


当 GPT-4o 在高考考场游刃有余,当 DeepSeek 对千年历史人物如数家珍,一个震撼人心的猜想正冲击着整个 AI 界:这些大语言模型是否已悄然孕育出超越人类的“超级智能”?
在认知科学的定义里,智能系统可分为两个层级:晶体智能(crystallized intelligence)与流体智能(fluid intelligence)。最新研究证实,大型语言模型在晶体智能维度已展现出碾压级表现:只要任务 T 的特定知识(无论是标注数据还是海量语料)曾映入它们的’数字视网膜’,解题就如同探囊取物。
但是,当面对完全陌生的任务时,这些大模型能否像人类一样举一反三?在毫无先验知识的’认知真空’中,它们能否迸发真正的思维火花?
最新流体智能评估研究揭示,主流 LLM 在此维度存在显著能力缺陷。本研究选取 Keras 之父提出的的 ARC(The Abstraction and Reasoning Challenge)任务作为实验基准,系统揭示了当前 LLM 在流体智能场景下的三大核心瓶颈:
1. 组合泛化局限:模型难以将已习得的基础概念进行新颖组合迁移
2. 抽象表征障碍:对非具象化输入模式的语义理解存在显著偏差
3. 架构性约束:其自左向右的解码机制导致了内在缺陷。

论文题目:
Understanding LLM s’ Fluid Intelligence Deficiency: An Analysis of the ARC Task
论文链接:
https://arxiv.org/abs/2502.07190
代码链接:
https://github.com/wujunjie1998/ LLM -Fluid-Intelligence
论文录用:
NAACL 2025 main conference

动机
LLM 在诸多任务上展现出了卓越的能力,因此,一个自然的问题是:LLM 是否已具备与人类相当的智能水平?在认知科学中,智能通常被划分为晶体智能和流体智能。其中,流体智能被认为更为关键,因为它代表了一种自主推理和解决问题的能力。

任务设计
2.1 数据集选择
现有研究通常使用归纳推理数据集来评估模型的流体智能。然而,这些数据集大多存在于 LLM 的训练语料中,使得模型能够借助晶体智能在这些任务上取得接近人类水平的表现。
然而,如表 1 所示,即便是强大的 GPT-4o 模型 在 ARC 这一归纳推理任务上的表现仍远低于人类水平,这表明 ARC 适合作为衡量 LLM 流体智能的评测基准。

2.2 任务及数据格式
如表 1 所示,一个 ARC 任务由三个样例输入-输出的二维网格组成。模型需要从这三个样例中找到规律,并基于该规律推导测试样例的输入网格对应的输出网格。显然,这个任务可以通过以下两种方式解决:
1. 直接使用视觉大模型处理。
2. 沿用现有工作的设定,将每个二维网格编码为 NumPy 数组(用不同的数字代表不同的颜色),然后让 LLM 处理编码后的矩阵。

如表 2 所示,直接使用 LLM 处理矩阵输入在 ARC 任务上取得了最佳表现。因此,在后续实验中,我们均采用这一形式。
2.3 结果
我们首先在 100 个 ARC 任务上评估了多个 LLM ,结果如表 3 所示:
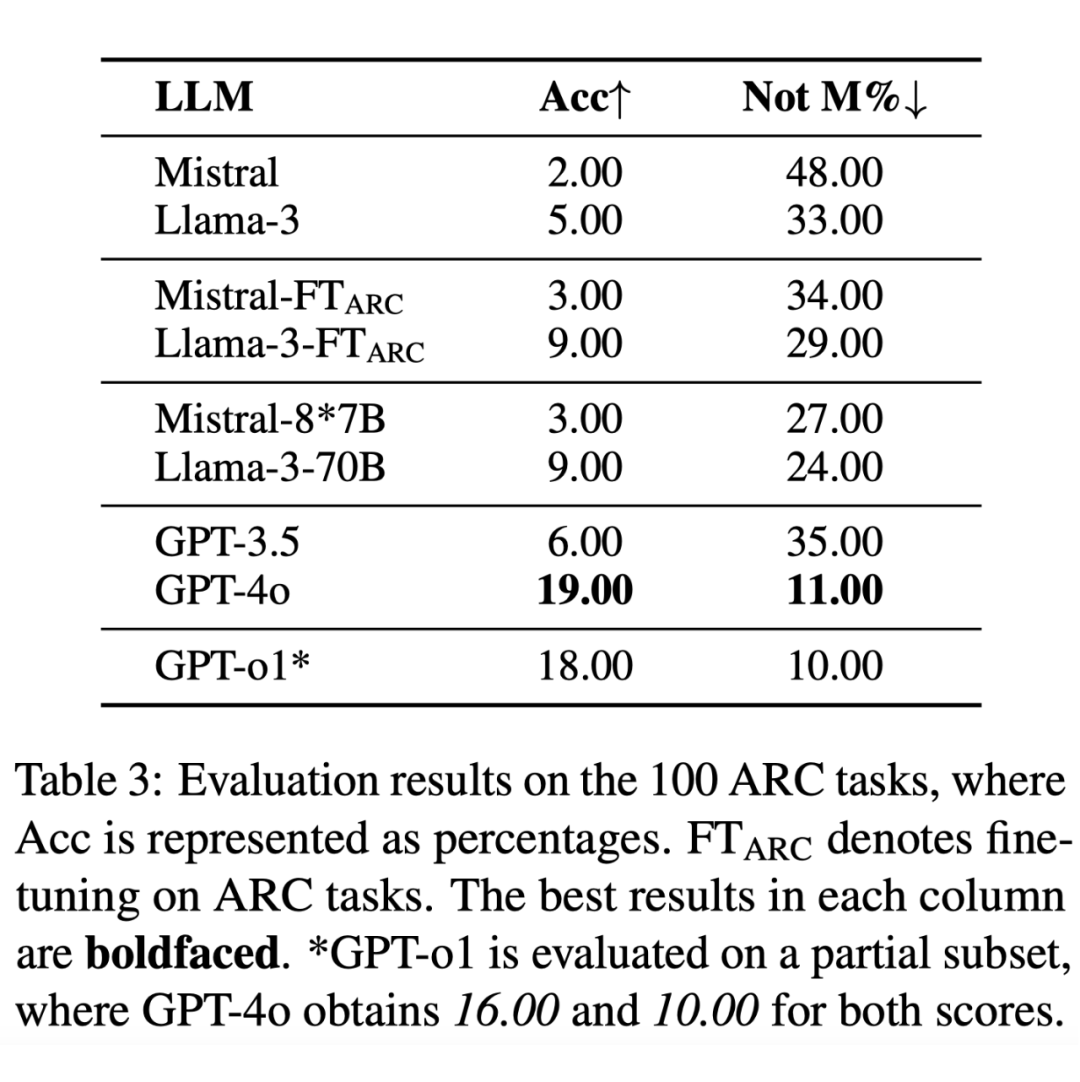
可以看到,所有 LLM 在 ARC 上的表现都不理想。我们怀疑这可能是因为大模型不熟悉 ARC 任务而导致的。于是,我们在 400 个跟评测使用的 ARC 任务不重叠的任务上微调了 Mistral 和 Llama-3 这两个模型,发现即使经过了微调,LLM 的表现仍不尽人意。

ARAOC 数据集
3.1 数据集构建
由于 ARC 任务中的每个规律都可以拆解为多个原子操作,我们决定将复杂的 ARC 任务降级为由原子操作组成的更简单任务,以进一步研究大模型在流体智能方面的缺陷。
在本文中,我们提出了六种基本的原子操作,这些操作能够构成大部分 ARC 任务,如表 4 所示:

3.2 结果
随后,我们参考 ARC 任务的格式,为每种原子操作构建了 100 个任务,形成了一个新的 ARAOC(Abstraction and Reasoning on Atom Operation Corpus)数据集,并在此数据集上评估大模型的流体智能,实验结果如表 5 所示:

可以看出,即便是面对简单的原子操作(例如 Move 和 Copy),大语言模型依然难以依靠流体智能完成这些任务。
3.3 分析
为了探究 LLM 为何在某些原子操作上表现不好,我们进一步做了两个分析实验来分别探究原子操作本身的复杂程度和输入输出网格的大小对 LLM 流体智能的影响如表 6 表 7 所示:
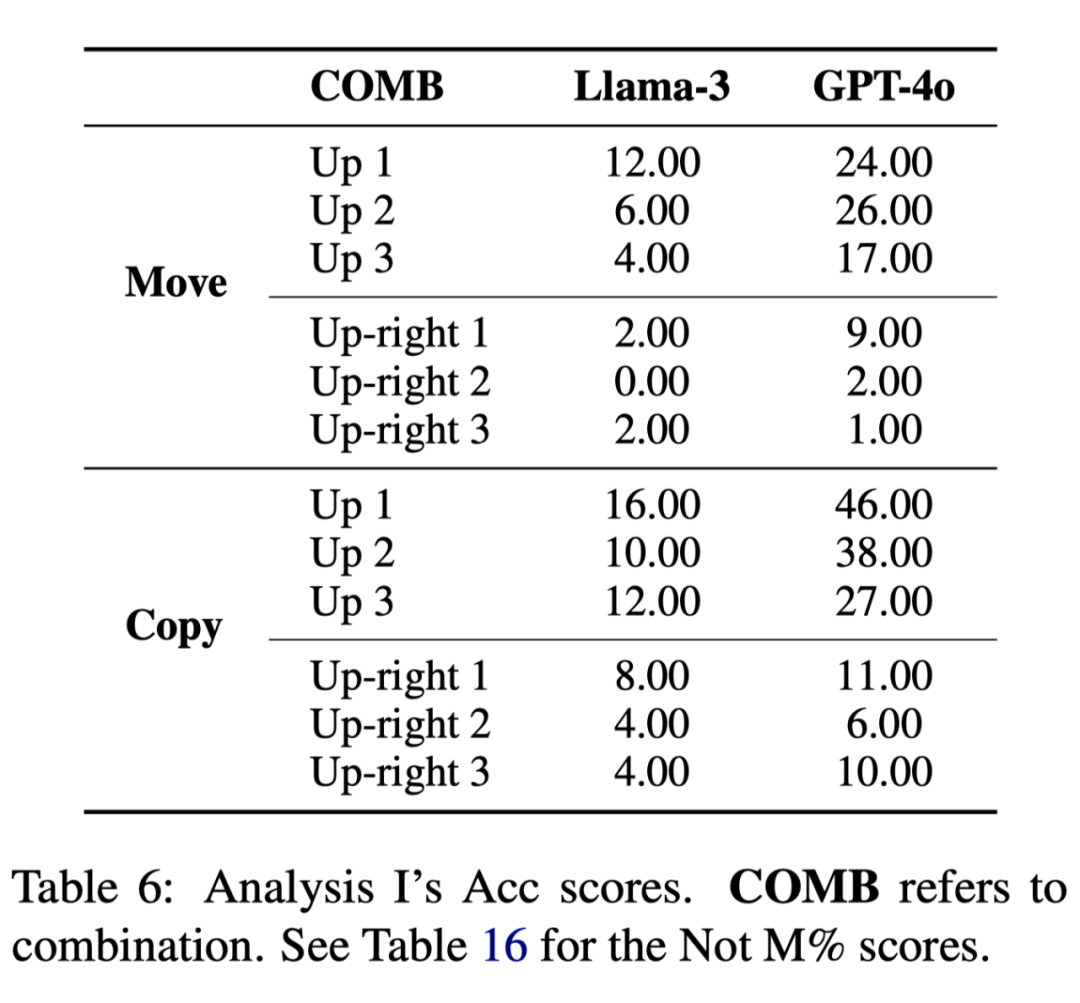
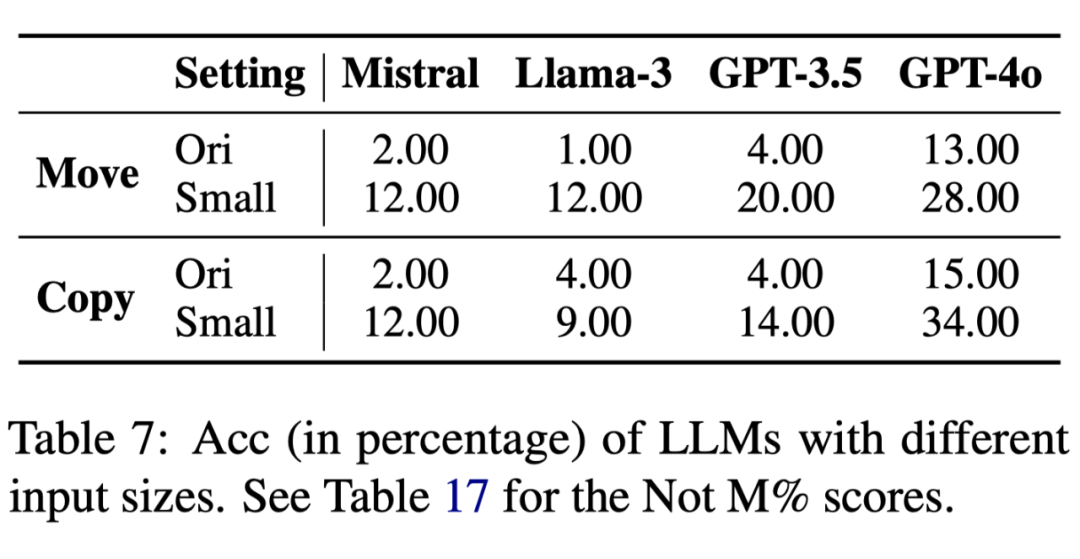
实验结果表明,当原子操作变简单以及网格大小变小后, LLM 的表现显著变好。这表明 LLM 在解决 ARAOC 任务时偏向于关注与记忆任务中浅显的表征(类似于运用晶体智能),而并非直接运用推理和逻辑能力来解决问题(流体智能)。
因此,我们在接下来的章节中从三个角度进一步研究了为什么 LLM 在解决任务时缺乏流体智能。

核心瓶颈
4.1 组合泛化能力
我们首先从组合泛化能力的角度研究 LLM 缺乏流体智能的原因。为此,我们设计了两个实验:
1. 组合 Move 和 Copy 这两个原子操作来构建新的任务,以评测 LLM 在简单组合泛化上的表现。
2. 将 ARC 任务视为多个原子操作的复杂组合泛化,以进一步评测 LLM 的能力。
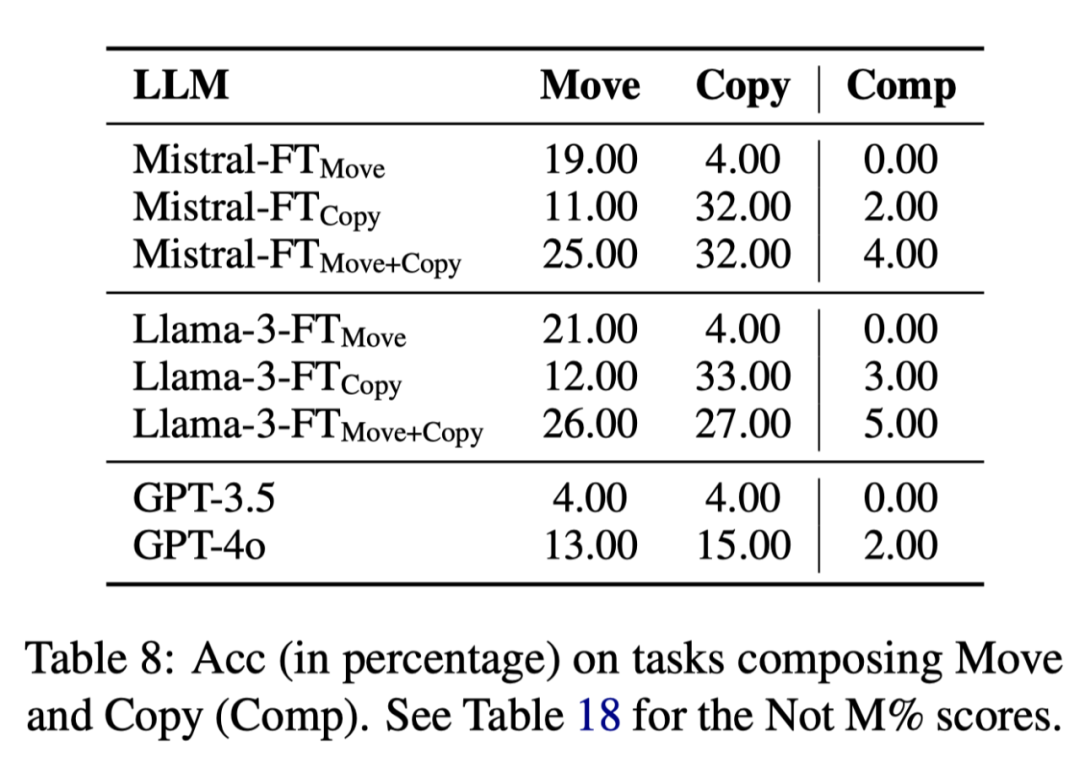
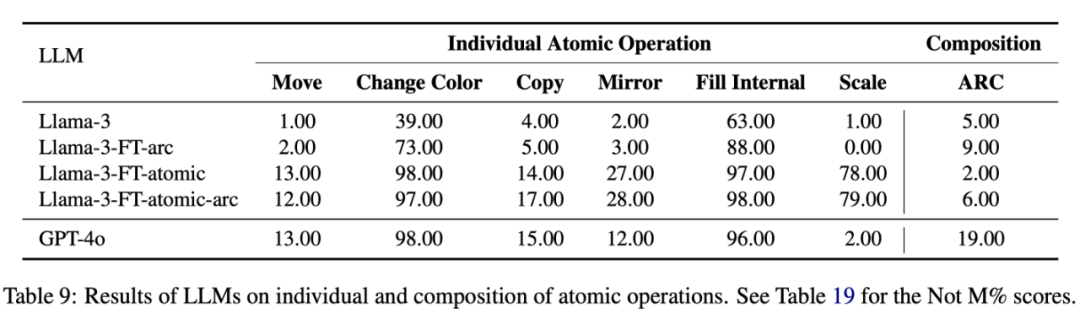
实验结果表明,LLM 在原子操作组合泛化后的任务上表现大幅下降,即便经过微调,其在组合泛化任务上的表现仍然不尽人意。这进一步揭示了 LLM 缺乏内在的抽象推理机制–流体智能的核心特征。
4.2 表征抽象能力
其次,我们从表征抽象能力的角度探讨 LLM 缺乏流体智能的原因。由于我们的任务输入采用矩阵形式,我们推测 LLM 对这种输入形式的熟悉程度可能会影响其流体智能的表现。为此,我们首先研究 LLM 是否能够理解这些矩阵输入:
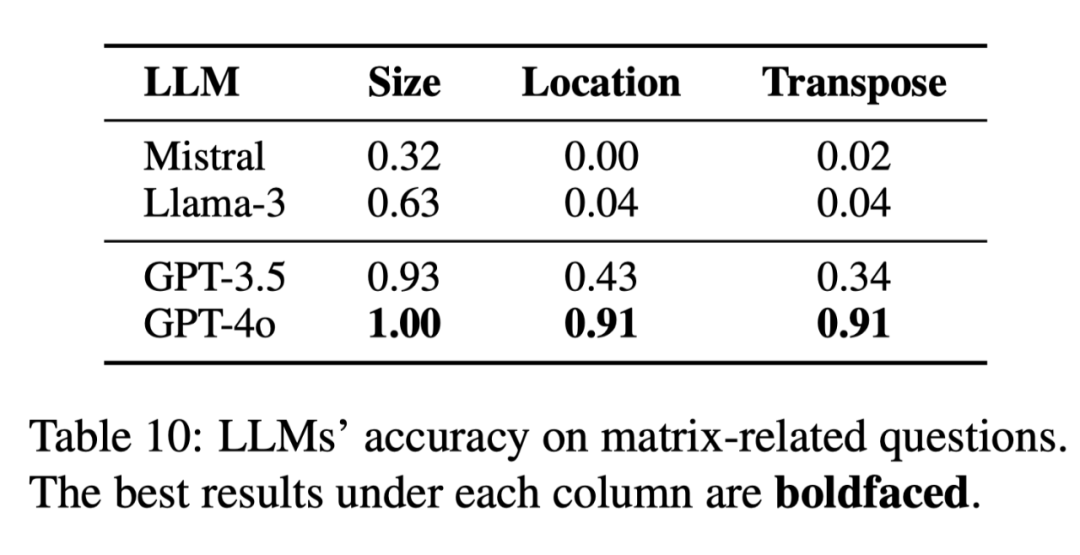
如表 10 所示,除了 GPT-4o 之外,其他 LLM 在理解矩阵输入方面均存在明显问题。然而,即便 GPT-4o 能够正确理解输入矩阵,它在 ARC 和 ARAOC 任务上展现出的流体智能水平仍然不尽如人意。
为了进一步验证这一问题,我们设计了另一项实验,将矩阵输入转换为自然语言形式,并让 LLM 进行处理:
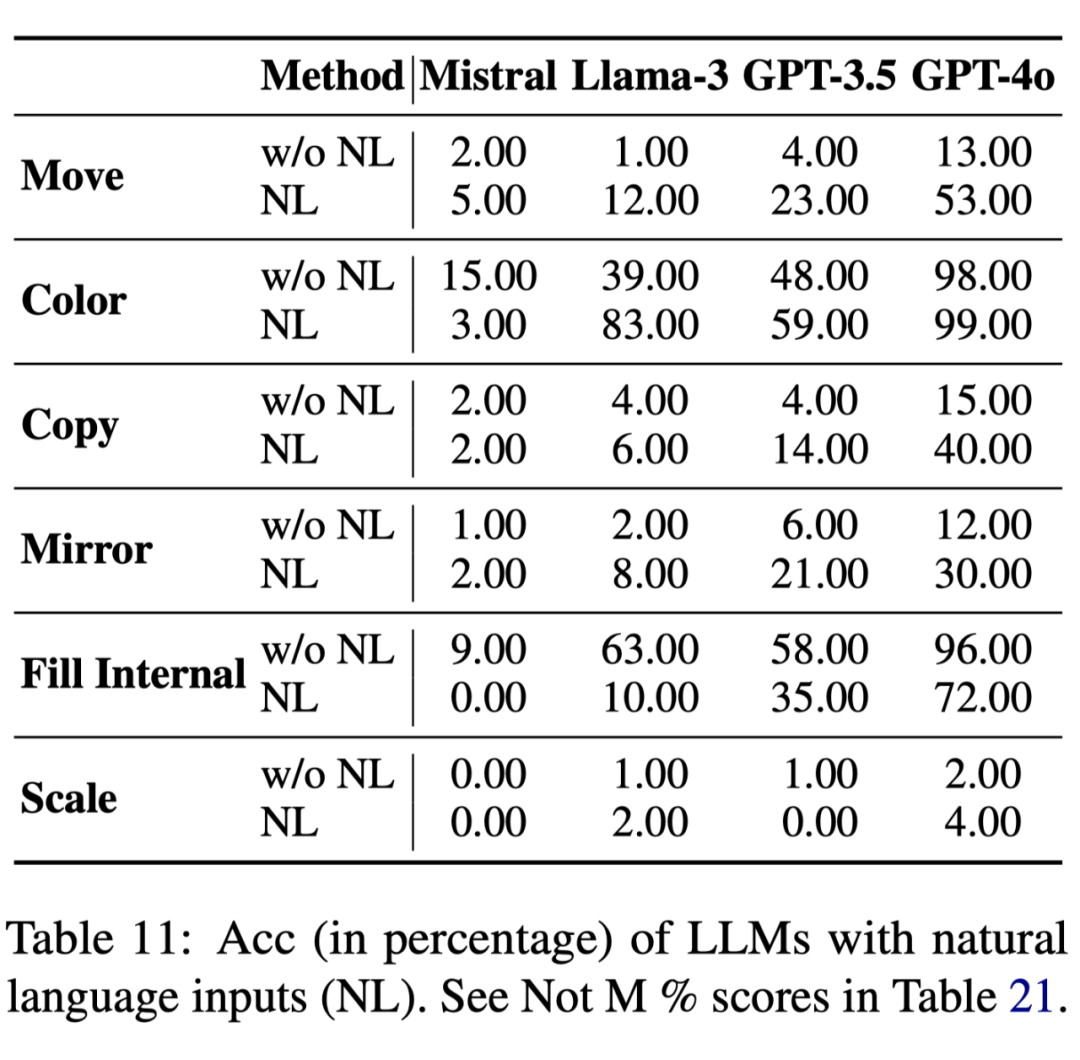
实验结果表明,使用自然语言输入后,LLM 在原先表现不佳的原子操作任务上的表现得到了显著提升。
然而,即便经过这一转换,其整体表现仍然未达到理想水平。因此,我们得出结论:LLM 在 ARC 和 ARAOC 任务上的流体智能缺失并非由于矩阵输入的影响,而是源于其无法有效理解抽象的输入表征。
4.3 模型架构
最后,我们探讨 LLM 的模型架构是否会影响其流体智能。首先,我们希望验证 LLM 采用自左向右的自回归解码方式是否会影响其流体智能表现。为此,我们使用 Mirror 子操作,分别构建了向左和向右 Mirror 的 100 个任务来评测 LLM,实验结果如下:
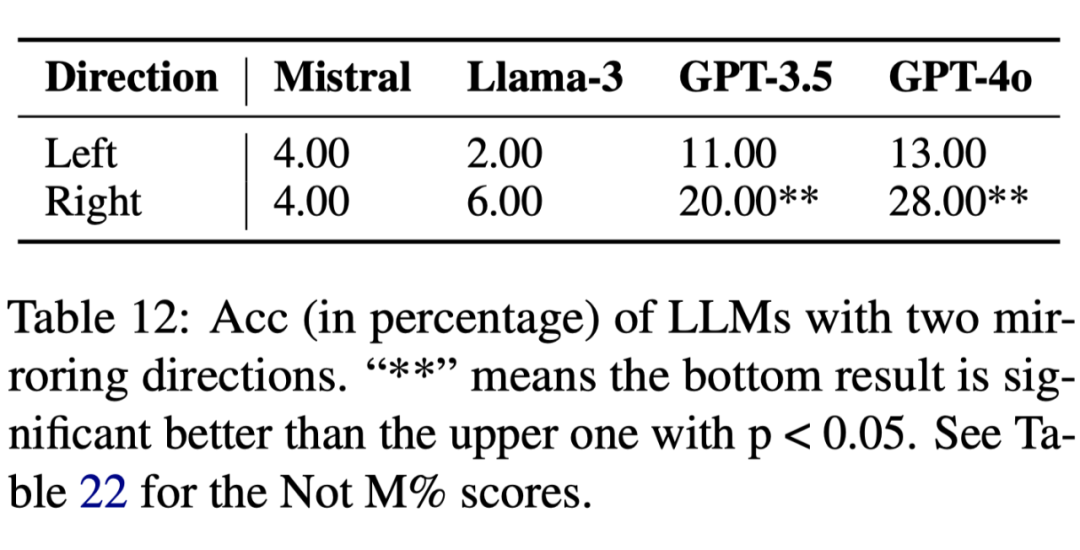
实验结果表明,LLM 在 Mirror 方向向右时的表现明显优于向左时,这与我们的假设一致:当 Mirror 方向向左时,由于自回归生成的特性,LLM 在生成新网格时尚未触及原有网格的信息,从而导致结果下降。
此外,由于 ARC/ARAOC 任务实际上遵循了 in-context learning 的设定——即从三个给定的输入输出对中实时学习规律并应用到测试对上,我们希望进一步研究 LLM 在这个 in-context learning 过程中是否能够正确识别出哪些信息对于解决任务是关键的。
因此,我们绘制了一个 LLM 正确作答的示例 saliency 图,如图 1 所示:

总的来说,LLM 的内部架构限制了其访问全局信息的能力,而这一能力对于展现流体智能至关重要,因此,这种限制进一步阻碍了 LLM 在流体智能方面的表现。
(文:PaperWeekly)