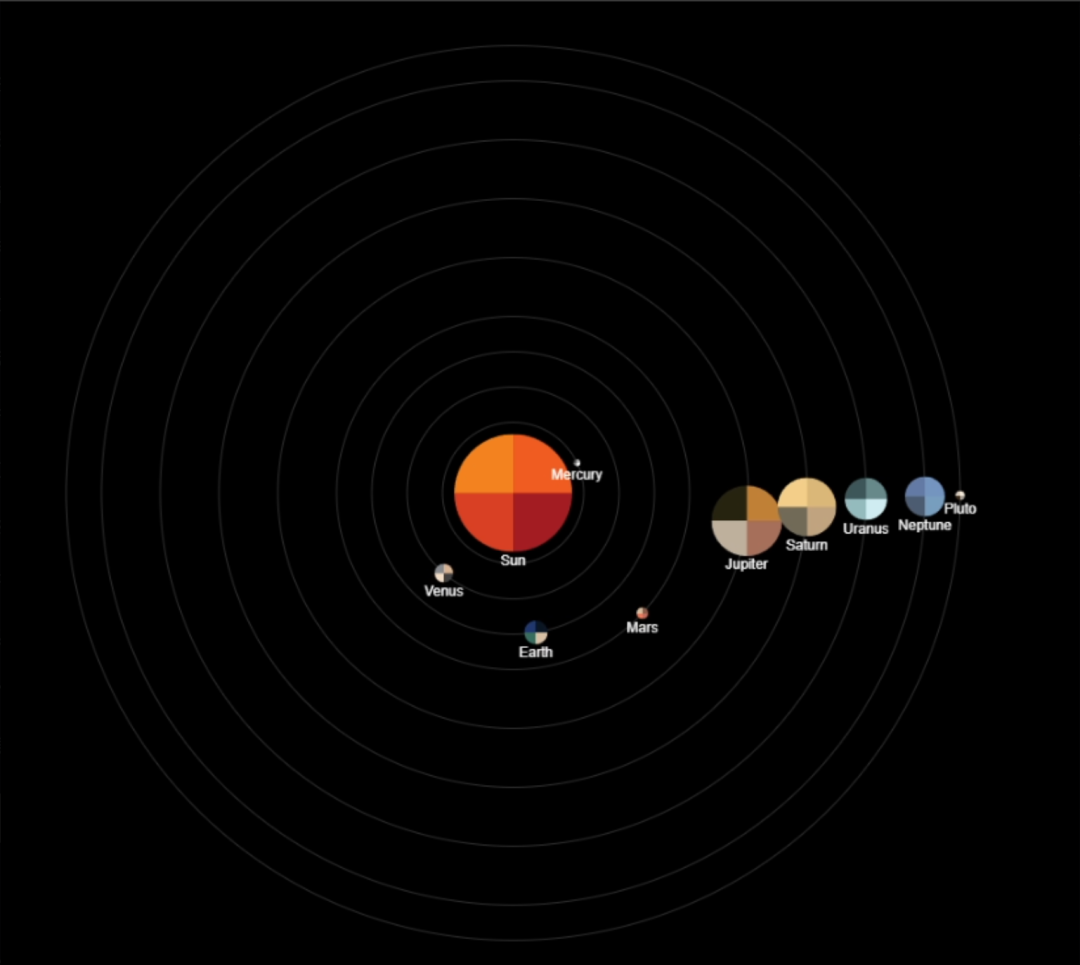


235B 大模型本地跑?苹果 M2 Ultra + MLX,Qwen3 跑出 28 toks/秒。

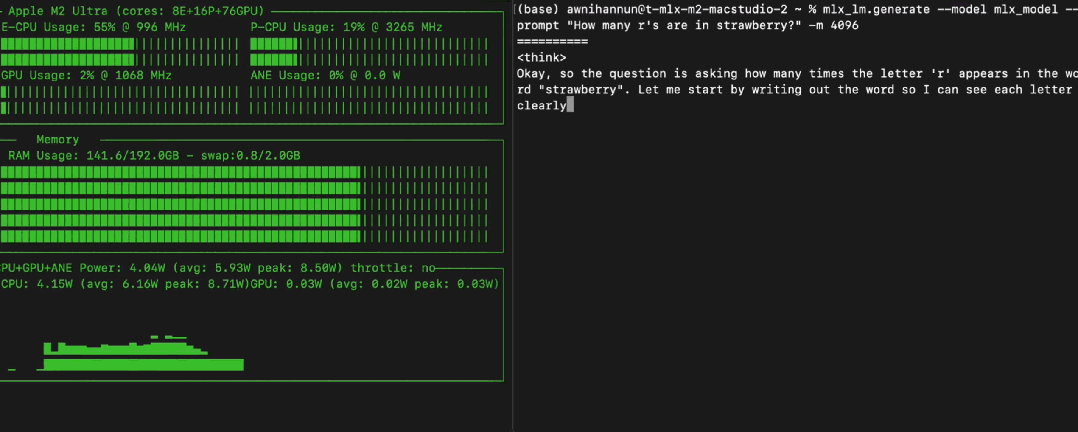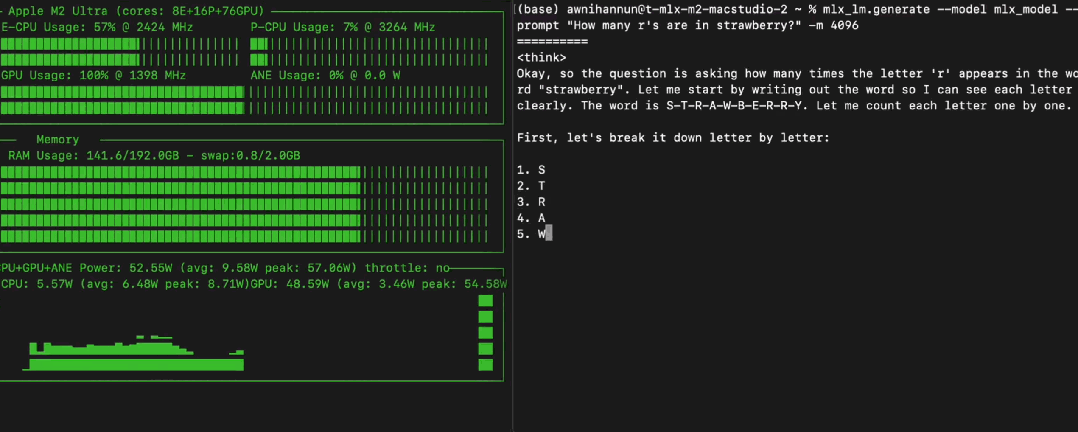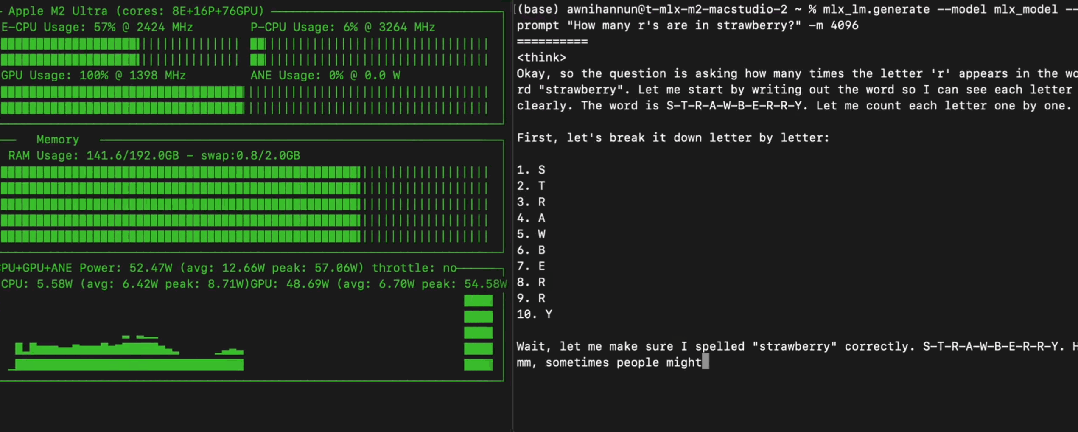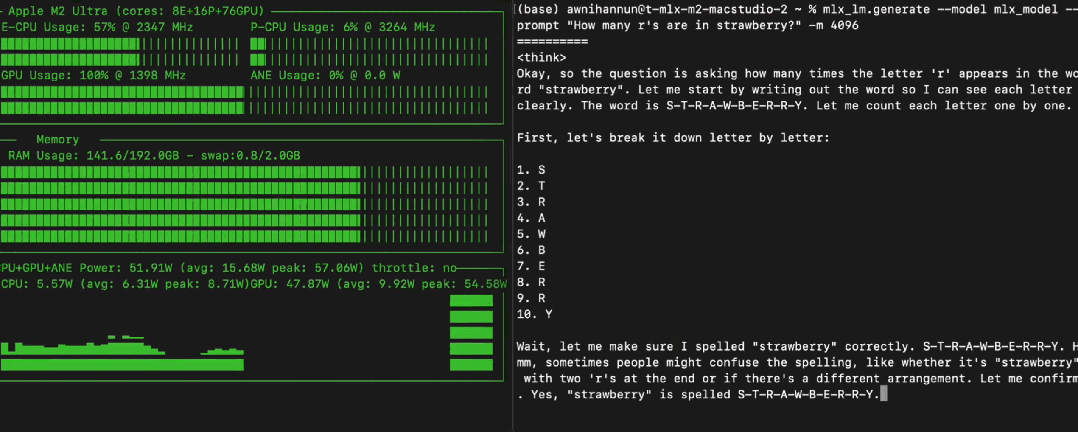
有人惊叹:“这只是一台 M2 Ultra?” (是的!) 直呼:“Mac 要成推理神器了。”

[1] https://x.com/Alibaba_Qwen/status/1916962087676612998
点这里👇关注我,记得标星哦~
(文:AI进修生)