


多模态大语言模型(MLLM)作为具身智能(Embodied AI)和自动驾驶(Autonomous Driving)的端到端解决方案已成为主流趋势,并在视觉语义理解任务中取得了显著进展。
然而,它们在现实世界应用中执行精确、定量时空理解(例如估计和预测物体的外观、姿态、位移和运动)的能力很大程度上未经检验,这使得它们在物理世界交互中的前景充满不确定性。
为了系统评估模型的时空智能(Spatial-Temporal Intelligence),上海交通大学联合国际研究团队推出了 STI-Bench,这是首个专注于精确时空世界理解的基准测试。
研究发现,即便是如 GPT-4o 和 Gemini 2.5 Pro 等前沿模型,在面对需要精确定量分析的任务时仍显吃力,平均准确率不足 42%,揭示了当前 MLLM 距离可靠的物理世界理解与交互仍有显著差距。

论文标题:
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?
论文链接:
https://arxiv.org/pdf/2503.23765
论文主页:
https://mira-sjtu.github.io/STI-Bench.io/
Github:
https://github.com/MIRA-SJTU/STI-Bench
Huggingface:
https://huggingface.co/datasets/MIRA-SJTU/STI-Bench

STI-Bench:“时空智能”的全面基准测试
STI-Bench 精心构建了一个三维评测体系,使用了超过 300 个源自真实世界的视频片段,覆盖了桌面级精细操作(来自 Omni6DPose 高精度 6D 姿态数据集)、室内环境导航与交互(来自 ScanNet 室内三维重建数据集)以及户外复杂动态驾驶场景(来自 Waymo 开放驾驶数据集)。
该基准设计了八项独特的挑战性任务,系统性地评估模型在两个维度的能力:
静态空间理解,包括尺度度量(估算物体几何尺寸、物体间或相机与物体间的距离)、空间关系(在不同参考系下识别物体间的相对方位,如前后左右上下)以及 3D 视频定位(根据语义描述定位物体在特定时间点的 3D 边界框,输出包含长宽高、中心坐标及可能涉及的旋转信息)。
动态时序理解,涵盖位移与路径长度计算(跟踪目标并积分跨帧运动信息)、速度与加速度分析(计算空间位移对时间的导数)、自我中心方向变化(估计相机在水平面上的旋转角度变化)、轨迹描述(将复杂运动路径抽象为分段的简洁语言描述)以及姿态估计(基于初始位姿和 RGB 视频序列推断相机后续时刻的 3D 姿态,考验视觉里程计能力和误差累积控制)。
为了确保评测的客观性和严谨性,研究团队利用数据集提供的逐帧点云、相机内外参数等精细标注计算了各项任务的物理量真值,并借助 GPT-4o 生成语义丰富、逻辑合理的 QA 对及干扰选项。
随后,通过专门设计的网站进行多轮严格的人工审核与过滤,最终筛选出超过 2000 个高质量 QA 对。特别地,STI-Bench 针对不同场景的精度要求(桌面毫米级、室内厘米级、户外界于分米级)动态调整了答案选项间的数值差异(采用对数采样避免聚集),使得基准既具挑战性,又贴合真实世界应用的精度需求。


实验结果
研究团队在 STI-Bench 上对一系列业界领先的 MLLM 进行了全面评估,涵盖了四款强大的专有闭源模型(GPT-4o、Gemini-2.0-Flash、Gemini-2.5-Pro、Claude-3.7-Sonnet)以及数个经过视频相关训练优化的代表性开源模型(如 Qwen2.5-VL-72B、InternVL2.5-78B、VideoLLaMA3-7B、MiniCPM-V-2.6、VideoChat-Flash)。
结果显示,所有受测模型在 STI-Bench 上的整体表现揭示了显著的时空理解能力局限性。其中,性能最佳的开源模型 Qwen2.5-VL-72B 和专有模型 Gemini-2.5-Pro 分别取得了 41.3% 和 40.9% 的平均准确率。
尽管这些分数显著优于 20% 的随机猜测基线,但距离在具身智能、自动驾驶等高要求应用中实现可靠部署仍有巨大鸿沟。
对物理量的精确定量估计成为模型的普遍短板,例如,在尺度度量任务上表现最好的 Gemini-2.5-Pro 准确率仅为 34.2%,位移与路径长度任务由 Gemini-2.0- Flash 以 32.7% 领先,而速度与加速度分析则由 Claude-3.7-Sonnet 以 36.9% 拔得头筹,这些偏低的准确率系统性地反映了当前模型在空间量化方面的缺陷。

此外,模型表现出明显的场景依赖性:Qwen2.5-VL 在户外场景中表现突出(49.2%),而 Gemini-2.5-Pro 则在室内场景更具优势(38.6%),Claude-3.7-Sonnet 和 Gemini-2.0-Flash 在桌面场景表现较好(均为 37.4%),这可能与模型的训练数据分布或架构设计在处理不同环境线索上的差异有关。
值得注意的是,开源模型 Qwen2.5-VL-72B 在此次评测中以微弱优势(41.3%)超越了所有参评的顶尖专有模型,展现了开源社区的深厚实力。


错误原因分析
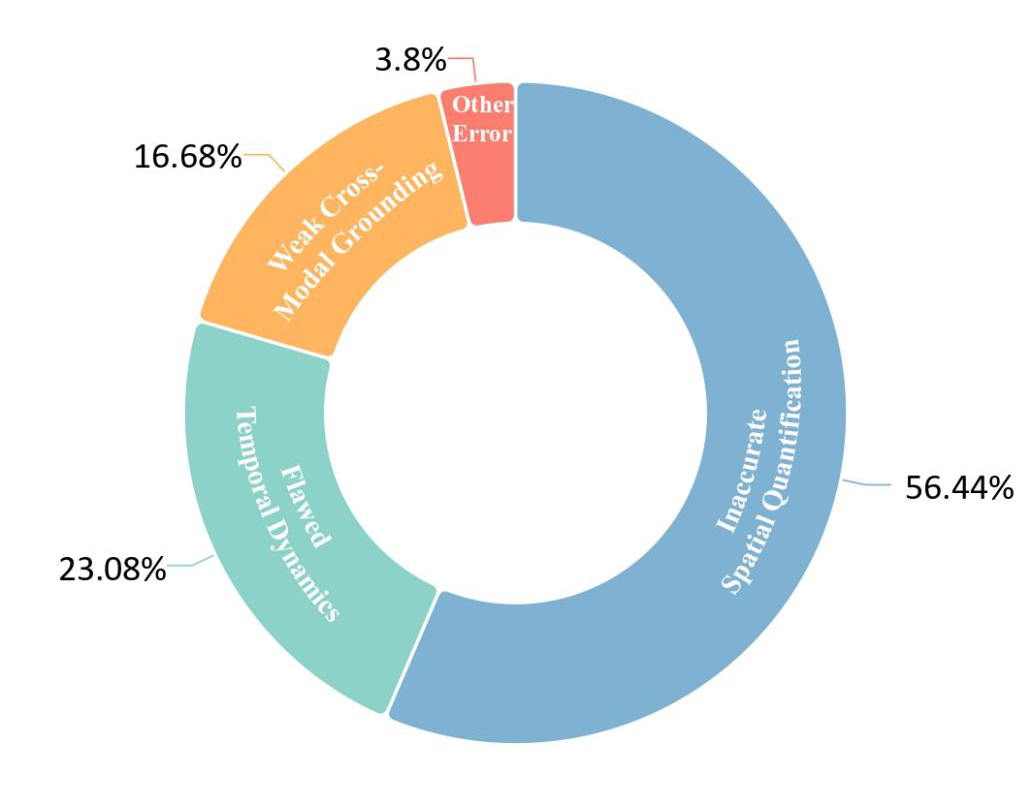
通过对表现相对优异的 Gemini-2.5-Pro 进行深入的错误案例分析(抽样约 200 例错误),研究识别出当前 MLLM 在时空理解方面存在的三大核心瓶颈,其分布大致为:空间量化不准(约 56.4%)、时序动态理解错误(约 23.1%)和跨模态关联整合薄弱(约 16.7%)。
首先,空间量化不准确是最大的问题,模型难以从单目视频输入中精确估计物体的几何尺寸、相对距离或绝对 3D 坐标/边界框,这源于缺乏可靠的视觉尺寸参照、难以区分数值接近的选项以及从 2D 像素推断度量尺度和深度的固有挑战。
其次,时序动态理解存在缺陷,模型在感知、跟踪和解释跨时间帧变化的信息(如运动及其动力学特性)方面表现挣扎,导致在计算位移、路径长度、速度、加速度、方向变化(自我中心或物体姿态)以及描述整体轨迹时出错。
这归因于跨帧信息整合的困难、缺乏内置的物理/运动学模型、难以分离自我运动与物体运动,以及稀疏时间采样导致的信息丢失。
最后,跨模态关联与整合能力薄弱,模型无法准确地将文本查询/指令(如时间约束“从 1s 到 18s”、“结束时”)与相关的时空视觉内容联系起来,或者无法有效整合提供的非视觉信息(如姿态估计任务中的初始相机位姿)与视觉观察。
这源于解析结构化/自然语言指令的不足,以及在统一推理过程中融合不同模态信息(文本提示、初始状态数据、视频帧)的困难。
这些系统性的错误模式共同导致了模型在精确时空任务上的低效表现,并指明了未来研究需要在多模态对齐、物理知识融入、跨帧信息表征等方面取得关键突破。

总结
STI-Bench 的评测结果清晰地揭示了当前最先进的多模态大语言模型在精确、量化的空间-时间理解能力方面存在的严重短板,即使是顶尖模型也远未达到可靠应用的水平(最高准确率仅约 41%)。
精确的时空理解是 MLLM 从虚拟信息处理迈向真实物理世界交互的关键一步,对于其在具身智能、机器人控制、自动驾驶等领域发挥核心作用至关重要。
STI-Bench 作为首个专注于此能力的系统性基准,不仅量化了当前的技术差距,剖析了核心瓶颈,更为社区提供了一个宝贵的评估框架和“试金石”,用以衡量、对比和驱动下一代 MLLM 在理解和推理物理世界方面的进步。
该项目的所有资源,包括论文、代码、数据集及排行榜,均已开放获取,以期促进该领域的进一步发展。
(文:PaperWeekly)