


这不是普通的AI测评工具,而是一场真正的网络寻宝大挑战!
BrowseComp这名字听着就霸气,直译过来就是「浏览竞赛」,像是给AI们办了场互联网淘金比赛。
OpenAI这次拿出了1266个超硬核问题作为测试基准,看看各家AI到底能不能在茫茫网海中找到那根针。
这项新基准测试已经在OpenAI的简单评估GitHub仓库中开放,任何人都可以使用它来测试自家AI的网络浏览能力。
仓库地址:https://github.com/openai/simple-evals
这些问题有多难?
据说连人类训练师都被虐哭了!
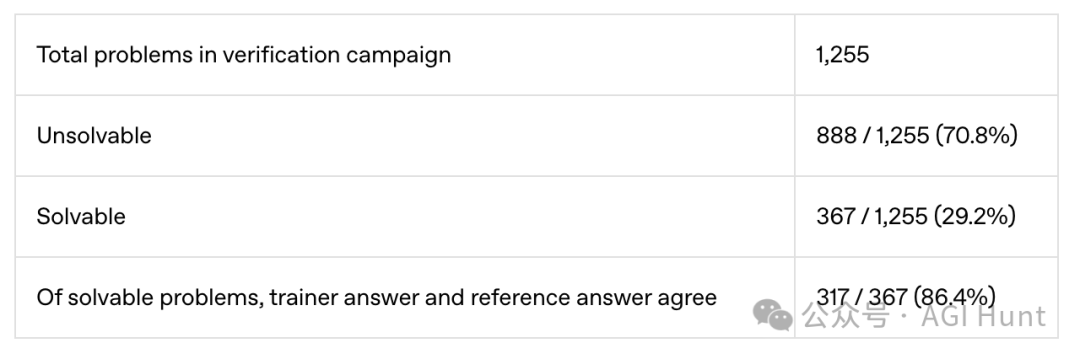
大部分人在给定两小时的情况下,70.8%的问题都解决不了!那些能解决的问题中,人类答案与参考答案的匹配率也只有86.4%。

来看几个例子就明白了:
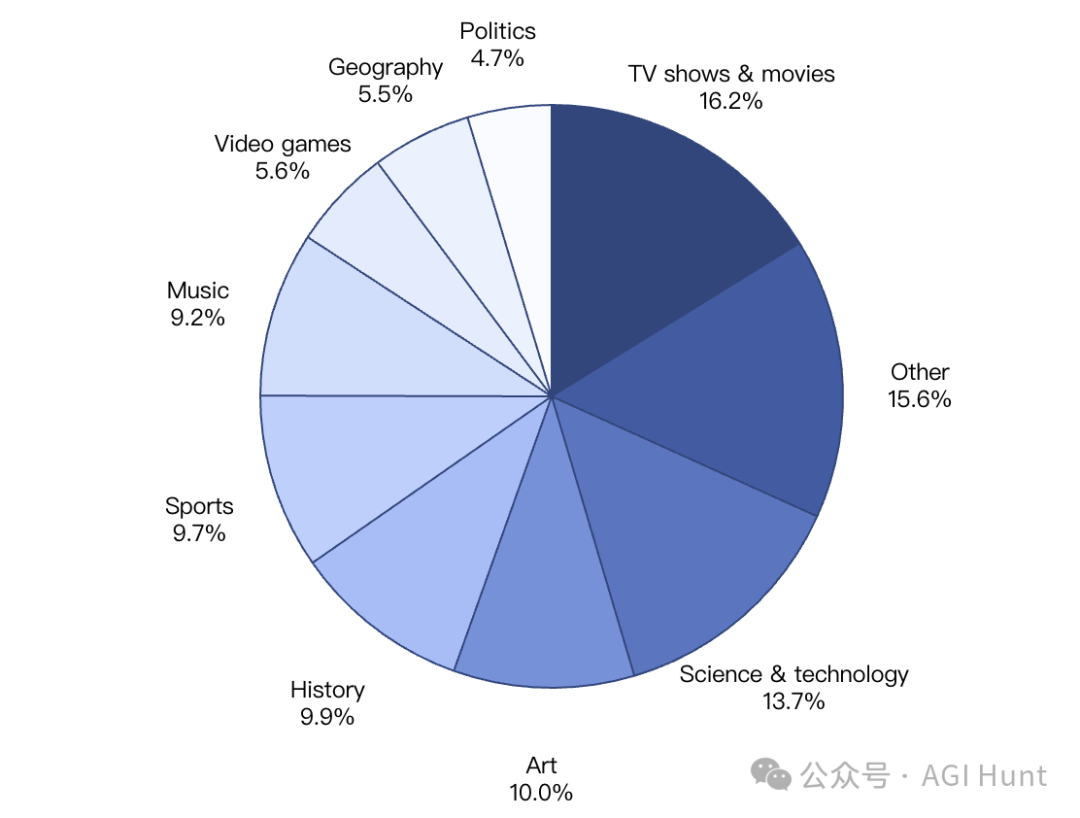
「请找出1990年至1994年期间,由巴西裁判执法、每队各有两张黄牌(共四张,其中三张不是在上半场出示的),有四次换人(其中一次是因为比赛前25分钟内的伤病)的足球比赛中的参赛队伍。」
答案:爱尔兰vs罗马尼亚
这种问题光靠脑力根本解不开,普通搜索更是无效,得层层深入、多方交叉验证,才能锁定答案。
Lukas Bug(@BugLukas)回应称:「不错,我们确实需要更多基准测试来衡量LLM在不同用途上的表现!」
普通模型全军覆没!
当各种模型在这场硬仗中交锋,成绩单简直惨不忍睹:

-
GPT-4o:0.6%
-
GPT-4o配浏览功能:1.9%
-
GPT-4.5:0.9%
-
OpenAI o1:9.9%
-
Deep Research:51.5%
看看这是什么水平……就算是强如GPT-4o,加了浏览功能也才解决不到2%的问题!
这可不是普通的难,而是地狱级难度啊!
这种惨淡表现凸显了BrowseComp的挑战性:没有强大的推理能力和工具使用能力,模型根本无法定位BrowseComp所针对的那种晦涩、多跳的事实。
而专门训练用于持续网页浏览的Deep Research模型则表现亮眼,解决了大约一半的问题。
这表明工具使用和推理能力对BrowseComp的性能都有意义的贡献。
BrowseComp为什么如此重要?
现有的基准测试像SimpleQA,只测量模型检索基本孤立事实的能力,对于配备快速浏览工具的模型来说已经饱和了。
但真实世界中,我们需要AI能够找到那些难以获取、相互纠缠的信息。
用Thomas Kennedy(@ThomasK72379118)的话说:
「从根本上讲,我们需要在实际使用中进行测试,了解我们的模型如何应用于日常问题解决。我认为市场本身,无论是消费者还是商业目的,都是最好的测试」
BrowseComp评估AI代理浏览网络搜索难以找到信息的能力。
虽然它并不评估常见查询的性能,但它测量了找到单个目标信息的能力,易于评估,并且对现有浏览代理具有挑战性。
AI如何突破搜索瓶颈?
BrowseComp的魔力在于它采用了一种「逆向问题设计方法」——从特定的、可验证的事实开始,构建一个通过复杂性来掩盖答案的问题。
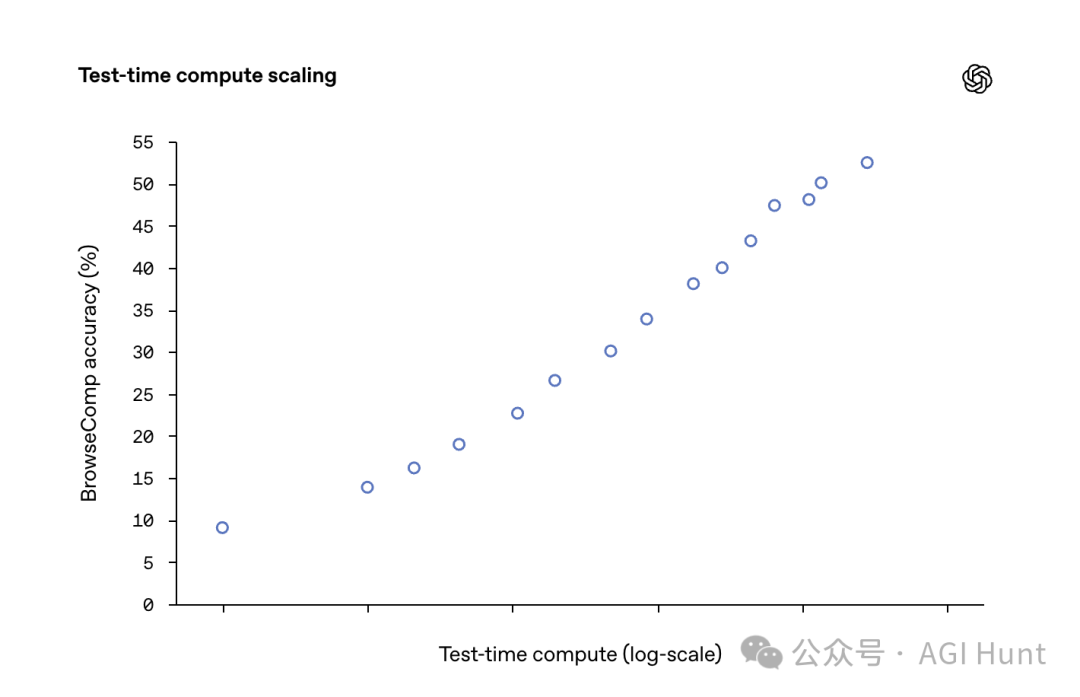
一个关键特性是代理的性能会随着推理时使用的计算量而扩展。
也就是说,给AI更多的算力和时间,它就能探索更多网站,组合更多信息,成功率也就更高。
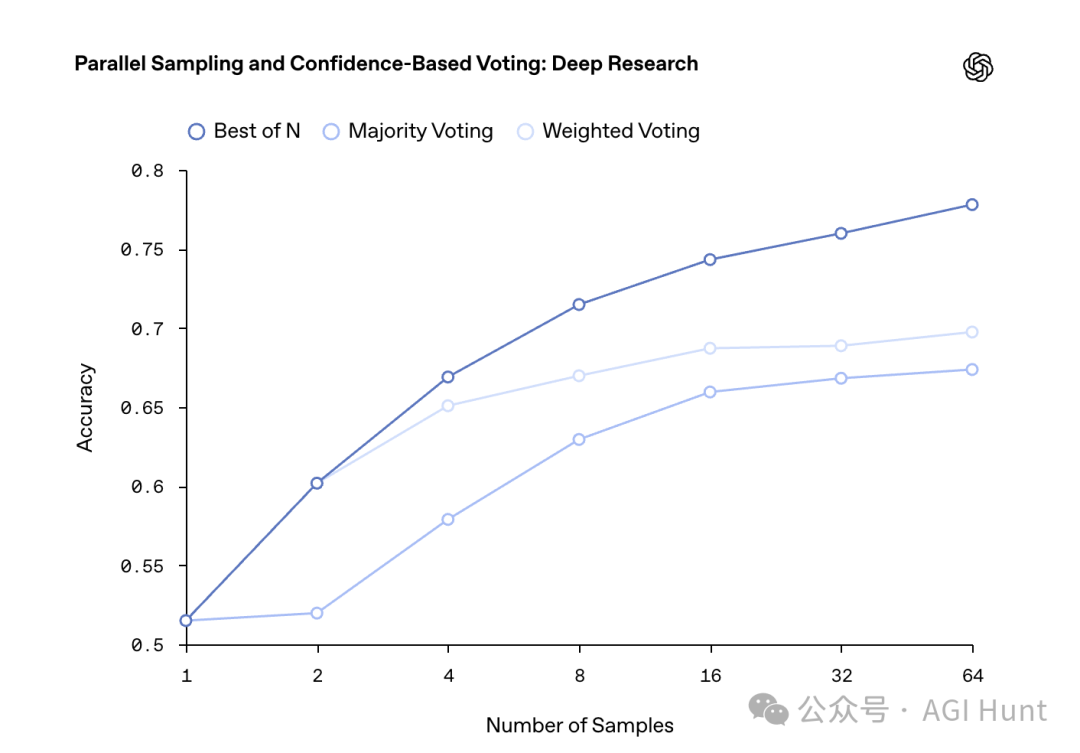
另一个重要发现是,如果让Deep Research模型尝试每个问题多次,并使用各种策略选择最佳答案,其性能可以提高15%到25%。
这说明模型经常“知道”什么时候它是正确的!
这就像是一个侦探在搜集线索后,对自己的结论有多大把握是心里有数的。
人类vs AI:谁才是高手?
数据显示,人类训练师在BrowseComp任务上的表现也相当差强人意。
大多数人即使给予两小时的搜索时间,也无法解决大部分任务,这反映了任务的困难程度。
有些问题人类确实能解决,但往往需要在搜索上花费大量时间——有些问题可能需要不到一小时就能解决,而许多问题只有在花费两三个小时的研究后才能解决。
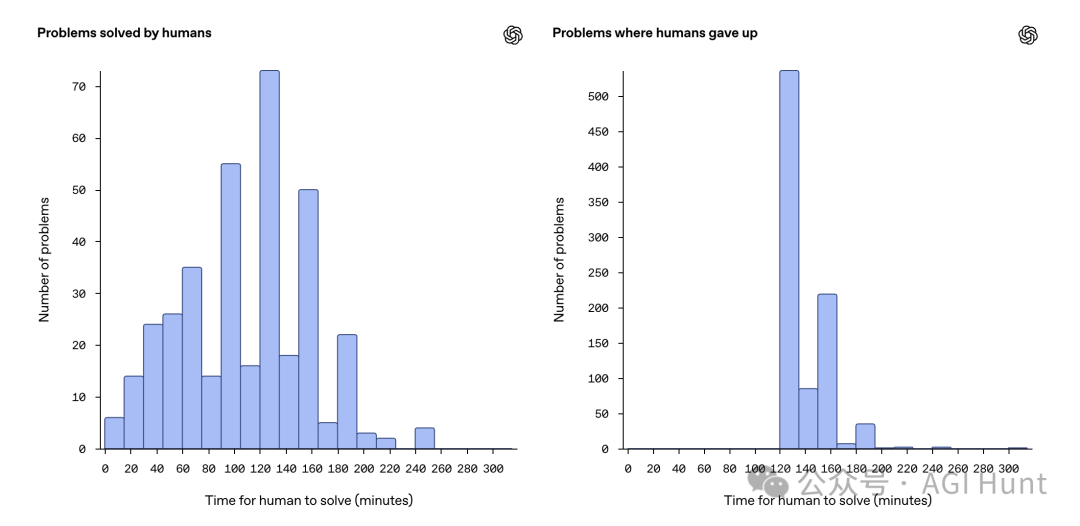
对于无法解决的问题,绝大多数训练师在尝试问题大约两小时后就决定放弃。
这进一步证明了这些问题不是简单的浏览任务,而是需要持久性、结构化推理和动态调整搜索策略的复杂挑战。
未来的AI搜索
我想,BrowseComp的出现可能会推动几个方面的发展:
1️⃣ AI浏览代理会更加注重持久性
未来的AI不会轻易放弃,它们会像优秀的侦探一样,持续探索各种可能路径,直到找到答案。
2️⃣ 结合工具使用和推理能力将成为关键
单纯的浏览能力或推理能力都不足以解决复杂问题,两者结合才是王道。
OpenAI o1虽然没有浏览能力,但其强大的推理能力让它的表现明显优于仅有浏览功能的GPT-4o。
3️⃣ 计算资源的优化将更加重要
能够在有限的计算资源内最大化性能将成为AI代理的竞争优势,特别是在处理那些需要浏览大量网站的任务时。
作为开源项目,BrowseComp给了研究人员一个标准工具来评估和改进AI代理的浏览能力。
这项基准测试的公开也将推动更可信、更可靠的AI研究。
看来AI们的「网上冲浪」技能还有很长的路要走。
不过既然人类也被这些问题虐得够呛,暂时还不用担心AI完全取代我们的搜索能力。
对于开发者和研究人员来说,BrowseComp无疑是一个激动人心的新挑战和研究方向!
(文:AGI Hunt)