


随着人工智能技术的飞速发展,图像到视频(I2V)生成已成为艺术与科技融合的前沿领域。然而,现有方法在将静态绘画转化为动态视频时,仍面临两大核心挑战:
(1)不动:现有模型无法准确解读和执行文本提示中的运动指令,导致生成的视频缺乏动态效果或完全静止;
(2)乱动:模型在尝试赋予静态绘画动态效果的过程中,可能会出现与原作品风格不符或破坏其完整性的现象。
针对上述难题,西安交通大学、合肥工业大学以及澳门大学的研究团队联合提出一个零训练图像转视频框架——“Every Painting Awakened”,成功实现静态绘画的动态化生成。
该技术不仅能让静态油画根据提示文本动起来,更可精准保持原画笔触的微妙渐变,解决了艺术动画领域长期存在的动态失真与风格偏离两大难题。

论文标题:
Every Painting Awakened: A Training-free Framework for Painting-to-Animation Generation
论文链接:
https://arxiv.org/abs/2503.23736
项目主页:
https://painting-animation.github.io/animation/


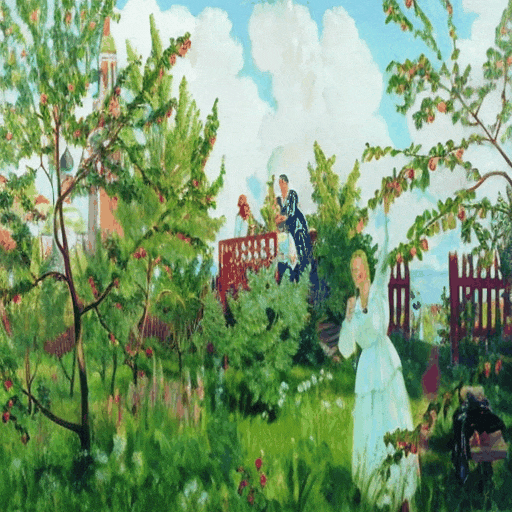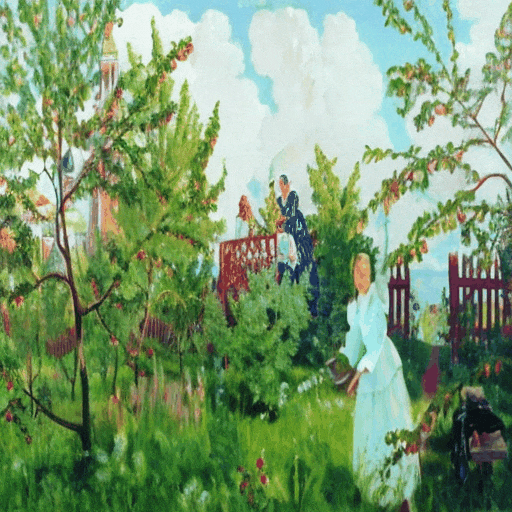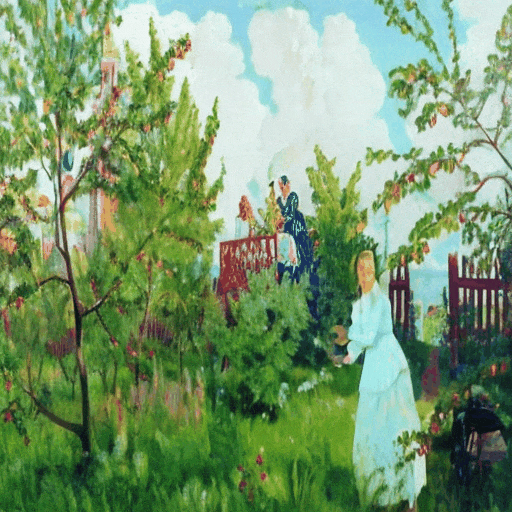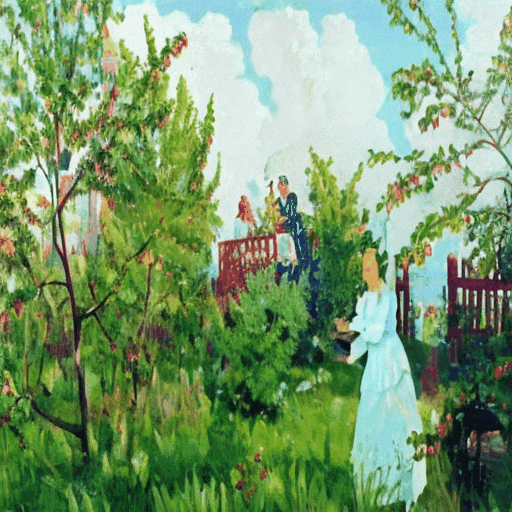
▲ Every Painting Awakened 示例

从静态到动态:艺术动画的终极挑战
“Every Painting Awakened” 创新性地引入双路径分数蒸馏技术与混合潜在融合机制,突破性实现:
-
动态精准控制:通过预训练图像模型的文本-图像对齐能力,将文本提示编码进图像域空间。
-
风格完美继承:在潜在空间进行球面线性插值,确保动态化过程不损伤原作色彩、笔触等艺术特征。
-
即插即用部署:无需额外训练,可直接增强现有 I2V 模型。

核心技术解析
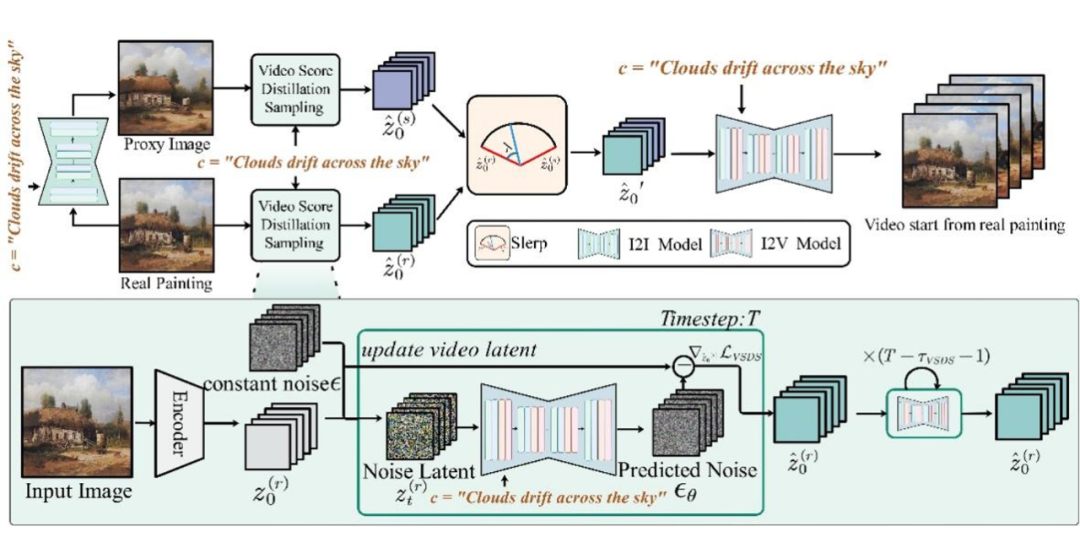
▲ Every Painting Awakened 架构
“Every Painting Awakened” 框架首先应用一个预先训练的图像模型从真实绘画中生成一个代理图像,代理图像作为后续步骤的未来指导。随后将双路径分数蒸馏采样应用于真实绘画和代理图像,得到两个更新的初始视频潜在向量。
这两个向量沿时间维度进行球形插值,以生成融合的潜在向量。该融合向量被用作 I2V 模型的输入,用于视频生成。
框架的核心技术主要集中在两个方面:
1. 双路径得分蒸馏(Dual-path Score Distillation)
问题:静态绘画缺乏动态数据支撑,模型难以捕捉运动规律。
方案:构建双路径架构,从代理图像中提取动态先验,同时从真实绘画中保留原画静态细节。
效果:既保证画作风格的完整性,又为动态生成提供运动逻辑支持。
2. 混合潜在融合(Hybrid Latent Fusion)
问题:动态生成过程中,画面过渡生硬或风格断裂。
方案:在潜在空间中通过球面线性插值(Slerp)融合真实绘画特征与代理图像的动态特征。
效果:实现自然流畅的时序过渡,确保动态与静态元素的和谐统一。

实验结果
研究显示,“Every Painting Awakened”不仅能够大幅提升与文本提示语义上的契合度,同时也能忠实地保留原绘画的独特风格和完整性。
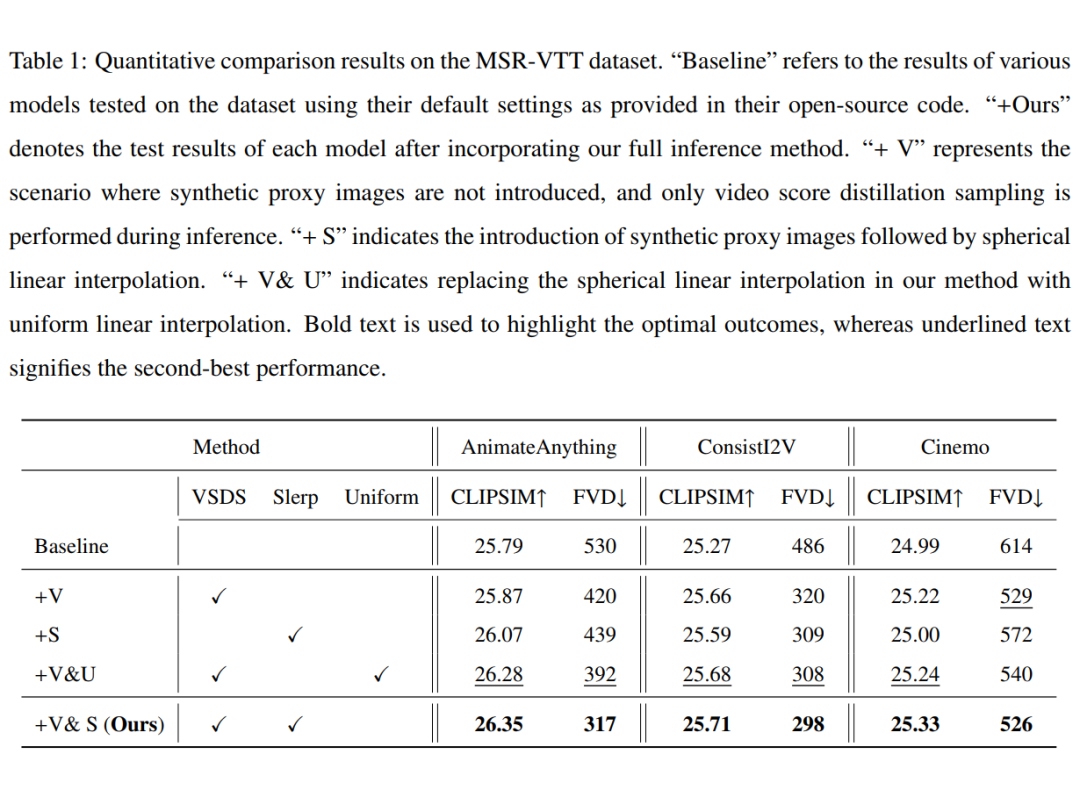
▲ 在各 I2V 基础模型上的评估结果和消融实验结果

▲ AnimateAnything 模型上的示例

▲ ConsistI2V 模型上的示例

▲ Cinemo 模型上的示例

总结与未来方向
“Every Painting Awakened” 框架为数字艺术、影视特效等领域提供了高效工具。例如,博物馆可将经典画作转化为动态展览。当静态艺术遇上动态 AI,技术与美学的边界再次被突破。
这项研究不仅让静态绘画“活”了起来,更以零训练成本的优势,为创意产业注入新动能。未来,研究将探索复杂场景推理优化,进一步提升长视频生成的连贯性。

(文:PaperWeekly)