


检索增强生成(RAG)为大语言模型(LLMs)提供高质量的外部知识库和高效的检索器,作为提升语言模型事实准确性的RAG方法大多聚焦于检索 + 文本生成的模式,对图像等非文本模态的输出能力支持有限。为了解决这一领域空缺,北京大学与华为云的联合研究团队上提出了一个全新的评测基准——MRAMG-Bench,旨在推动RAG迈向 Multimodal Retrieval-Augmented Multimodal Generation(MRAMG)。MRAMG-Bench包含六个精心设计的英文数据集,涵盖4,346篇文档、14,190张图像和4,800个QA对,数据来自网页、学术和生活等三个领域,跨越七个不同的数据源,引入分级难度和图片顺序推理,能够有效模拟用户在现实交互场景中面临的复杂认知挑战。该研究成果已被 SIGIR 2025 录用。
![]()
单位 | 北大,华为云
论文标题 | MRAMG-Bench: A Comprehensive Benchmark for Advancing Multimodal Retrieval-Augmented Multimodal Generation
论文地址 | https://arxiv.org/pdf/2502.04176
数据地址 | https://huggingface.co/MRAMG
Github 地址 | https://github.com/MRAMG-Bench/MRAMG
研究背景与动机
传统的RAG方法主要关注检索文本知识,限制了它们利用多模态信息(如图像和表格)的能力。随着多模态大模型(MLLMs)的发展,多模态检索增强生成(MRAG)应运而生,其在传统RAG的技术基础上,通过进一步结合文本和其他模态信息,有效提升了生成的文本回答的质量。然而,尽管检索过程已经结合了多模态信息,现有的MRAG方法主要关注多模态输入和基于文本的输出。实际上,LLM部署中的一种新兴趋势是生成多模态输出,即同时生成文本和图像。用户在许多场景中更倾向于看到图像而非仅仅是文字,尤其是在一些关键情境中,如图1所示。
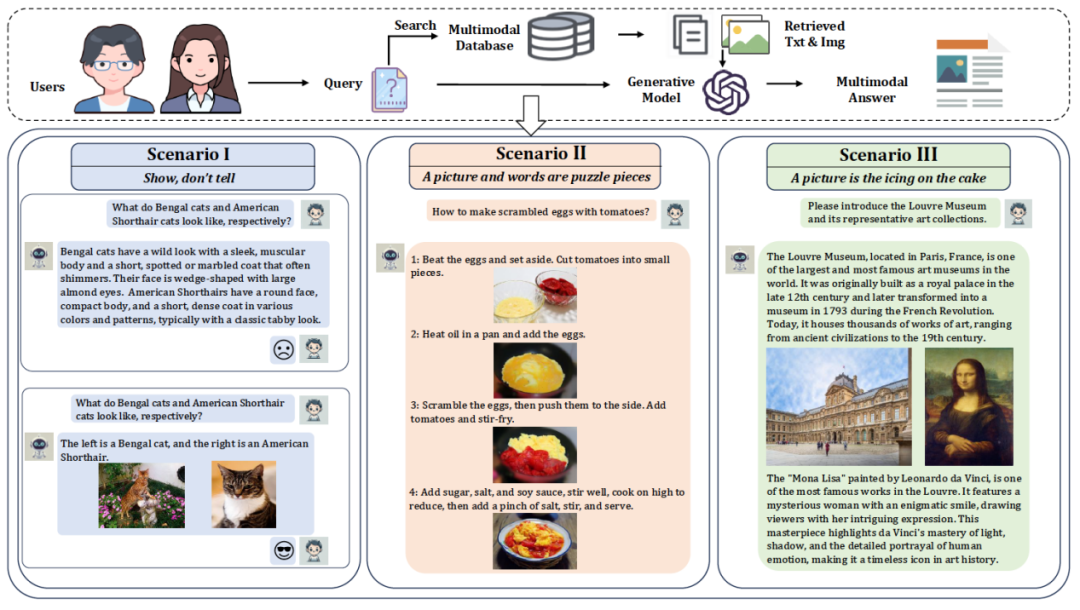
图1: MRAMG任务的示意图(上方),且展示了如何通过结合文本和图像来增强清晰度和理解力的情境(下方)。
图文结合的答案在传达信息时具有重要优势。图像能够直接展示信息,增强说服力,比如在描述猫的外观时,照片比文字更具直观性。而图文结合则通过融合文字与图像,提升了理解效果,尤其在步骤式说明中,图文并茂能够帮助更好地理解过程。除此之外,图像还可作为答案的补充元素,能够进一步丰富信息,例如在描述旅游景点时,结合文字和图像能有效增强答案的表现力,使信息更加生动和有吸引力。
为了解决MRAG中缺乏图文输出这一关键问题,我们首先形式化地提出了多模态检索增强多模态生成(MRAMG)任务,并且注意到对于这一关键任务,缺乏合适的RAG数据集来评估该任务上的表现,如图2所示。为此,我们构造了MRAMG-Bench,专门用于全面评估MRAMG任务。

图2 MRAMG-Bench与现有的的RAG 数据集的比较
数据构造
MRAMG-Bench的构建过程可以分为三个阶段:(1)数据选择与预处理,(2)问答生成与优化,(3)数据质量检查。该过程的概述如图 3 所示。
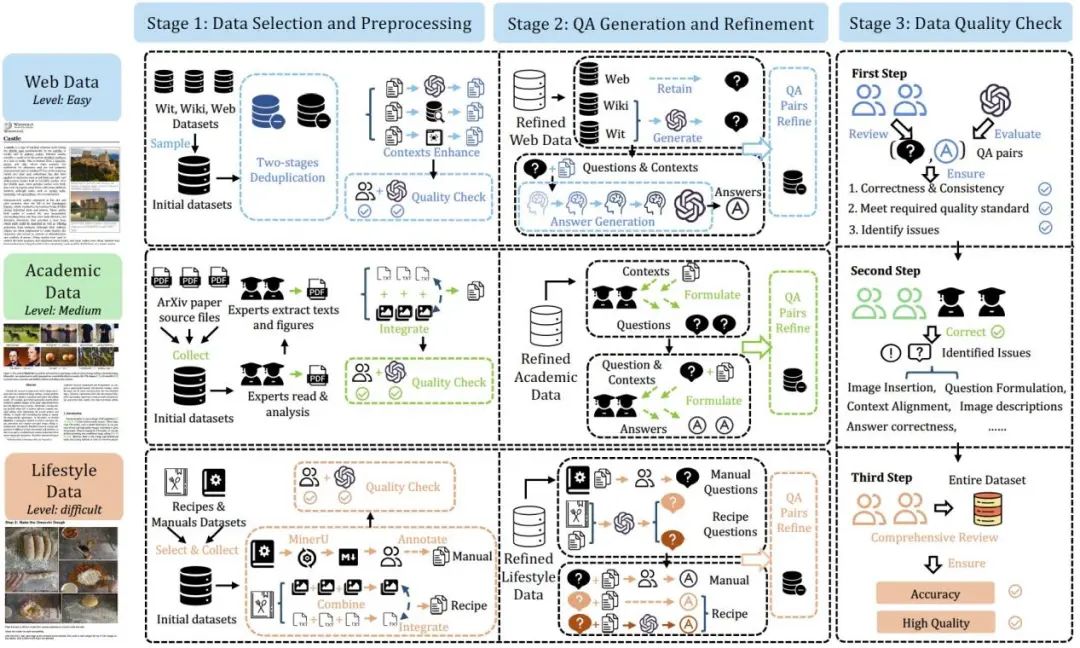
图3:MRAMG-Bench 的构建流程
第一阶段——数据选择与预处理:
网页数据(Web Data):我们使用了来自维基百科页面的数据,具体包括 Wit、WikiWeb2M 和 WebQA 数据集。这些数据集包含文本和图像的丰富集成,并被划分为多个难度级别。Web 数据集中的内容涉及各种主题,并包含文本和与其相关的图像(如图片、图表等。这些数据集被定义为低难度类别,旨在测试模型的基本多模态处理能力。
学术数据(Academic Data):
我们从 arXiv 数据库中收集了 2023 至 2024 年间发布的 150 篇 LaTeX 源文件及其对应的 PDF 文档。这些数据集被归类为中等难度,命名为 MRAMG-Arxiv,主要用于测试生成模型如何处理学术类多模态信息,特别是图文结合的内容。
生活数据(Lifestyle Data):
生活数据集包含来自 RecipeQA、ManualsLib 和 Technical 数据集 的内容,重点是实际应用场景,特别是食谱和操作手册。这些数据集通常含有较多图像,特别适用于测试模型在复杂环境下的表现。该类型数据集被定义为高难度,包含多种图像类型(单图像、无图像、多图像),以及复杂的图像插入任务。通过这些数据集,模型需处理多模态数据和图文对齐的挑战。
第二阶段——问答生成与优化:
在此阶段,我们利用GPT-4o和人工注释的方式生成和优化问答对。为了确保数据集的高质量,每个问答对都经过仔细筛选,确保它们能够有效测试MRAMG任务中的各类推理能力。
第三阶段——数据质量检查:
我们采用了多阶段质量检查流程,首先利用GPT-4o对生成的数据进行初步筛选和验证。然后,专家和人工注释员会对数据进行进一步的核查,以确保数据集的准确性和一致性。这些检查包括文本和图像的匹配度,确保每个问答对的文本内容和图片内容相辅相成,且图像的插入位置与问题的内容紧密相关。
数据集构成
MRAMG-Bench 包含六个精心策划的英文数据集,涵盖来自网页、学术和生活三个领域的内容。数据集总量包括:4,346篇文档、14,190张图片和4,800个QA对,旨在为多模态检索增强生成任务提供一个多样化和挑战性的数据基础。数据集不仅包括常规的简单问答对,还设计了难度分级和图片顺序选择的推理任务,能有效测试模型在处理复杂场景时的推理能力。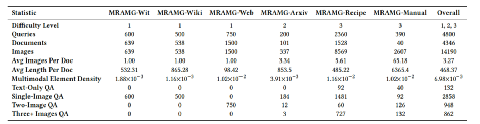
图4: MRAMG-Bench的数据统计情况
多模态检索增强—多模态生成框架
该框架包括两个阶段:(1)检索相关多模态文档。
(2) 基于检索到的信息生成多模态答案,使用基础生成模型。在第二阶段,我们提出了三种不同的答案生成策略:
(a)基于语言大模型的方法(LLM-based):使用LLM直接生成多模态答案。由于LLM无法直接处理图像,因此我们利用图像在文本上下文中的描述信息,以及图像本身的标题,作为文本的替代输入提供给语言模型。在生成的答案中,图像将以占位符的形式表示。
(b)基于多模态大模型的方法(MLLM-based ):使用MLLM直接生成多模态答案。该方法接受图像输入,选择适当的图像并将其与文本一起输出,输出中的图像同样表示为占位符。
(c)基于规则的方法(Rule-based):首先通过生成模型获得纯文本答案,并将其划分为句子。然后构建“句子——图像”二部图,利用二部图匹配算法将适当的图像插入到文本答案中,从而生成多模态答案。
实验结果
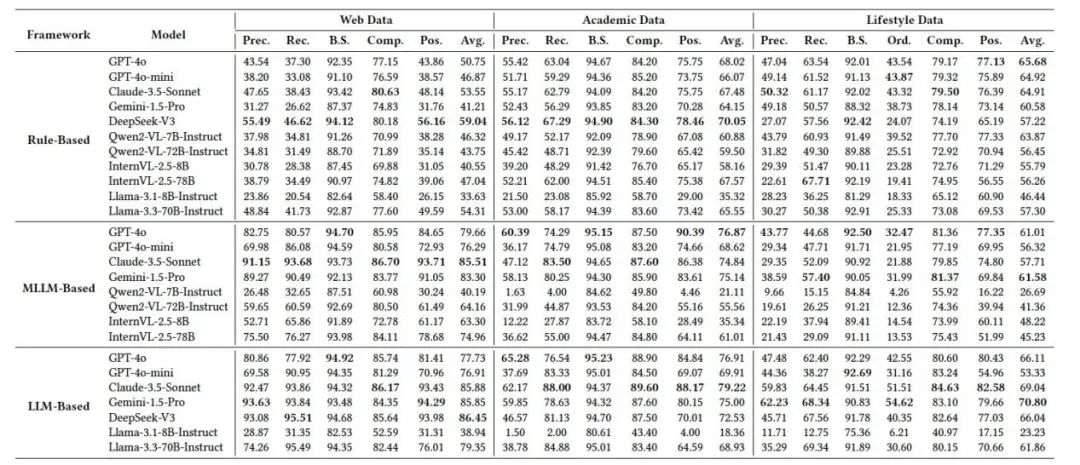
图5:MRAMG-Bench的综合性能评估结果。
我们对11种流行的生成模型在MRAMG-Bench上的表现进行了全面评估,其结果如图4所示。实验结果表明,诸如GPT-4o、Gemini、Claude和Deepseek-V3等先进语言模型在所有领域数据和方法中始终优于小型开源模型。这些小型模型在不同方法和数据集领域中普遍表现不佳。相比之下,大型开源模型显著缩小了与闭源模型的性能差距,尤其在简单的数据集(如网页数据)上,性能接近闭源模型。然而,在更具挑战性的数据集上,开源模型与闭源模型的差距变得更加明显,暴露了它们在处理复杂MRAMG任务时的局限性。
在不同多模态答案生成方法的比较中,出现了一个整体性能趋势:
LLM-based > MLLM-based > Rule-based。
LLM-Based 方法: 通过将图像的上下文信息集成到生成过程中,该方法能够实现自然且准确的图像插入,强调了上下文在确保插入准确性方面的关键作用。
MLLM-Based 方法: 在较简单的数据集(如网页数据)上有效,但在其他困难数据集上表现下降,显示多模态模型在处理复杂图文的局限性。
Rule-Based 方法: 尽管这些方法在较简单的数据集上的性能明显低于基于模型的方法,但随着数据集复杂度的增加,性能差距逐渐缩小。对于生活领域,基于规则的方法甚至超越了某些基于模型的方法。
总体而言,尽管基于规则方法在资源受限或对稳定性要求较高的场景中,提供了一个可行且高效的替代方案。同时,基于LLM的方法通常表现更优,展示了现代大型模型在上下文推理方面的强大能力。
总结
随着多模态答案需求的增加,MRAMG已成为与实际需求紧密对接的关键任务。为填补该任务评估资源的空白,我们推出了 MRAMG-Bench 基准数据集,包含4,800个涵盖不同领域和难度的问答对,并提出了结合统计与大语言模型指标的全面评估策略。此外,我们推出了通用MRAMG框架,支持生成交织的文本-图像响应。通过对11种主流生成模型的评估,我们发现它们在处理复杂数据集和图像顺序选择上存在显著局限性,凸显了深入研究MRAMG任务的必要性。该基准为未来的MRAMG方法设计与评估提供了重要基础,并已在Hugging Face平台上开源。我们期待更多研究共同推动多模态RAG技术的发展,欢迎大家积极使用并贡献!
(文:机器学习算法与自然语言处理)