

作者|子川
来源|AI先锋官
原来AI圈也有自己的汪峰!
昨天DeepSeek前脚刚发布新版本DeepSeek-V3-0324,后脚阿里云通义千问开源了视觉理解模型Qwen2.5-VL-32B-Instruc。

结果也如大家看到的那样,热度全跑到DeepSeek那里去了。
相关阅读:火线实测: DeepSeek V3重新定义“小更新”,编码能力比肩Claude3.7 超 R1
在此之前,开源家族视觉语言模型Qwen2.5-VL系列已经有3B、7B和72B三种尺寸。
而此次发布Qwen2.5-VL-32B正好解决了一个痛点:7B太小,72B又太大,用来部署本地正正好。
虽然32B比72B尺寸小上不少,但能力却丝毫不差。
在公布的测试成绩中,Qwen2.5-VL-32B-Instruct 明显要优于同规模的 Mistral-Small-3.1-24B、Gemma-3-27B-IT 模型,甚至在某些方面超越了更大规模的 72B 模型。
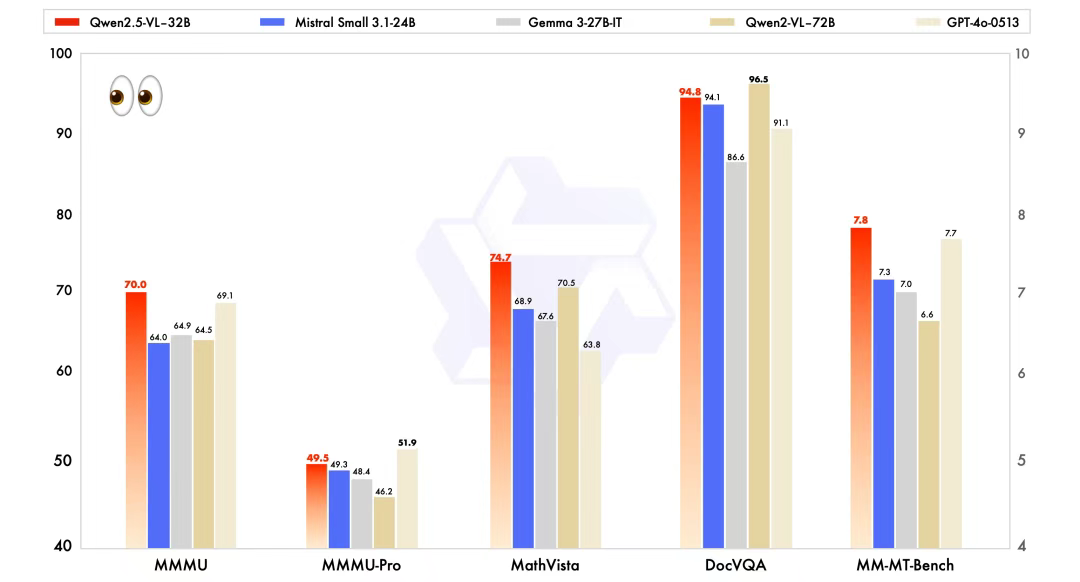
据了解,相较于此前的 Qwen2.5-VL 系列模型,32B 模型有三点显著的改进:
-
回复更符合人类主观偏好:调整了输出风格,使回答更加详细、格式更规范,并更符合人类偏好。
-
数学推理能力:复杂数学问题求解的准确性显著提升。
-
图像细粒度理解与推理:在图像解析、内容识别以及视觉逻辑推导等任务中表现出更强的准确性和细粒度分析能力。
那它的实际效果到底如何呢,我们来实际测试一波。
扔给它一张高速限速图,并问Qwen2.5-VL-32B:我开着一辆卡车在这条路上行驶,现在是 12 点,我能在 13 点之前到达 110 公里外的地方吗?

它的回答是这样的——

Qwen2.5-VL-32B结合图片上的限速规则,并通过计算,给出了“不能”的答案。
面对较难的看图猜成语问题,Qwen2.5-VL-32B也能轻松拿捏。

不过面对一些较难猜的成语,也有翻车的时候。

Qwen2.5-VL-32B把“两面三刀”猜成了“面面俱到”。
那Qwen2.5-VL-32B的实力到底如何呢?在同尺寸模型中是否具有领先的优势呢?下面我们来对比一下。
此次用于测试的就是前段日子Google发布的Gemma 3 27B,毕竟尺寸差不多,而且都是主打的在本地部署这条赛道。
测试题一:一根8米长的竹竿是否能通过一个4米高、2米宽的门?
Qwen2.5-VL-32B:

Gemma 3 27B:

不愧是现在模型测试专用题,都没有回答出来,这道题确实有点难,此前DeepSeek R1、o1等模型都在这道题栽跟头了。
那就来一道中等的计算题来难为一下它们。
测试题二:你和朋友轮流从一堆金币中取1、3或6枚。获胜者是最后取走金币的人。对于N<1000,第一位玩家有多少种赢得游戏的策略?
先公布正确答案:666
Qwen2.5-VL-32B:

Gemma 3 27B:

Qwen2.5-VL-32B回答正确,给出的答案是666,但Gemma 3回答错误了,给出的答案是667,居然多算出一种。
测试题三:如果昨天是明天的话就好了,那么今天就是周五了。请问:实际上,句中的今天可能是周几?
Qwen2.5-VL-32B:

Gemma 3 27B:

呃呃呃…..,两个都回答错误,标准答案是:周日和周三,Qwen2.5-VL-32B只推断出周日,而Gemma 3则是一个没对一个,给出的答案是周六。
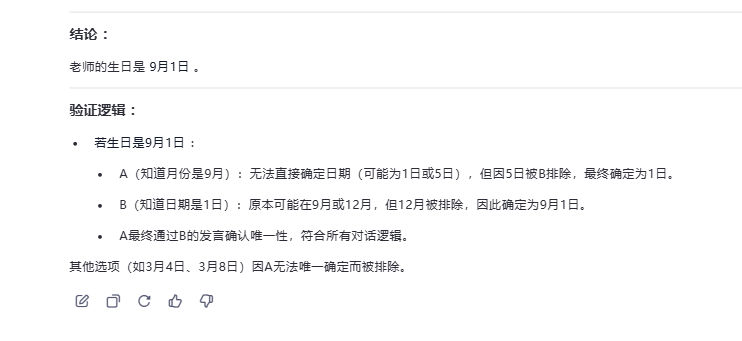
测试题四:猜猜老师的生日
题目:老师告诉学生自己的生日是以下日期之一:3月4日、3月5日、3月8日、6月4日、6月7日、9月1日、9月5日、12月1日、12月2日、12月8日。老师只告诉了A月份,告诉了B日期。A说:“我不知道老师的生日,但B肯定也不知道。” B说:“我本来也不知道,但现在我知道了。” A说:“那我也知道了。” 请问老师的生日是哪一天?
Qwen2.5-VL-32B:

(文:AI先锋官)