


阶跃星辰正式发布并开源图像编辑大模型 Step1X-Edit,性能达到开源 SOTA。该模型总参数量为 19B (7B MLLM + 12B DiT),具备语义精准解析、身份一致性保持、高精度区域级控制三项关键能力;支持 11 类高频图像编辑任务类型,如文字替换、风格迁移、材质变换、人物修图等。
一句话总结:Step1X-Edit,不只能“改图”,更能“听得懂、改得准、保得住”。
开源链接与体验地址:
Github:
https://github.com/stepfun-ai/Step1X-Edit
HuggingFace:
https://huggingface.co/stepfun-ai/Step1X-Edit
ModelScope:
https://www.modelscope.cn/models/stepfun-ai/Step1X-Edit/summary
技术 Report:
https://arxiv.org/pdf/2504.17761

编辑效果演示:Step1X-Edit 支持各类编辑任务
Step1X-Edit 首次在开源体系中实现 MLLM 与 DiT 的深度融合,在编辑精度与图像保真度上实现大幅提升。在最新发布的图像编辑基准 GEdit-Bench 中,Step1X-Edit 在语义一致性、图像质量与综合得分三项指标上全面领先现有开源模型,比肩 GPT-4o 与 Gemini 2.0 Flash。
Step1X-Edit 现已上线阶跃AI 官网(stepfun.com)和阶跃App(应用商店搜索下载即可),欢迎体验。

-
高浓度的主流模型(如 DeepSeek 等)开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传。
模型特点与参数
Step1X-Edit 针对自然语言图像编辑任务,具备以下核心能力:
-
语义精准解析:支持自然语言描述的复杂组合指令,指令无需模板,能够灵活应对多轮、多任务编辑需求,同时支持对图像中文字进行识别、替换与重构;
-
身份一致性保持:编辑后能稳定保留人脸、姿态与身份特征,适用于虚拟人、电商模特、社交图像等高一致性场景;
-
高精度区域级控制:支持对指定区域进行文字、材质、色彩等定向编辑,保持图像风格统一,控制能力更精细。

编辑任务效果对比:Step1X-Edit 实现最佳编辑效果与原图一致性
案例上手
这个五一,不如试试用嘴改图,无论是修图,还是瘦身,都能一句话搞定。Step1X-Edit 已在【阶跃AI 网页端和阶跃AI App】上线,欢迎前往体验。
案例一:一句话P图
 原图 |
 编辑后 |
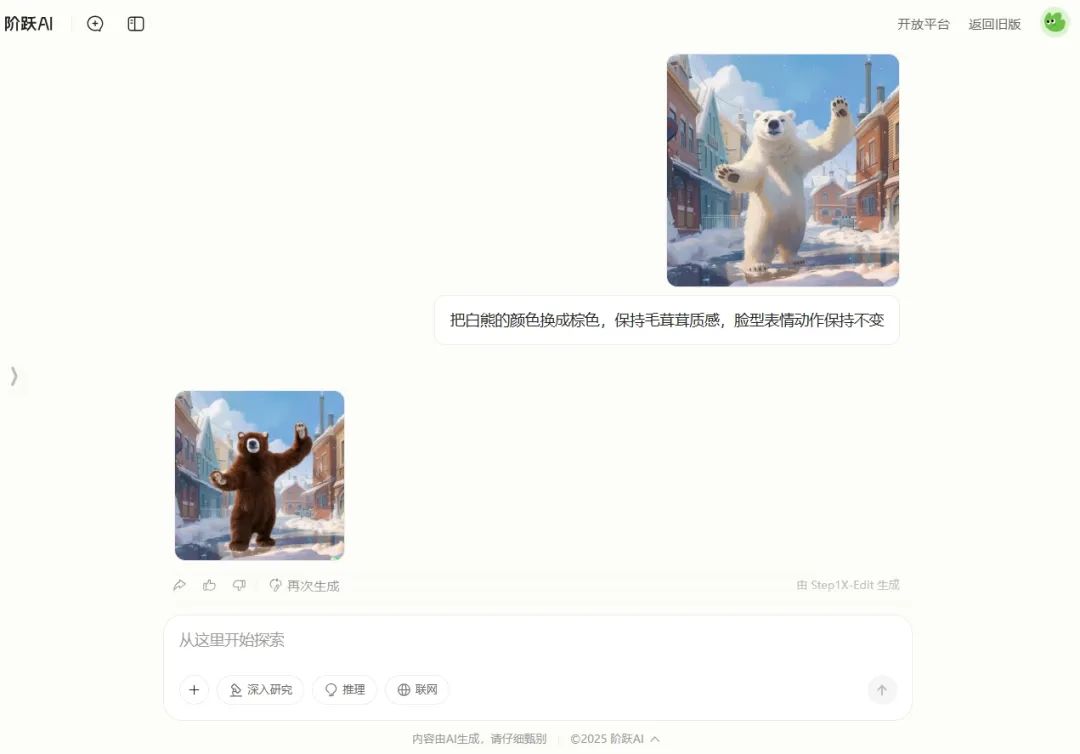
提示词:给小姐姐脖子上增加一条适合她的项链
 原图 |
 原图 |
提示词:把这个小女孩改成戴珍珠耳环的不高兴的少女,画风不变
案例二:物体/背景/材质,统统都能换
 原图 |
 编辑后 |
提示词:将月饼替换为包子
 原图 |
 编辑后 |
提示词:把图里的水果变成一朵花
案例三:一句话改海报文案
 原图 |
 编辑后 |
提示词:将“GREEN” 改成“阶 跃 A I”
案例四:玩转不同风格
 原图 |
 编辑后 |
提示词:以融合超现实主义、表现主义和天真艺术的风格重绘这幅图片,以近乎民俗的方式捕捉抽象人类情感和互动的简单性和复杂性。原始而有机的感觉,以孩子般的方式勾勒主体轮廓。采用原生艺术风格,使用对比和分层来创造混乱但有凝聚力的视觉冲击。俏皮地使用线条和颜色,主体元素既简单又富有象征意义。
 原图 |
 编辑后 |
提示词:创建一张色彩鲜艳的手工簇绒地毯图片,放置在简单的地板背景上。地毯设计大胆、有趣,具有柔软蓬松的质地和粗纱线细节。从上方拍摄,在自然日光下,带有略微古怪的 DIY 美学风格。色彩鲜艳、卡通轮廓、触感舒适的材料——类似于手工簇绒艺术地毯。
 原图 |
 编辑后 |
提示词:换成像素风格
 原图 |
 编辑后 |
提示词:将图片改为清晨
Step1X-Edit 采用 MLLM(Multimodal LLM)+ Diffusion 的解耦式架构,分别负责自然语言理解与高保真图像生成,相比现有图像编辑模型,该架构在指令泛化能力与图像可控性上更具优势。
-
MLLM 模块负责处理自然语言指令与图像内容,具备多模态语义理解能力,可将复杂编辑需求解析为 latent 控制信号;
-
Diffusion 模块作为图像生成器(Image Decoder),根据 MLLM 生成的 latent 信号完成图像的重构或局部修改,确保图像细节保真与风格统一。
这一结构打破了传统 pipeline 模型中“理解”和“生成”各自为政的问题,使模型在执行复杂编辑指令时具备更高的准确性与控制力。
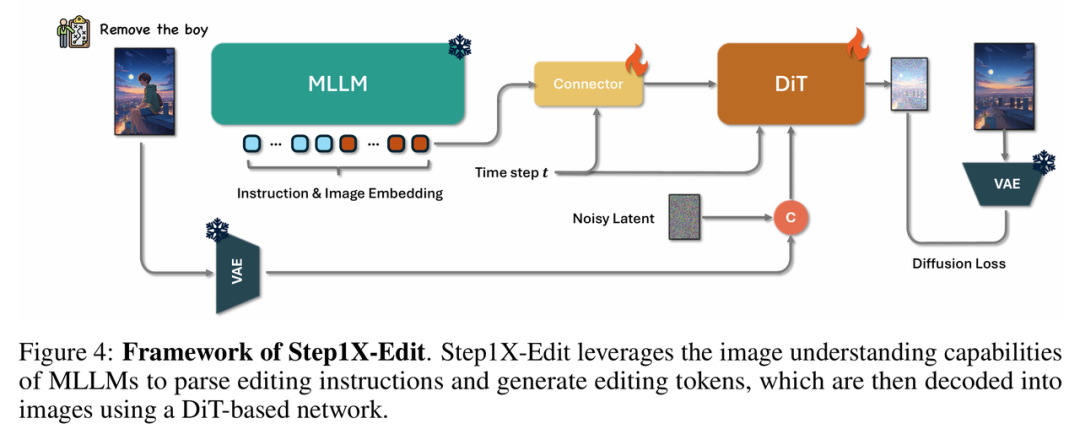
Step1X-Edit 架构
训练数据与评测结果
为了支持广泛、复杂的图像编辑任务,Step1X-Edit 构建了业内规模领先的图像编辑训练数据集,共生成 2000 万条图文指令三元组,最终保留超过 100 万高质量样本。数据覆盖 11 类核心任务类型,包括文字替换、动作生成、风格迁移、背景调整等高频需求,任务类型分布均衡,指令语言自然真实。
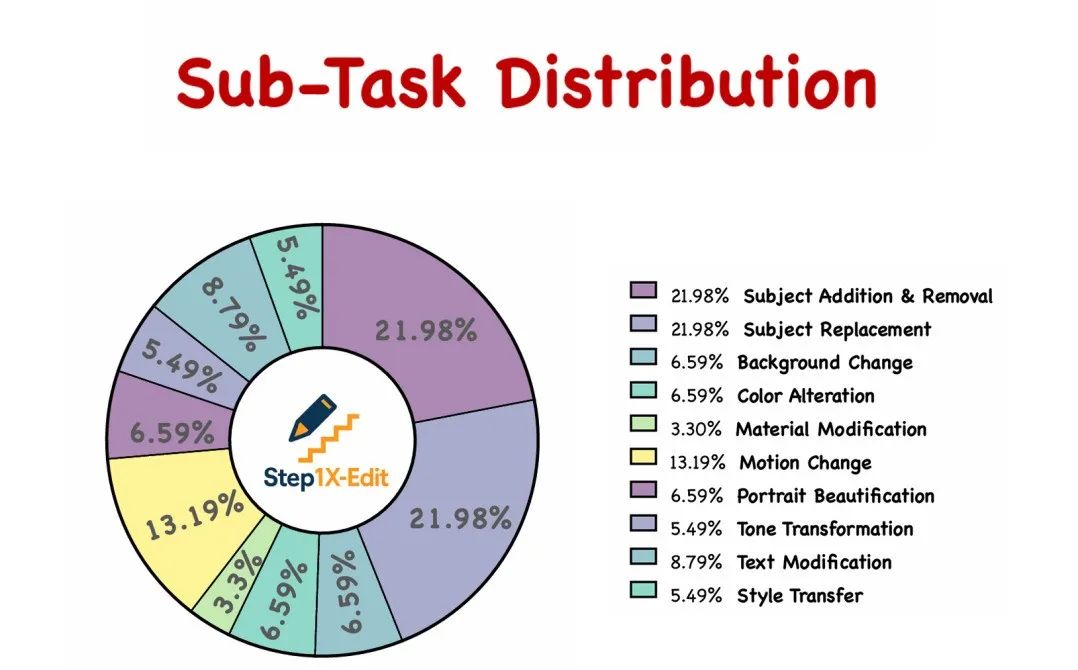
Sub-Task Distribution:数据集任务分布与样本结构占比
在图像编辑的 11 个细分任务中,Step1X-Edit 始终维持高质量输出,能力分布最均衡,几乎在所有任务维度上稳居前列,展现出强大的通用性与均衡性。

图像编辑模型11类细分任务能力分布对比
模型评测采用自研 GEdit-Bench 基准,区别于人工合成的任务集合,该基准来源于社区真实编辑请求,更贴近产品化需求。
Step1X-Edit 在 GEdit-Bench 的三项核心指标中均大幅领先现有开源模型,表现接近 GPT-4o,在语言理解与图像重构之间实现理想平衡。
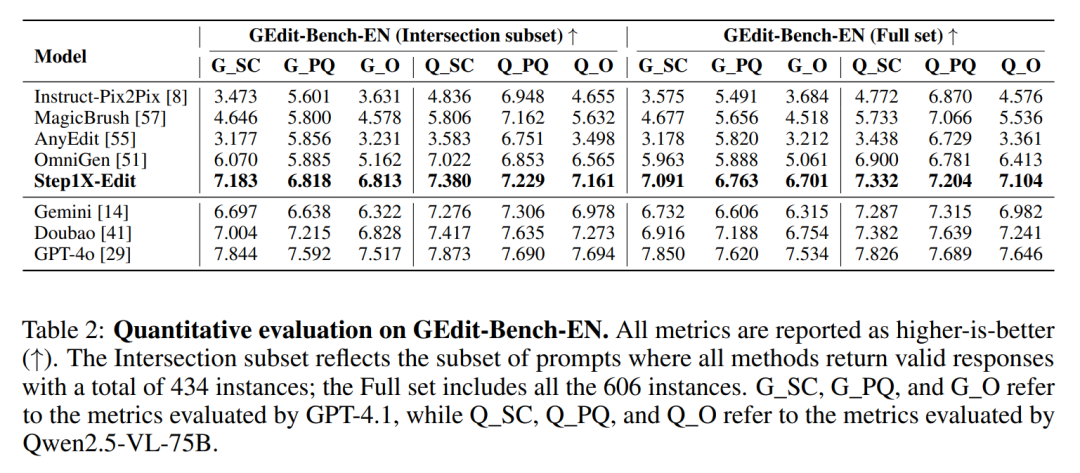
GEdit-Bench 量化评测结果对比
(文:Founder Park)