

今天是2025年4月12日,星期六,北京,大风。
今天我们来看看RAG的一个竞赛以及获奖方案,其中有些思路值得参考,尤其是文档处理,提示词的设计、路由的设计以及针对表格处理逻辑。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、RAG-Challenge-2竞赛介绍
我们来看看一个比赛,RAG-Challenge-2(https://abdullin.com/erc/,https://kkgithub.com/trustbit/enterprise-rag-challenge/tree/main)。
数据上,包括年度报告(7496个文件,约46GB)的列表,以及公司名称和文件sha1哈希值,这些年度报告属于公开信息。
任务是创建一个基于公司年报的问答系统。
简单来说,比赛流程如下:获得100份来自随机选择的公司的年度报告,以及2.5小时的时间来解析它们并构建一个数据库。这些报告是PDF格式的,每份长达1000页。然后,会生成100个随机问题(基于预定义的模板),你的系统必须尽快回答这些问题。
所有问题都必须有明确的答案,例如:是/否问题;公司名称(在某些情况下可能涉及多个公司名称)问题;领导职位的头衔、推出的产品问题;数值指标:收入、店铺数量等问题。
例如:
数字:“Accuray Incorporated”在 2022 年第二季度在风险管理上花费了多少?
姓名:谁是“Zegona Communications plc”公司的首席执行官?
布尔值:2021 年第二季度“Global Medical REIT Inc.”的债务权益比是否高于“Zegona Communications plc”?
数量:截至 2021 财年末,“Accuray Incorporated” 有多少家门店?
数字:2023 年第二季度“桑德韦尔水上运动中心”在研发上花费了多少?
姓名:谁是“EMT”公司的首席财务官?
布尔值:2023 年第二季度“Calyxt, Inc.”的资产回报率 (ROA) 是否高于“Global Medical REIT Inc.”?
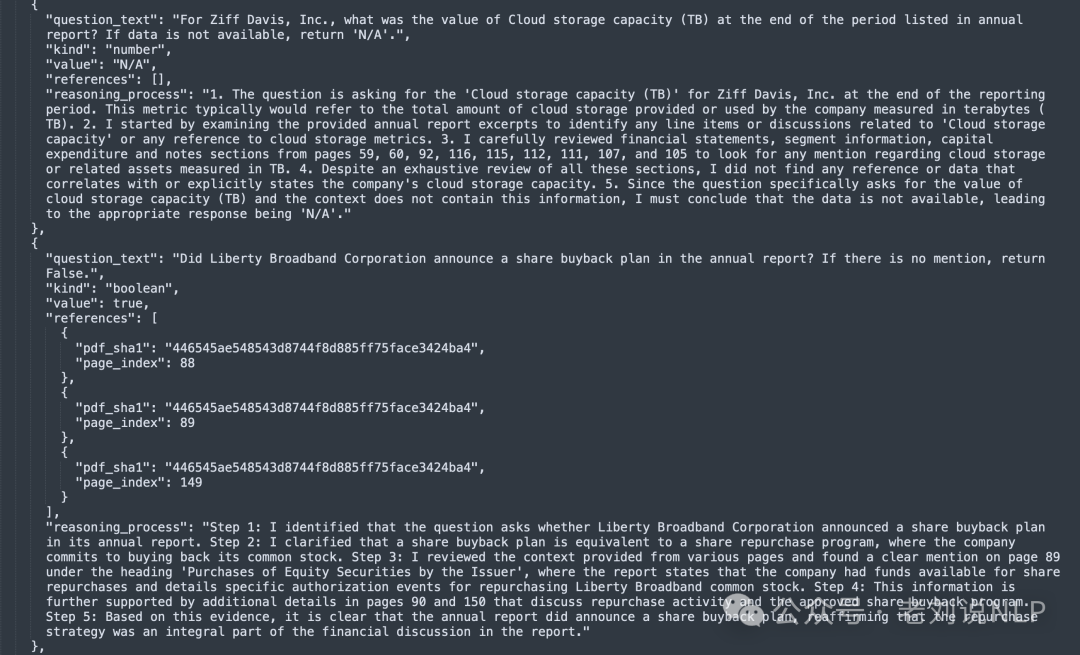
每个答案都必须包含包含答案证据的页面的引用,以确保系统真正得出答案而不是产生幻觉。
样例如下:https://kkgithub.com/IlyaRice/RAG-Challenge-2/blob/main/data/erc2_set/answers_1st_place_o3-mini.json
二、RAG竞赛优胜技术方案
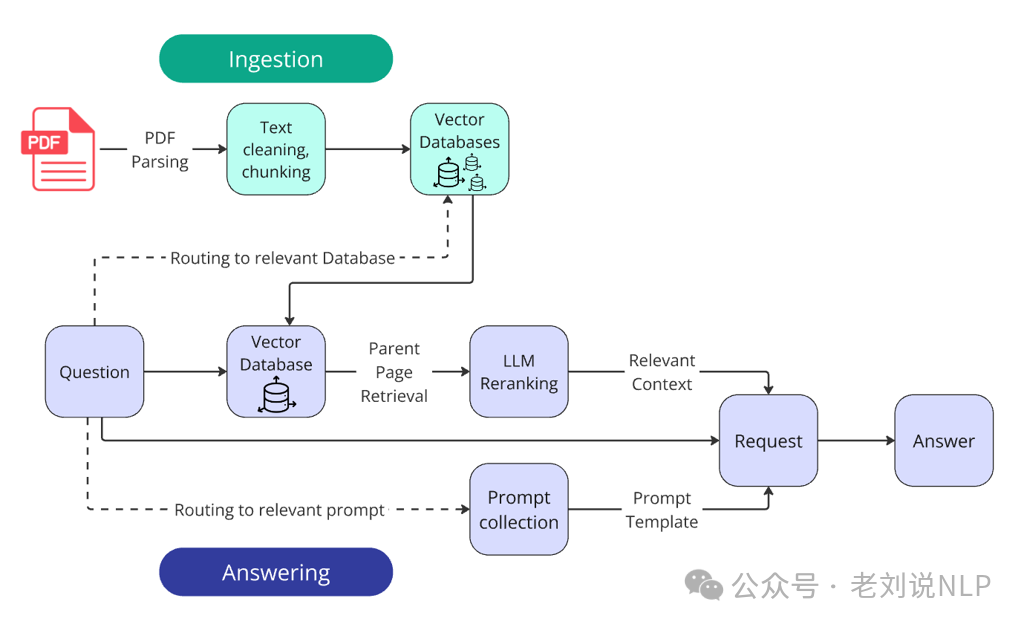
一个公司年报问题问答冠军方案(https://github.com/IlyaRice/RAG-Challenge-2,https://abdullin.com/ilya/how-to-build-best-rag/),整体技术架构如下,核心特点就是
-
Custom PDF parsing with Docling -
Vector search with parent document retrieval -
LLM reranking for improved context relevance -
Structured output prompting with chain-of-thought reasoning -
Query routing for multi-company comparisons
技术细节上的几个点:
1、文档解析
要开始填充任何数据库,必须先将PDF文档转换为纯文本。PDF解析是一项极其复杂的任务,存在一些明显的困难,如保存表结构;保留关键的格式元素(例如标题和项目符号列表);识别多列文本;需要处理图表、图像、公式、页眉/页脚等。尤其是大表格有时会旋转90度,导致解析器产生乱码和不可读的文本。
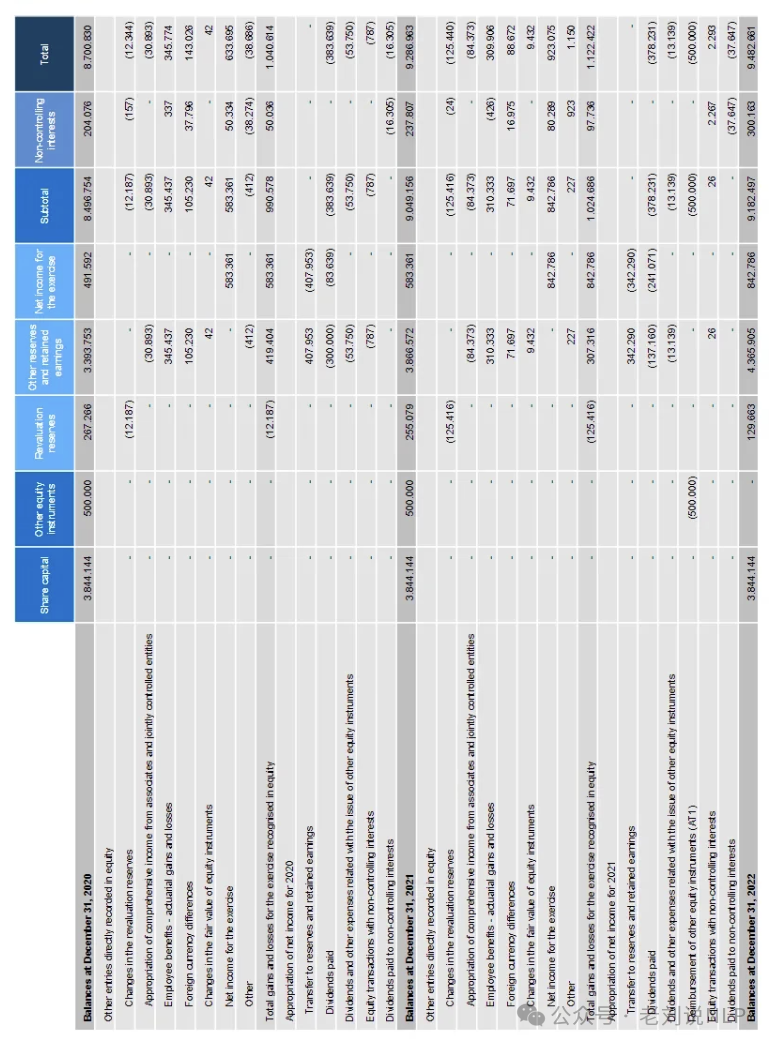
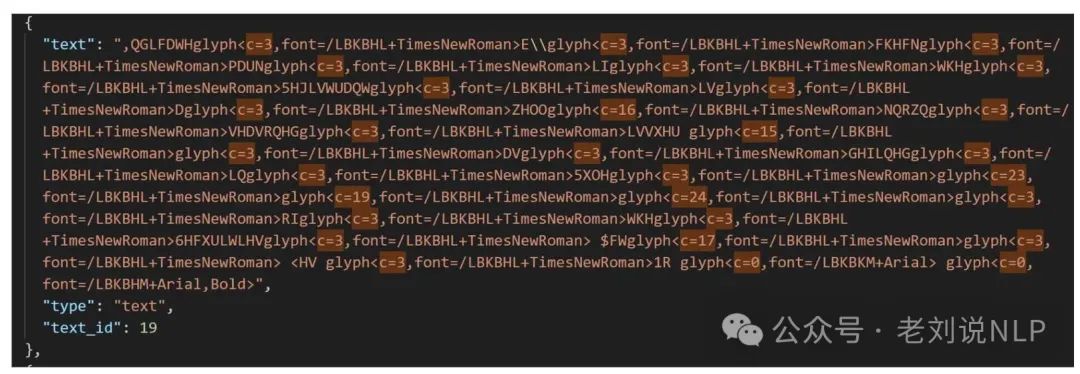
又如,图表部分由图像和部分由文本层组成;一些文档存在字体编码问题,从视觉上看,文本看起来不错,但尝试复制或解析它会导致一组无意义的字符。作者发现,没有任何一个解析器能够处理所有的细微差别,并在不丢失部分重要信息的情况下将PDF内容完整地转换为文本。
实验中使用Docling(https://github.com/DS4SD/docling)进行自定义PDF解析,最终形成一个Markdown文档。这个库速度很快,但仍然不足以在个人笔记本电脑上在2.5小时内解析1.5万个页面。为了解决这个问题,以每小时70美分的价格租用了一台配备4090GPU的虚拟机用于比赛,解析所有100份文档大约需要40分钟。
其中,还包括一些细节问题。
例如,真对PDF中的部分文本解析不正确,包含特定的语法,所以使用了一批包含十几个正则表达式的文本来解决这个问题。

针对表格问题,大型表格中,水平标题通常与垂直标题相距过远,削弱了语义连贯性。LLM在大型表格中难以将度量名称与标题匹配,可能会返回错误的值。所以,序列化表格成为了解决方案,例如 **《Large Language Models (LLMs) on Tabular Data: Prediction, Generation, and Understanding – A Survey》,https://arxiv.org/pdf/2402.17944 **。
序列化的本质是将一个大型表格转换为一组小的、上下文独立的字符串。经过广泛的实验和结构化输出模式,找到了一个解决方案,即使是GPT-4o-mini也能几乎无损地序列化大型表格。最初,以Markdown格式将表格输入LLM,但后来改用HTML格式(这在这里证明很有用)。语言模型更容易理解它,而且它允许描述带有合并单元格、子标题和其他结构复杂性的表格。
例如,要回答“2021 年公司股东权益是多少?”这样的问题,只需向 LLM 提供一句话就足够了,而不需要提供包含大量“噪音”的大型结构。
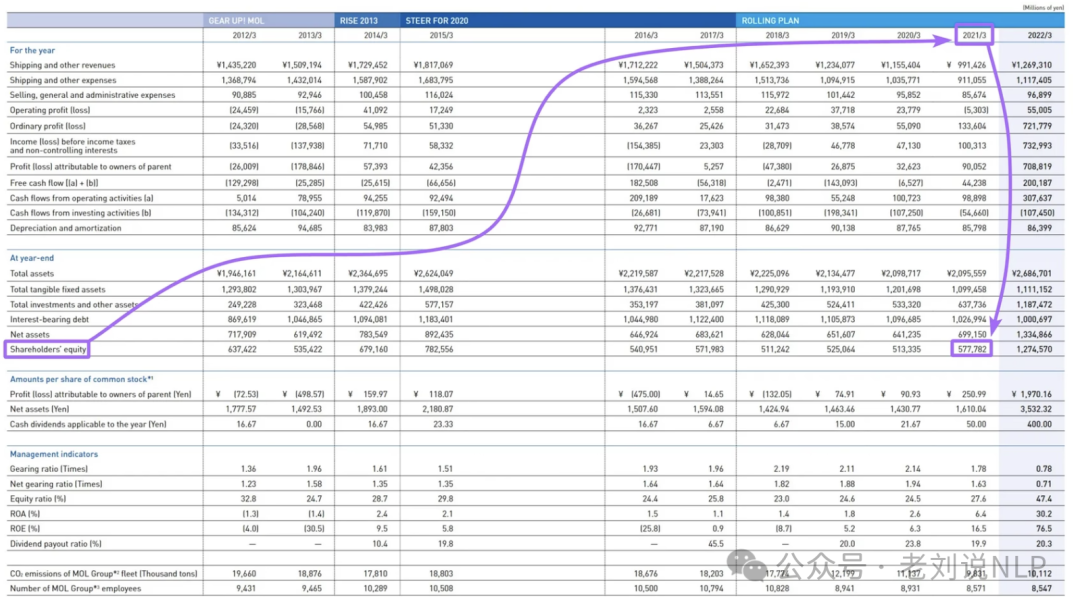
在序列化过程中,整个表被转换成一组这样的独立块:

具体操作在:https://github.com/IlyaRice/RAG-Challenge-2/blob/3ed9a2a7453420ed96cfc48939ea42d47a5f7b1c/src/tables_serialization.py#L313-L345
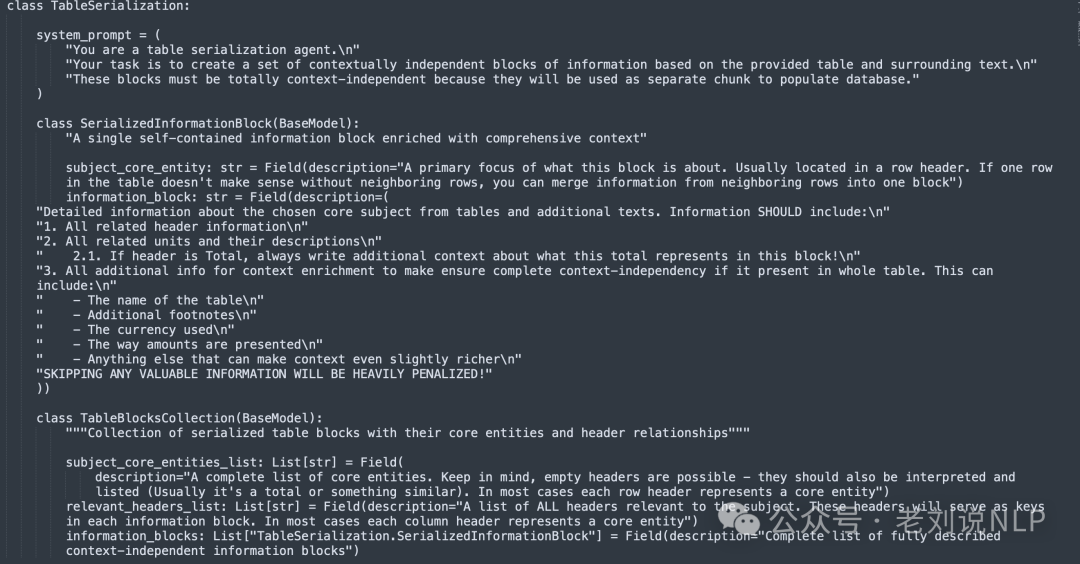
2、分块
将每页的文本分成300个token(大约15个句子)的块。为了对文本进行切片,使用了带有自定义MD词典的递归分割器,为了避免丢失两个块之间的信息,添加了一个小的文本重叠(50个token),每个块在其元数据中存储其ID和父页码。
使用了FAISS(https://github.com/facebookresearch/faiss),索引类型使用IndexFlatIP,其优点是索引的优点在于所有向量都“按原样”存储,无需压缩或量化。搜索使用暴力破解,精度更高,缺点是此类搜索的计算和内存占用显著增加。如果数据库至少有十万个元素,建议考虑IVFFlat或HNSW,这些格式速度更快(尽管创建数据库时需要更多资源),但由于采用了近似最近邻(ANN)搜索,速度的提升是以牺牲准确度为代价的。
为了将块和查询嵌入到向量表示中,使用text-embedding-3-large(https://platform.openai.com/docs/models/text-embedding-3-large)
3、召回检索
有个前提,如果LLM没有在查询上下文中收到必要的信息,它就无法提供正确的答案,无论如何微调解析或答案提示。
一般来说,我们都会混合搜索然后用交叉编码器做重排序。
但是两者有一定问题:
首先,将基于语义向量的搜索与基于关键词的传统文本搜索(BestMatch25)相结合。理论上,它不仅考虑文本的含义,还考虑关键词的精确匹配,从而提高检索准确率。混合搜索是一种很好的技术,可以通过修改输入查询来进一步优化,如LLM可以重新表述问题,以消除噪音并增加关键词密度。通常,两种方法的结果会合并,并根据综合得分重新排序,但是在其最小实现中,它往往会降低检索质量而不是提高检索质量。
使用交叉编码器模型对向量搜索结果进行重新排序可以提供更精确的相似度得分,但速度较慢。交叉编码器介于嵌入模型(双编码器)和LLM之间。与通过向量表示比较文本(这本身会丢失一些信息)不同,交叉编码器直接评估两个文本之间的语义相似性,从而给出更准确的分数。但是,查询与每个数据库元素的成对比较花费的时间太长。因此,跨编码器重新排序仅适用于已经通过向量搜索过滤的一小组块。
所以,在这个方案直接使用LLM进行reranking,如通过GPT-4o-mini重新排序,将文本和问题传递给大模型,并询问:“这段文字对回答问题有帮助吗?有多大帮助?请将其相关性从0到1进行评分。”,制定了一个详细的提示,以0.1的增量描述了一般准则和明确的相关性标准:
0=完全不相关:该块与查询没有任何联系或关系。 0.1=几乎不相关:与查询只有非常轻微或模糊的联系。 0.2=非常轻微相关:包含极其微小或附带的联系。
LM查询以结构化输出格式,包含两个字段:“reasoning”(允许模型解释其判断)和“relevance_score”,允许直接从JSON中提取,无需额外解析。
进一步通过一次性发送三个页面的请求来优化这个过程,提示LLM同时返回三个分数。
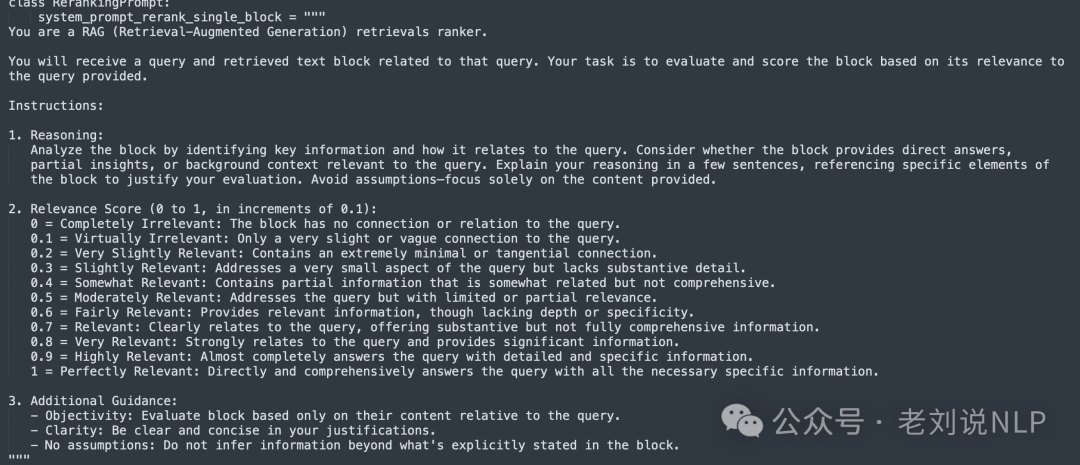
提示在:https://kkgithub.com/IlyaRice/RAG-Challenge-2/blob/3ed9a2a7453420ed96cfc48939ea42d47a5f7b1c/src/prompts.py#L431-L459
然后进行父页面检索,回答所需的核心信息通常集中在一个小块中,这正是将文本分成更小块以提高检索质量的原因。但该页面上的其余文本可能仍然包含次要的但仍然重要的细节。 因此,在找到top_n相关的块之后,只将它们作为指向整页的指针,然后将整页放入上下文中,这正是在每个块的元数据中记录页面编号的原因。
所以,最终的检索方案为:对查询进行向量化->根据查询向量找到最相关的30个块->通过块元数据提取页面(需要去重)->将页面通过LLM重排序器->调整页面的相关性分数->返回最相关的10页,将每页的编号添加到前面,并将它们合并为一个字符串。
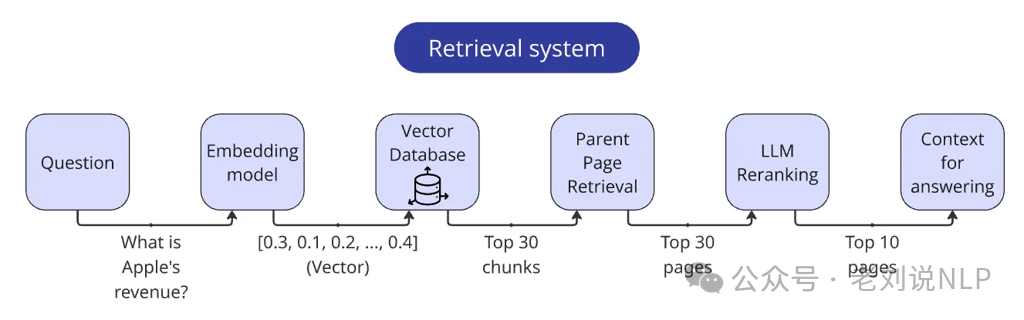
3、增强生成
首先是如何组装提示。
在尝试了多个项目中的不同方法后,将提示存储在一个专门的prompts.py文件中,通常将提示分成逻辑块:核心系统指令;定义LLM期望返回的响应格式的Pydantic模式;用于创建单次/少次提示的示例问答对;插入上下文和查询的模板;将提示分成逻辑块:核心系统指令;
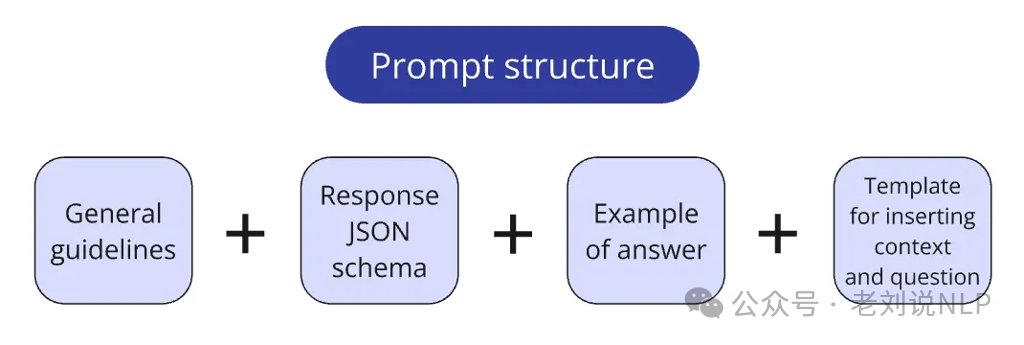
对应的prompt地址在:https://github.com/IlyaRice/RAG-Challenge-2/blob/main/src/prompts.py

其次是如何生成,生成最重要的是路由的设计。如下:
一个是数据库路由:
每份报告都有自己的单独向量数据库。问题生成器被设计成公司名称总是明确地出现在问题中。还有一份所有公司名称的列表(在比赛开始时与PDF报告一起提供)。
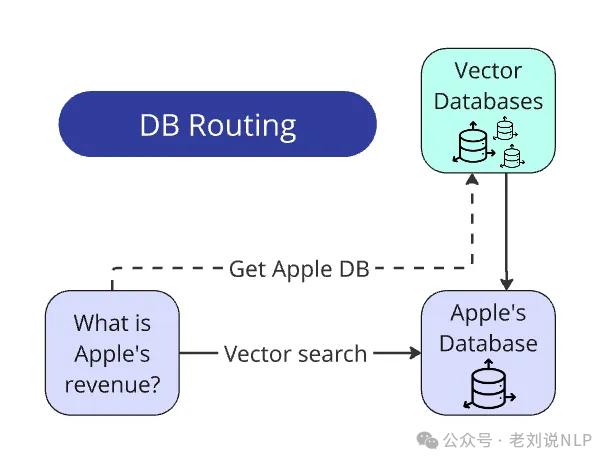
因此,从查询中提取公司名称甚至不需要LLM:只需遍历列表,通过re.search()从问题中提取名称,并将其与相应的数据库匹配。在现实场景中,将查询路由到数据库比在受控、无菌的环境中要复杂得多。很可能,你还有额外的初步任务:标记数据库或使用LLM从问题中提取实体以将其与数据库匹配。
但从概念上讲,方法保持不变。总结起来的路线就是,找到名称→与数据库匹配→只在这个数据库中搜索。搜索空间缩小了100倍。
一个是提示路由:
比赛的一个要求是回答格式。每个回答必须简洁且严格符合数据类型,就好像直接存储到公司的数据库中一样。除了每个问题,还明确给出了期望的类型——int/float、bool、str或liststr。
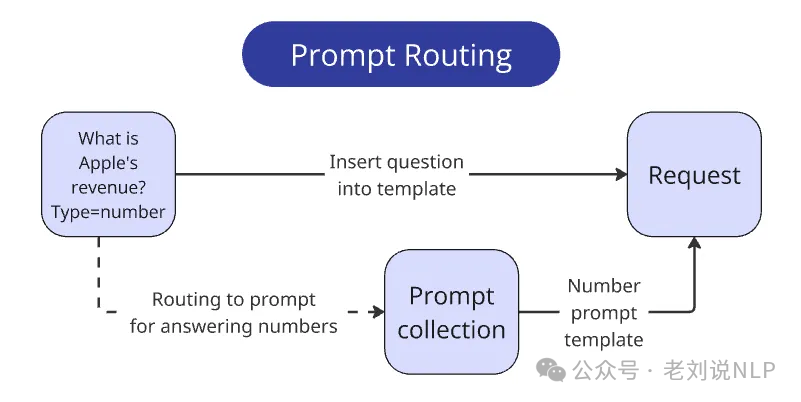
所以,每种类型在回答时都涉及3-6个需要考虑的细微差别。所以根据不同的问题设计不同的提示词。
例如:

一个是复合查询路由:
比赛包括比较多个公司度量值的问题。这类问题不符合其他简单查询的范式,因为它们需要额外的步骤来回答。例如,对于示例问题:谁的收入更高,苹果还是微软?为了回答这个问题,会分别找到每个公司的收入,然后进行比较。在实际处理中,将最初的比较问题传递给LLM,并要求它创建更简单的子问题,分别提取每个公司的度量值。
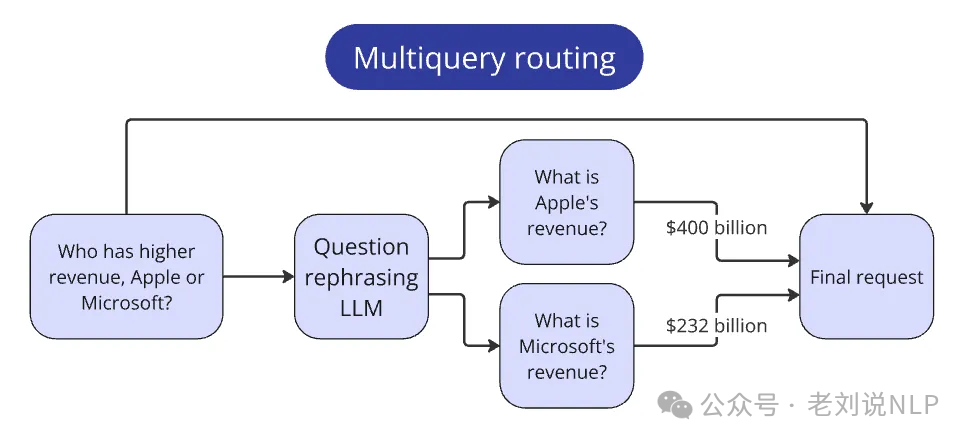
例如,更简单的子问题是:苹果的收入是多少?和微软的收入是多少?然后,可以分别通过每个公司的标准流程处理这些更简单的查询;在收集了每个公司的答案之后,将它们传递到上下文中以回答原始问题。这种模式适用于任何复杂查询。关键是识别它们并确定必要的子步骤,所以使用了思维链提示,但其中更重要的是给出一些示例。例如:
问题:
Ritter Pharmaceuticals, Inc.的研发设备成本是多少? 模型的推理步骤:
问题询问的是Ritter Pharmaceuticals, Inc.的“研发设备成本”。这表明这是一个特定的资产负债表上的值,代表专门用于研发的设备的_原始购买价格_,_不_包括任何累计折旧。
上下文(第35页)显示“固定资产净额”为12500美元。这是一个_净_值(折旧后),并且它是一个_更广泛的_类别,涵盖了所有固定资产,而不仅仅是研发设备。
上下文(第37页)还提到了“机器和设备”的“累计折旧”为110000美元。这代表了总_折旧_,而不是原始成本,并且,重要的是,它没有指定这些设备是_专门_用于研发的。
这些度量值中没有一个_完全_匹配请求的度量值。“固定资产净额”太宽泛了,它代表的是折旧后的价值。“累计折旧”只显示了折旧,而不是成本,并且缺乏研发的特定性。
由于上下文没有提供_仅_研发设备的_原始成本_,并且我们不能进行假设、计算或将信息结合起来,答案是“N/A”。
最后,为了让大模型能够正确输出json格式,所以使用Pydantic模式。使用此模式,LLM始终返回具有两个字段的JSON——第一个字段是字符串,第二个字段是数字。

回答竞赛问题的主要模式中,只有四个字段:step_by_step_analysis—初步推理(思路链本身);reasoning_summary—前一个字段的简要摘要(为了更容易跟踪模型的逻辑);relevant_pages—报告答案引用的页码;final_answer—按照比赛要求格式化的简洁答案。
参考文献
1、https://abdullin.com/erc/
2、https://github.com/trustbit/enterprise-rag-challenge/tree/main
3、https://github.com/IlyaRice/RAG-Challenge-2
(文:老刘说NLP)