



论文标题:
Improving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
期刊/会议:
ICLR 2025
论文地址:
https://arxiv.org/pdf/2503.13208
作者机构:
阿里云智能-飞天实验室

引言
大语言模型(LLMs)可以通过 “思维链(Chain-of-Thought, CoT)” 来解决复杂的推理问题,但对于不同类型的任务,往往需要人工设计的 “提示(prompt)” 来引导 LLMs 进行有效的推理思考。
这些提示,就像是老师在学生解题时给予的微妙提示,能够激发学生的思考,帮助他们找到问题解决的钥匙。
Prompt tuning 通过微调的方法习得这个任务的 Soft Prompt。传统的 Prompt Tuning 方法虽然在常规任务中表现出色,但在复杂推理任务中效果有限,甚至可能降低模型性能。从个体实例的角度来看,soft prompt 对某些实例可能带来正面影响,但对其他实例可能产生负面作用。
如图 1 所示,模型在没有 soft prompt 的情况下可以正确作答,而 soft prompt 可能通过中间推理步骤引导其得出错误答案。因此,判断 soft prompt 对推理的影响是积极还是消极至关重要。然而,理解为何某些推理成功而另一些失败仍然具有挑战性。
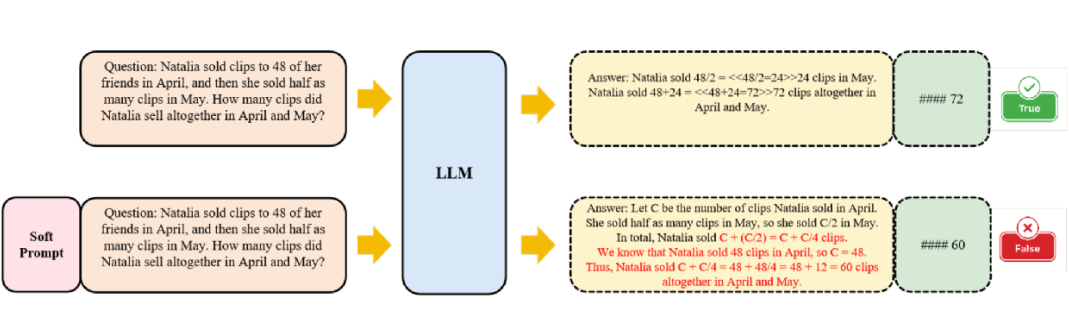
▲ 图1:输入相同的问题以引导 LLM 作答。模型本可正确回答,但在添加 Soft prompt 后,其推理出现错误。

问题分析
如何解构 Soft Prompt 的在推理中的机理,以判断具体影响?问题的核心在于,判断 soft prompt 在何时会引导正确的推理,而何时会失败。这需要深入分析模型的内部工作机制,包括信息如何在模型的不同层和不同组成之间流动,以及这些流动如何影响最终的推理结果。
研究者将模型的 CoT 推理过程的三个关键部分 Soft Prompt,Question,Rationale,以分析其中的交互关系。具体而言,文章采用了一种基于显著性分数(saliency score)的方法来分析信息流,这种方法可以帮助分析模型在处理语言任务时是如何在不同组件间传递和处理信息的。
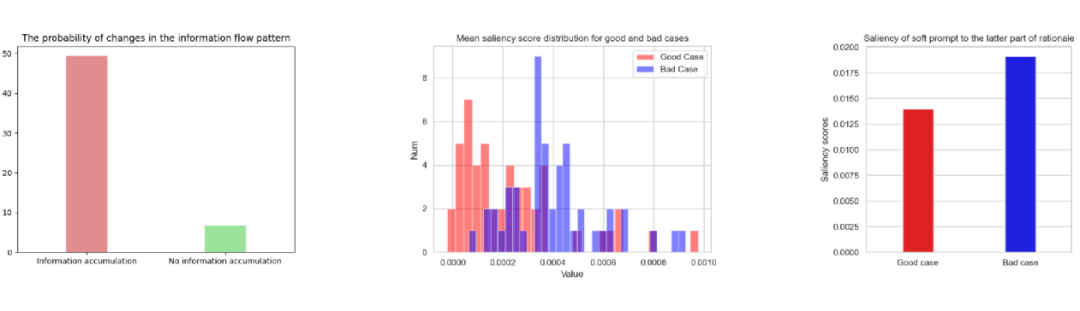
如图2所示,显著矩阵通过将注意力矩阵与损失函数进行 hardmark 积得到:
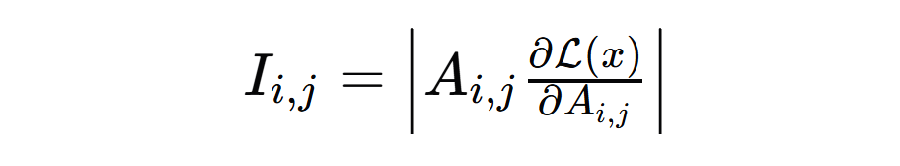
通过结合梯度与注意力值的显著分数,可以评估(SP,Q,R)三者之间的交互关系及其对输出的影响,从而揭示信息流动的机制。帮助理解模型在推理过程中如何依赖输入的不同部分。
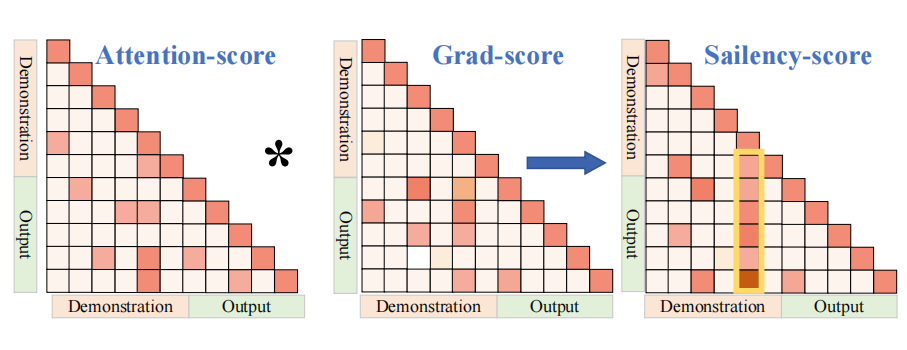
▲ 图2:输入相同的问题以引导 LLM 作答。模型本可正确回答,但在添加 Soft prompt 后,其推理出现错误。
通过度量了如下的信息流动,包括:
1. 软提示到问题(Soft prompt-to-Question):这⼀路径反映了软提示中的知识信息如何被聚合到问题中的
2. 软提示到推理(Soft prompt-to-Rationale):这⼀路径揭示了软提示如何影响推理步骤:
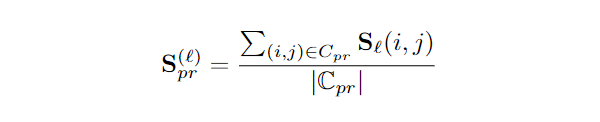
如图 3 左所示,通过可视化各层的显著性分数,揭示了提示信息如何流向问题和论证部分。最强的影响发生在浅层网络中,特别是在第 2 到第 10 层之间,此时软提示信息的聚集最为密集。
为了进一步理解这一现象,需要对这些层级中的信息流动进行精细分析。如图 3 右,浅层的显著性矩阵显示,某些 soft tokens 对推理过程产生了显著的影响,这表明它们在塑造模型输出方面发挥着关键作用。研究者把这种显著性矩阵中的列状现象,称为信息堆积。
▲ 图3:左图展示了软提示到问题及软提示到推理的逐层显著性分数。右图则揭示了软提示中信息的显著堆积现象,其中某个特定 token 对问题和推理均产生了强烈影响。
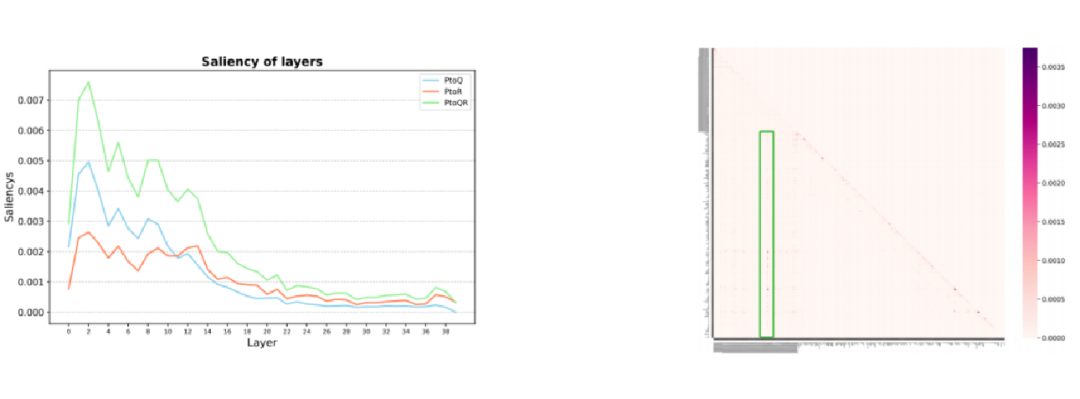
如图 4 所示,通过大量实例分析发现,正确案例与错误案例在处理机制上呈现显著差异:正确案例在浅层阶段能够保持信息提取的平衡性,避免关键信息的遗漏或冗余;而深层推理时则主动将注意力聚焦于早期推理的关键步骤与核心问题,最终提升结果的准确性。
相比之下,错误案例往往在浅层阶段因信息堆积导致冗余特征过度集中,这种现象会干扰模型深层正常信息流动,迫使模型在深层推理时过度依赖预设的 Soft prompt 进行补偿性推理,最终引发输出偏差。这种处理模式的差异直接导致了结果的准确性差异。
▲ 图4:正确答案(左)表现出平衡的注意力分布,从软提示逐步转向推理过程和问题本身。错误答案(右)则呈现浅层注意力过度堆积和深层信息流紊乱,最终导致错误。
通过对于正负样本实例的分析,发现浅层和深层的存在不同的信息流动模式。并且之间的关联性可以能的影响最终的推理。因此接下来着重探究了以下两个问题,来进一步验证信息堆积对于最终推理的影响:
信息积累与信息流模式变化的关系是什么?
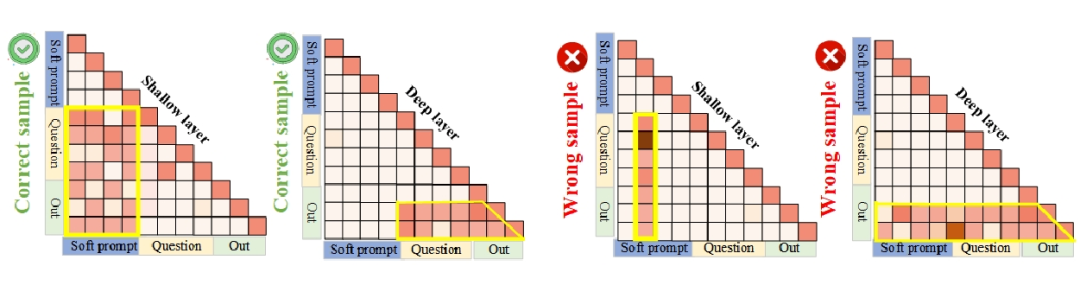
如图 5 左所示,通过计算显著性分数,分析了信息堆积与深层信息流变化的相关性。在采样的 100 个案例中,在浅层出现信息堆积时,深层信息流模式发生变化的概率明显高于未观察到信息积累的情况,这表明信息堆积的出现与深层信息流模式的变化之间存在强相关性。
信息积累与信息流模式变化的关系是什么?
如图五右所示,分析了 50 个正确案例和 50 个错误案例。答案正确的实例中,深层的推理 token 对 soft prompt token 的关注程度较低;而在错误答案的实例中,soft prompt token 对深层的推理 token 的影响更大。
当模型在深层时更多地依赖早期步骤(如问题本身或初步推理)而非 soft prompt 时,更可能得到正确答案;相反,深层时受到 soft prompt 显著影响时,模型可能会出现错误答案。
▲ 图5:左图展示了浅层信息积累与深层信息流变化之间的关系,中间图呈现了正确与错误案例中从软提示到后续推理步骤的信息流强度差异,右图则对比了二者整体信息流强度的差别。
2.2 Dynamic Prompt Corruption
基于上述的分析验证,本文提出了动态提示扰动的方法(DPC),通过检测软提示中的信息堆积,识别错误的信息流模式。
基于动态触发策略,它可以确定受影响的推理过程,并定位对干扰影响最大的软提示 token。为缓解错误,DPC 通过屏蔽已定位的 token 的嵌入值来实施定向扰动,有效缓解有害堆积的负面影响。
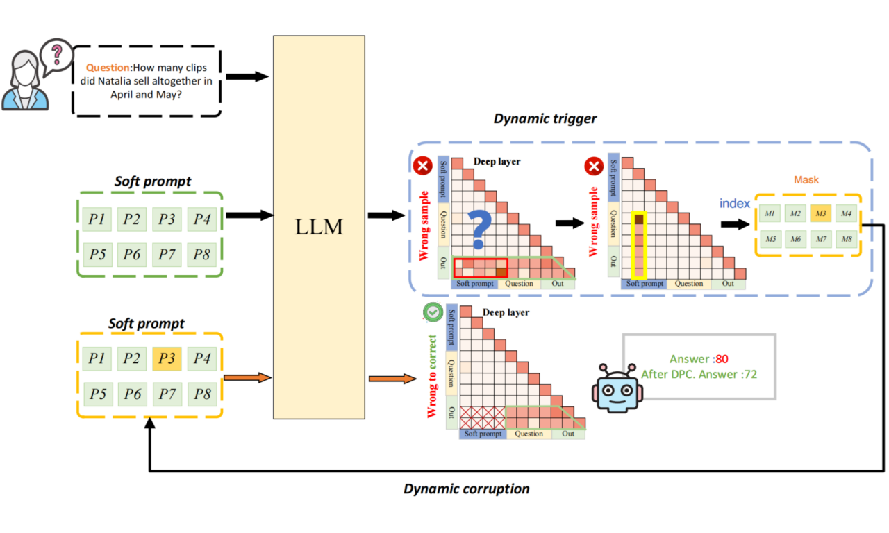
▲ 图6:动态提示扰动(DPC)通过识别错误的信息流模式,并在信息堆积点有针对性地扰动软提示 token,从而缓解其负面影响。
2.3 实验结果
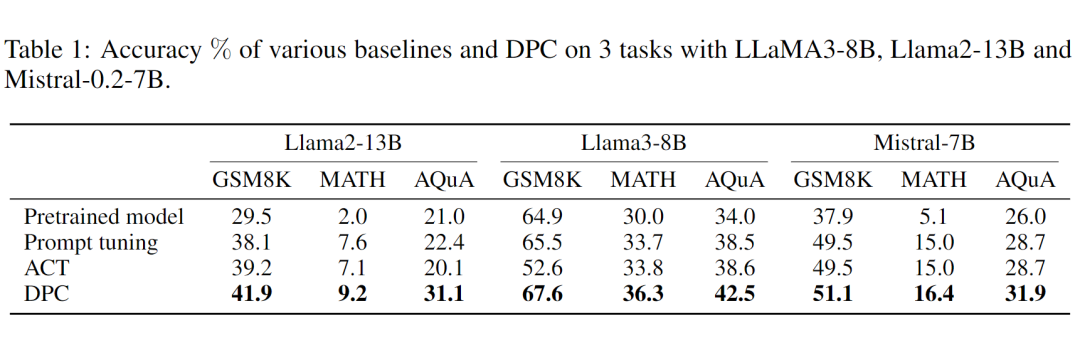
研究者们对不同的模型(如 LLaMA-2-13B,LLaMA-3-8B, Mistral-7B)进行了较为全面的测试,涉及多种不同复杂推理数据集。结果显示,DPC 方法在 prompt tuning 的 scope 中有了一致性的提升。

主要贡献
-
本文通过显著性分数分析软提示,问题和推理过程之间的相互作用,探讨了软提示信息积累对错误推理的影响。研究发现,更深的软提示影响会增加答案错误的可能性。
-
提出了一种基于信息流分析结果的动态提示扰动(DPC),这是一种实例级提示调整策略,能够动态缓解软提示的负面影响。
-
通过在不同 LLMs 和 数据集上的大量实验验证了 DPC 在复杂推理任务上显著优于基础提示调优,突显了其有效性和优越性。

结论与展望
通过基于 Saliency 的信息流分析发现,当soft prompt 深刻影响推理的后期阶段时,模型更有可能得出错误答案。提出了 DPC,能够实例级动态识别并减轻由 soft prompt 引起的负面影响。未来可以进⼀步利用该分析方案应用于其他领域。
(文:PaperWeekly)