


4月15日,这一天,AI行业头条是属于智谱的。
GPT-4.1、可灵2.0来了,都挡不住。因为智谱带来了三连发。
一曰快,二曰短,三曰先。
一、快
快,有2层意思。
一是快速开源了3类模型:基座、推理、沉思。

应上月最后一天中关村论坛承诺,半月后的昨天,智谱一次性开源了基座、推理、沉思三类六款模型。
基座模型GLM-4-32B-0414,性能媲国内、外参数量更大的主流模型,如Qwen2.5-Max(Qwen说勿cue,我马上要发布Qwen3了)、GPT-4o、DeepSeek-V3-0324。在指令遵循、智能体工具调用、搜索质量方面表现不错。

代码生成能力也得到了进一步提升,在智谱新域名Z.ai使用即可预览代码,支持对HTML和SVG的可视化查看。
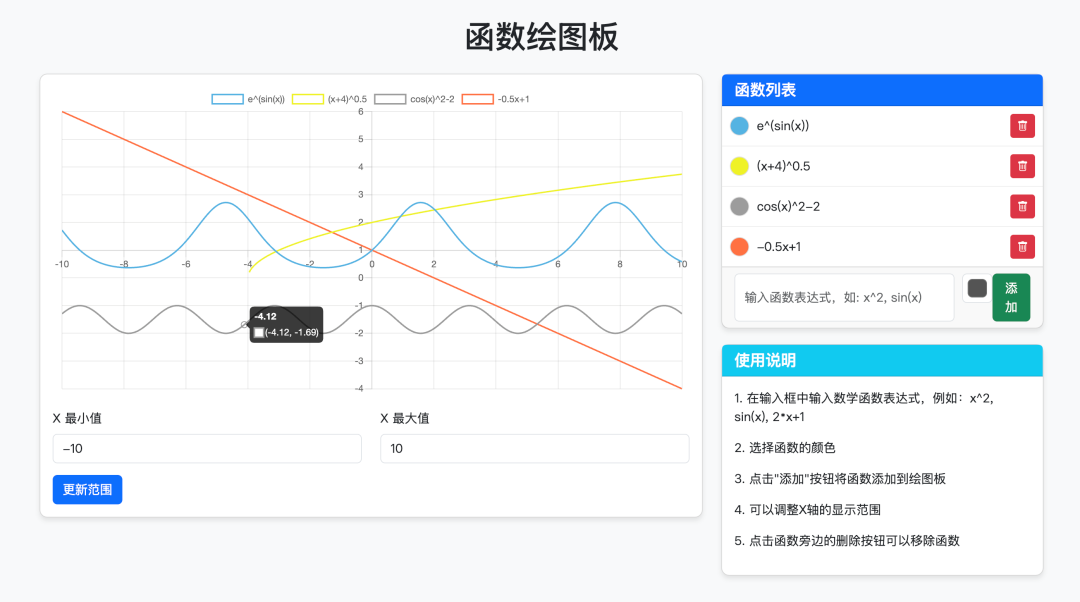
提示词:设计一个支持自定义函数绘制的绘图板,可以添加和删除自定义函数,并为函数指定颜色。
推理模型GLM-Z1-32B-0414,基于GLM-4-32B-0414进行后训练,在数学、代码、逻辑等方面进行了深度优化,数理能力和复杂问题解决能力得到显著增强。凭借32B参数,性能不输671B的R1模型(Qwen说,我也是如此)。
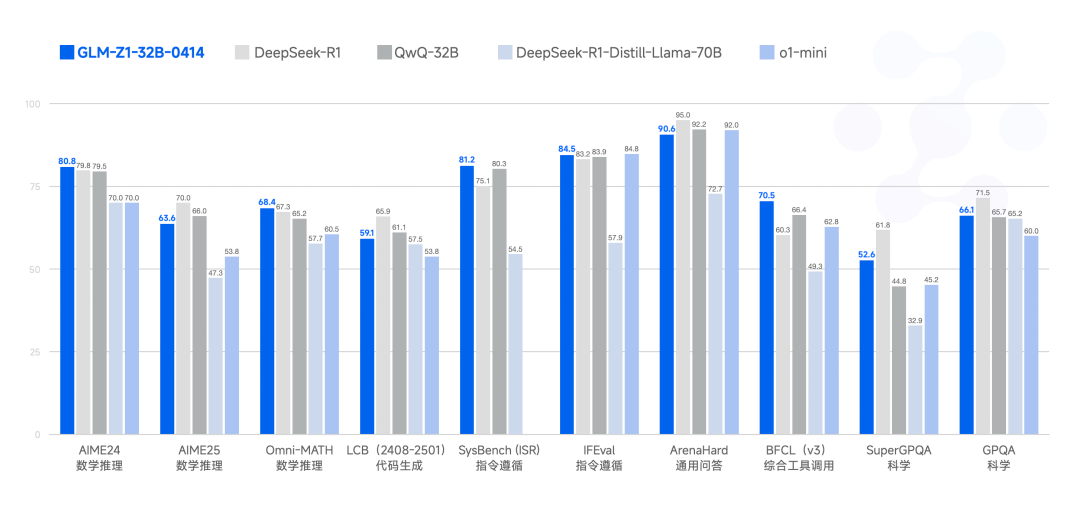
同时,也开源了沉思模型GLM-Z1-Rumination-32B-0414,代表了智谱对AGI未来形态的下一步探索。
沉思模型,简单来说,就是DeepResearch功能的底层模型。它通过更多步骤的深度思考,特别擅长研究型写作和复杂检索任务。
也可以理解为,推理模型+搜索+工具调用=沉思模型=DeepResearch。
我用Z.ai随便测了个Case,发现新版GLM-Z1-Rumination模型比智谱半月前发布的沉思模型快多了,而且它还能搜索X、Google等平台的消息,这就有点厉害了(悄悄说 )。
)。
Case完整视频,我放这里了。
这是快的第一层意思,快速开源三类六款模型,且都采用了最宽松的MIT许可协议,所有人可免费商用、自由修改和分发。智谱真NB。
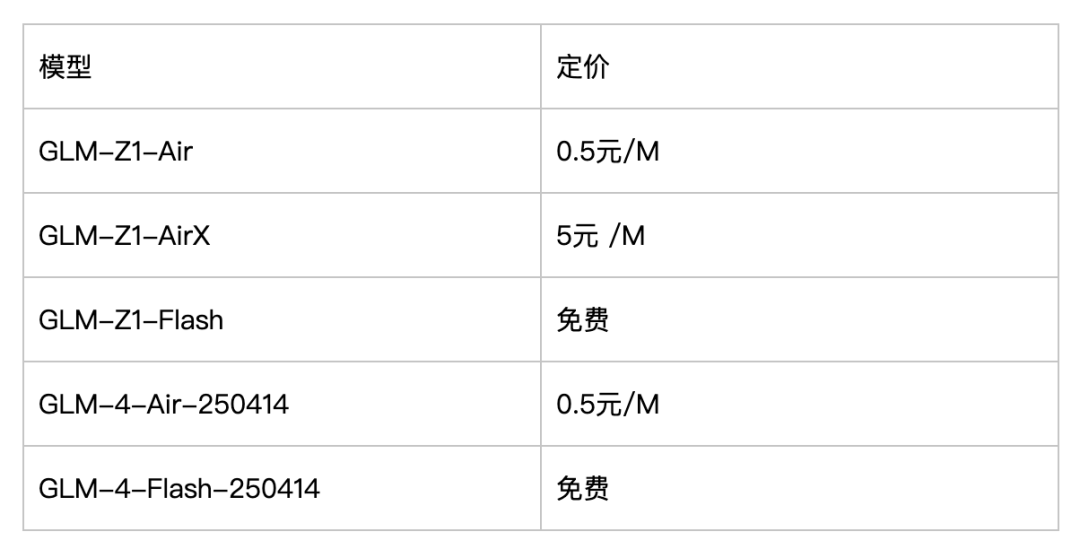
二是上线了特别快的GLM-Z1-AirX(极速版)推理模型。
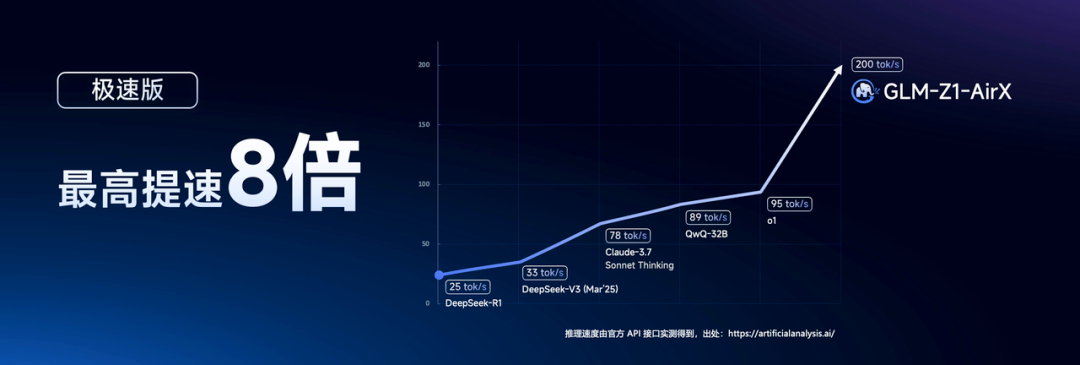
有多快呢?200 tokens/秒。朋友赛博禅心说:“大概就0.3秒,AI的回答已经出现在了屏幕上。”
也就是一眨眼的功夫,AI完成了首响应以及50个汉字生成,输入与输出几乎同时发生(详见赛博禅心文章)。
如果想要体验这款“瞬时模型”,可通过智谱API平台bigmodel.cn调用,5元/百万tokens。
如果觉得贵了,也可以选择他们家的GLM-Z1-Air(高性价比版)和GLM-Z1-Flash(免费版)。
二、短
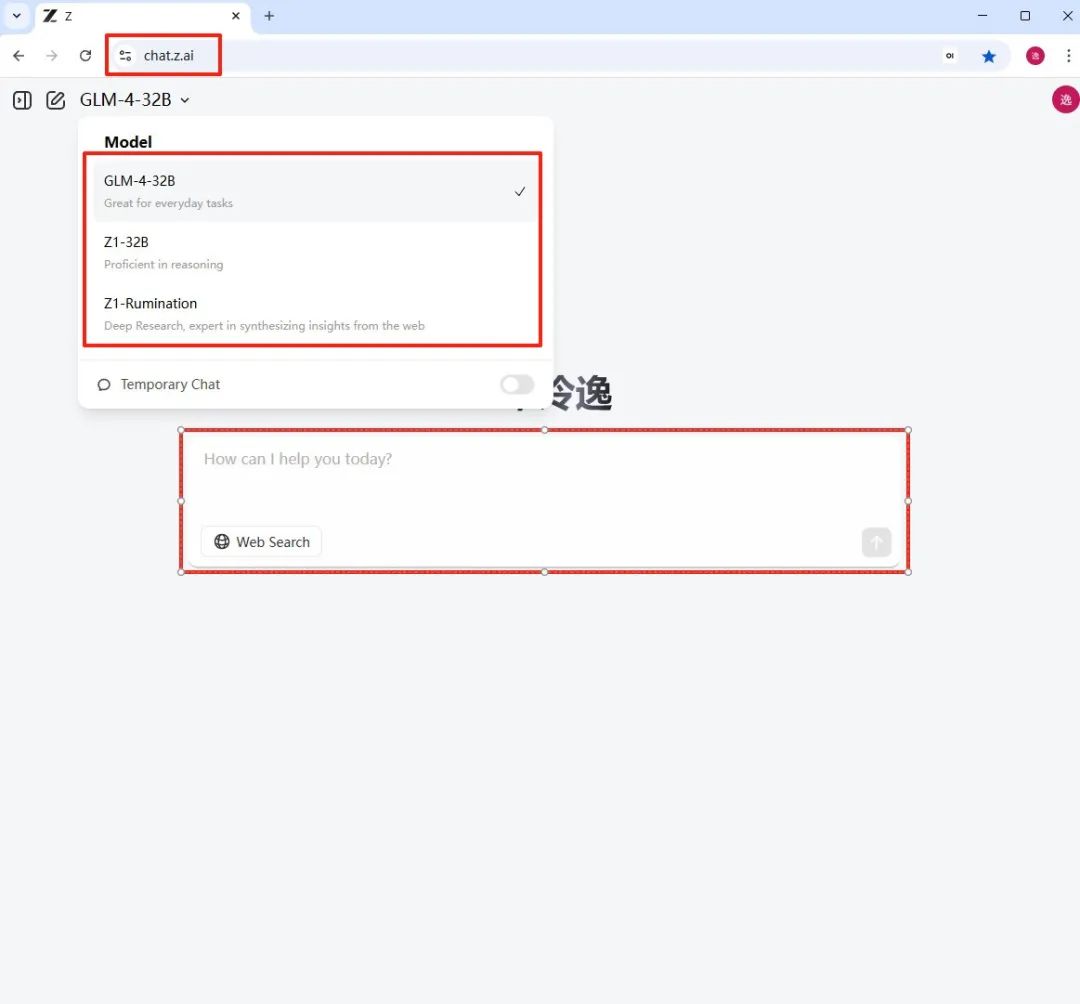
4月15日,智谱启用了全新的域名Z.ai,也是面向全球用户的域名。
Qwen第三次说,这和我们的Qwen.ai怎么有点像;智谱回,别说又像你,你我心知肚明,大家都是基于OpenWebUI项目来研发的。
目前,Z.ai支持3款模型:GLM-4-32B、Z1-32B和Z1-Rumination-32B。
基座、推理、沉思,该Z.ai的,都Z.ai。
因为刚刚上线,目前仅支持谷歌、GitHub等海外账户登陆。国内用户想要体验,需要魔法。
我体验了下,个人作为极简主义的拥趸,Z.ai用起来是真爽,不会又拿了跟阿里一样的剧本吧(Qwen.ai干掉了自家的通义 )。
)。
三、先
4月15日,智谱还有一则更劲爆的消息。
智谱正式启动了上市辅导备案工作,由中金辅导,预计在今年10月前完成辅导工作,并提交上市申请(大概率是科创板/创业板)。

这是国内AI大模型第一家申请上市的公司,最快可在明年6月前见到他们的二级市场股票。
这对于智谱的投资人、股东、员工以及用户(比如我这种充了他们家年卡会员的人),绝对是一个超级利好的消息。

现在,应该算是接近Pro-IPO轮前,业内对智谱估值200亿。正式上市,其市值飙升到500甚至千亿不是没有可能。
不得不说,六小虎里(其实,目前基本上只剩下4虎2猫了),智谱又拉开了一个身位。
写在最后
昨天,某模型因“性能提升30%,价格提升500%”在行业内引发争议。
大家觉得,这怎么好像完全不符合摩尔定律和尺度定律Scaling Law呢?
这个问题,在智谱这里得到了很好的答案——真正的技术进步不是闭源垄断,而是开放共享。
智谱,在很多方面都“起了个大早”(注意,可没有后面那句话)。有自己的AGI路线图,有自己的产品体系,有自己对AI未来的远大抱负。
与其说是“起了个大早”,不如说是“先行者”。
在China WayToAGI的路上,总有人要先行,为什么不能是智谱呢?
(文:沃垠AI)