

今天是2025年3月3日,星期一,北京,天气晴。
我们今天来看下昨日以及上周的进展早报,总结过去进展,发现一些有趣的问题,比如模型参数融合的玩法,会有更多收获。

围绕模型参数融合,MOE可视化图解,deepseek开源周总结,发展时间线等主题,供各位参考。
专题化,体系化,会有更多深度思考。大家一起加油。
一、关于deepseek开源周总结及时间线回顾
1、关于deepseek开源周总结
DeepSeek开源周的总结, https://github.com/deepseek-ai/open-infra-index
1)FlashMLA
一个高效的MLA解码内核,针对HopperGPU优化,适合变长序列。主要问题在于优化变长序列的解码效率。效果上,内存带宽达3000GB/s,计算性能达580TFLOPS(H800)。意外细节方面,它的性能在生产环境中已验证,适合实际应用。
2)DeepEP
专家并行(EP)通信库,适用于MoE模型的训练和推理。主要问题在于,提升MoE模型的通信效率,兼顾高吞吐量和低延迟。效果上,训练阶段高吞吐量,推理阶段低延迟,具体性能见技术报告。意外细节方面,支持NVLink和RDMA,适应不同网络环境。
3)DeepGEMM
FP8GEMM库,支持密集和MoEGEMM,驱动V3/R1训练和推理。主要问题在于,优化FP8矩阵乘法,适应多种矩阵形状。效果上,HopperGPU上达1350+TFLOPS,核心代码仅300行。意外细节方面,性能超过专业优化内核,代码简洁如教程。
4)DualPipe
双向流水线并行算法,优化V3/R1训练中的计算-通信重叠。主要问题在于,减少流水线中的计算和通信空隙。效果上,实现前向和后向阶段的完全重叠,减少性能瓶颈。意外细节方面,内存使用策略独特,适合大规模训练。
5)EPLB
专家并行负载平衡器,优化V3/R1的GPU负载分配。主要问题在于,平衡专家并行中的GPU负载,减少通信开销。效果上,降低跨节点数据流量,确保预填充和解码阶段性能。意外细节方面,支持两种策略,适应不同集群规模。
6)ProfileData
分析V3/R1中的计算-通信重叠,提供优化洞见。主要问题在于,理解计算和通信的交互,寻找优化空间。效果上,提供数据支持系统优化,但具体效果未详述。意外细节方面,可能因仓库不可访问而信息有限。
7)3FS
Fire-Flyer文件系统,利用现代SSD和RDMA网络,服务AI工作负载。主要问题在于,提供高性能存储,满足AI训练和推理需求。效果上,读取吞吐量达6.6TiB/s,GraySort达3.66TiB/min。意外细节方面,支持KVCache查找,峰值达40+GiB/s。
8)Smallpond
基于3FS的数据处理框架,构建于DuckDB上。主要问题在于处理PB级数据集,高效无长服务。效果上,30分钟14秒内排序110.5TiB,吞吐量3.66TiB/min。意外细节方面,依赖3FS,适合大规模数据分析。
9)DeepSeek-V3/R1推理系统概览
优化V3/R1推理系统的吞吐量和延迟。主要问题在于,提升实时AI服务的性能和成本效益。效果上,每H800节点输入73.7k令牌/秒,输出14.8k令牌/秒,成本利润率545%。意外细节方面,实际收益受定价策略影响,夜间折扣降低成本。
2、过去1周AI领域进展
1)xAI的Grok3和DeepSearch
xAI的Grok3于2月17日发布,经过我们的使用评测,整体能力已经提升到第一梯队(o1,claude,deepsek)。xAI同时发布了DeepSearch,类似于下一代搜索引擎,增强了搜索能力。DeepSearch起初开放到XPremiumPlus用户以及x.ai的付费用户,现在已经开放到免费用户使用。Grok3,DeepSearch目前还没有开放API。
地址在:https://x.ai/blog/grok-3 https://www.cnet.com/tech/services-and-software/musks-xai-launches-grok-3-heres-what-you-need-to-know/
2)Anthropic的Claude3.7和ClaudeCode
Anthropic于2月24日发布了Claude3.7Sonnet,这是一个混合推理模型,用户可以选择快速响应或深入思考模式,特别在编码任务上表现突出。同时,ClaudeCode作为研究预览版,提供了一个活跃的编码协作工具。Claude3.7Sonnet对免费用户,付费用户开放,同时API对所有付费用户开放。Claude3.7Sonnet出来之后广受好评,已经在Cursor/windsurf等产品中集成。
地址在:https://ghuntley.com/tradecraft/,https://www.anthropic.com/news/claude-3-7-sonnet
3)DeepSeek的开源周:DeepSeek从2月24日起启动了开源周活动,每天发布一个开源仓库,共8个,涵盖其生产测试的AI基础设施工具,旨在推动社区创新。
地址在:https://github.com/deepseek-ai/open-infra-index
4)Google的GeminiCodeAssist:Google于2月25日发布了GeminiCodeAssist的免费版,个人开发者每月可享受高达18万次代码补全,远超GitHubCopilot的免费限额,适合学生和小型团队。
地址在:https://blog.google/technology/developers/gemini-code-assist-free/
5)阿里巴巴的视频生成模型:阿里巴巴于2月25日发布了开源视频生成模型Wan2.1系列,支持从文本和图像生成高质量视频,免费提供给全球学术和商业机构。
地址在:https://www.alizila.com/alibaba-cloud-open-sources-its-ai-models-for-video-generation/
6)OpenAI的GPT-4.5:OpenAI于2月27日推出了GPT-4.5,仅对200美元/月的Pro订阅用户开放,号称是迄今为止最大、最强大的模型,减少了幻觉现象,增强了情感理解。 同时OpenAI对Plus用户开放了DeepResearch功能,Plus用户一个月可以用10次。GPT-4.5的API也已经开放到tier5的用户。
地址在:https://openai.com/api/pricing/ https://api-docs.deepseek.com/quick_start/pricing
3、关于deepseek发展时间线总结
Transformer(2017)到DeepSeek-R1(2025)
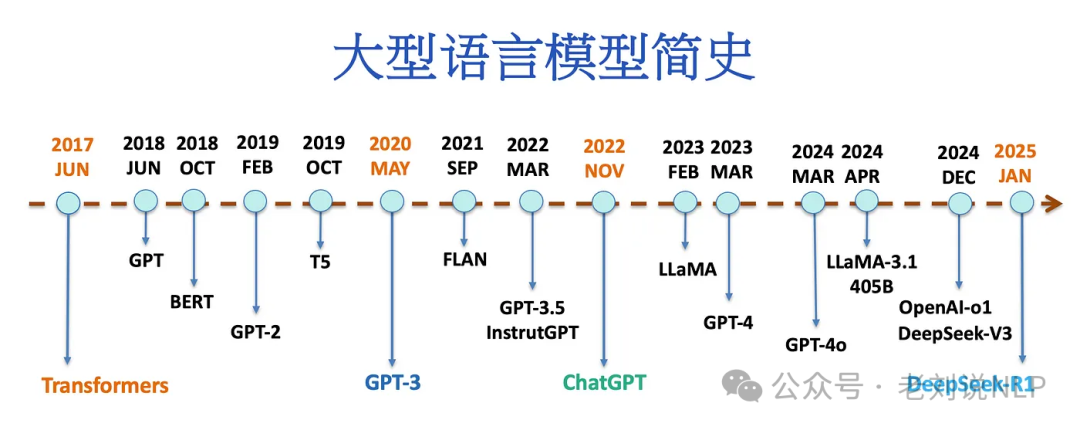
地址在:https://medium.com/@lmpo/%E5%A4%A7%E5%9E%8B%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E7%AE%80%E5%8F%B2-%E4%BB%8Etransformer-2017-%E5%88%B0deepseek-r1-2025-cc54d658fb43
二、关于模型参数融合及几个具象化理解
1、关于多任务模型融合的思路
进一步的,有一个工作Tiny-R1-32B,这个工作,有个点可以看看就是模型参数融合+蒸馏数据。
【注意】基于Deepseek-R1-Distill-Qwen-32B,应用监督微调(SFT)来适应模型到三个特定领域数学、编程和科学,模型Deepseek-R1基于种子问题为每个领域(数学、编程和科学)生成适当的响应。由此进行微调,产生了三个专业化模型,每个领域一个:数学模型、编程模型和科学模型,然后使用Mergekit工具(由Arcee团队开发)将这三个专业化模型合并成一个统一的模型,得到Tiny-R1–32B-Preview。
但是,我们进一步地去想,其实我们之前都有lora的思路,一个任务,一个lora,这也是一条路。
但是,我们进一步地去想,其实我们之前都有lora的思路,一个任务,一个lora,这也是一条路。但需要多出不同任务的lora权重,所以,最好的方式,假设模型能力强,还是想着说,用一个模型全做了。
这个lora,顺带说下,LoRA(Low-Rank Adaptation)是一种适用于大规模模型的参数高效微调方法,基本思想是通过在模型层中引入低秩矩阵,将大模型的权重降维处理,以此实现高效的模型适配。相比于传统的微调方法,LoRA不仅能大幅减少所需的训练参数,还降低了显存占用,从而加快了模型微调速度。
在实现方式上,可以使用VLLM,在多LoRA部署中将每个LoRA模块视为独立的适配组件,其提供多LoRA部署的优化策略,支持同时加载多个LoRA模块,使得VLLM可以在不同任务间快速切换,提高多任务推理的效率。
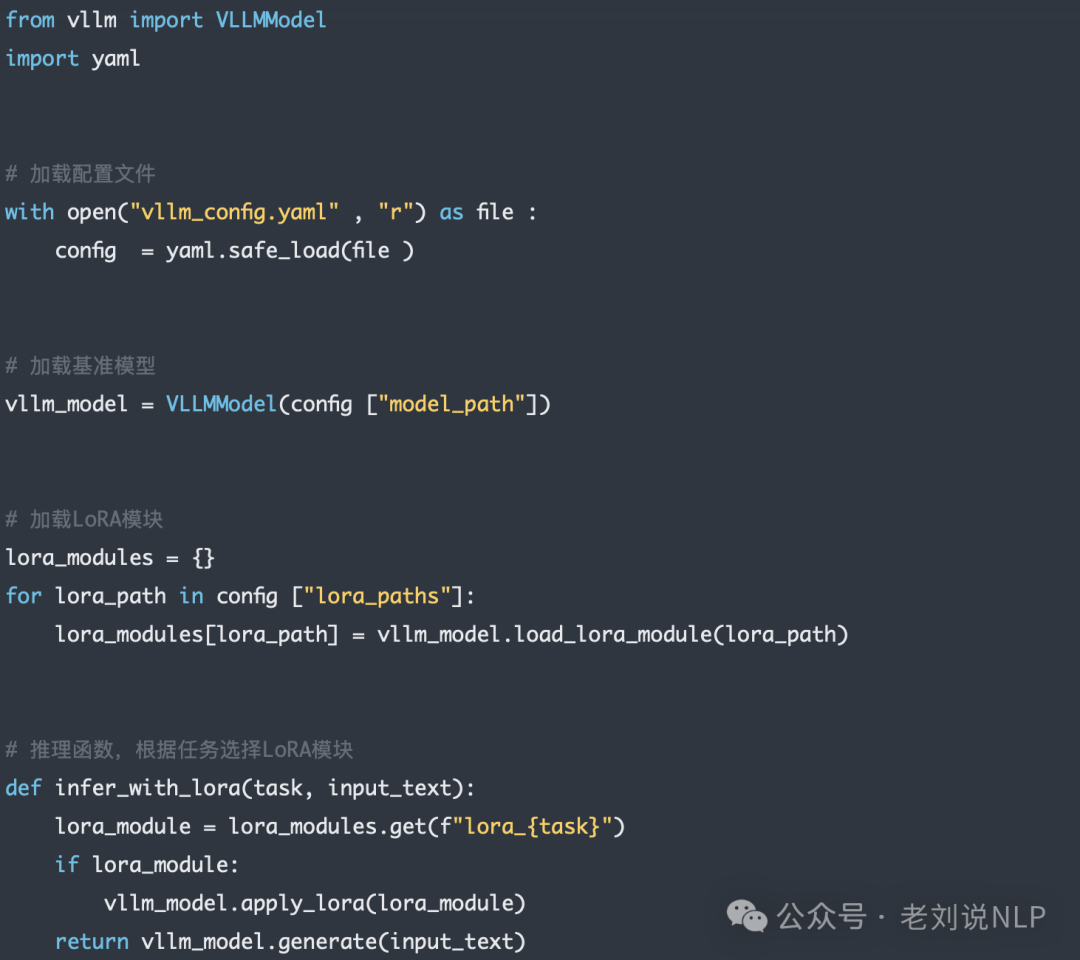
所以,在多语言对话系统中,每种语言都可以微调成一个LoRA模块,通过VLLM多LoRA部署实现多语言快速切换。
对于内容生成类任务,如电商、教育、医疗等,每个领域的LoRA模块可以适配该领域的专有词汇和风格,实现针对性内容生成。在客服、搜索引擎等场景中,针对不同的用户需求动态切换LoRA模块,提升服务响应速度与个性化程度。
如果不想做lora,那么那就会有两条路。
一个是数据上做多阶段训练,也就是课程式学习,先微调任务1,再微调任务2,再微调任务3,最终得到一个模型。但这个依赖于任务数据的优先级,学习的阶梯性,依赖性。当然,也可以一股脑的混合数据集去训
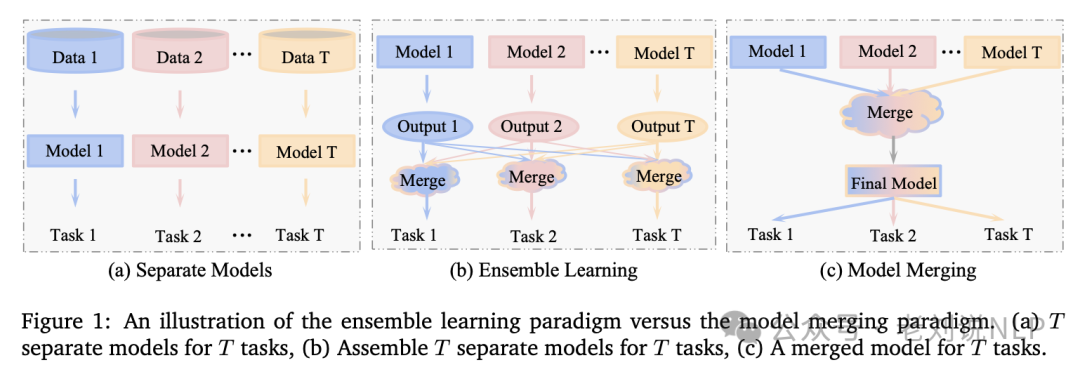
另外一条路,就是走分治融合路线,就是上面所说的,每个任务都训练一个单模型,然后再进行模型合并,这其实是有损的。所以说,这个也蛮有趣的。也延伸出了几条不同的路线。
而说到模型合并,允许将多个模型合并成一个模型。这样做不仅可以保持质量,还可以获得额外的好处。假设有几个模型一个擅长解决数学问题,另一个擅长编写代码。在两种模型之间切换是一个很麻烦的问题,但是我们可以将它们组合起来,利用两者的优点。

又如,将专门的医疗模型 Meditron-7B与通用的Llama2-7B Chat进行合并,结果显示合并后的模型在USMLE和MedMCQA 等基准测试中表现优异。
这个需求有**开源工具Mergekit(https://github.com/arcee-ai/mergekit)**,支持多种合并方法,MergeKit 支持包括线性权重平均、球面线性插值(SLERP)、任务算术、TIES、DARE 等多种算法。
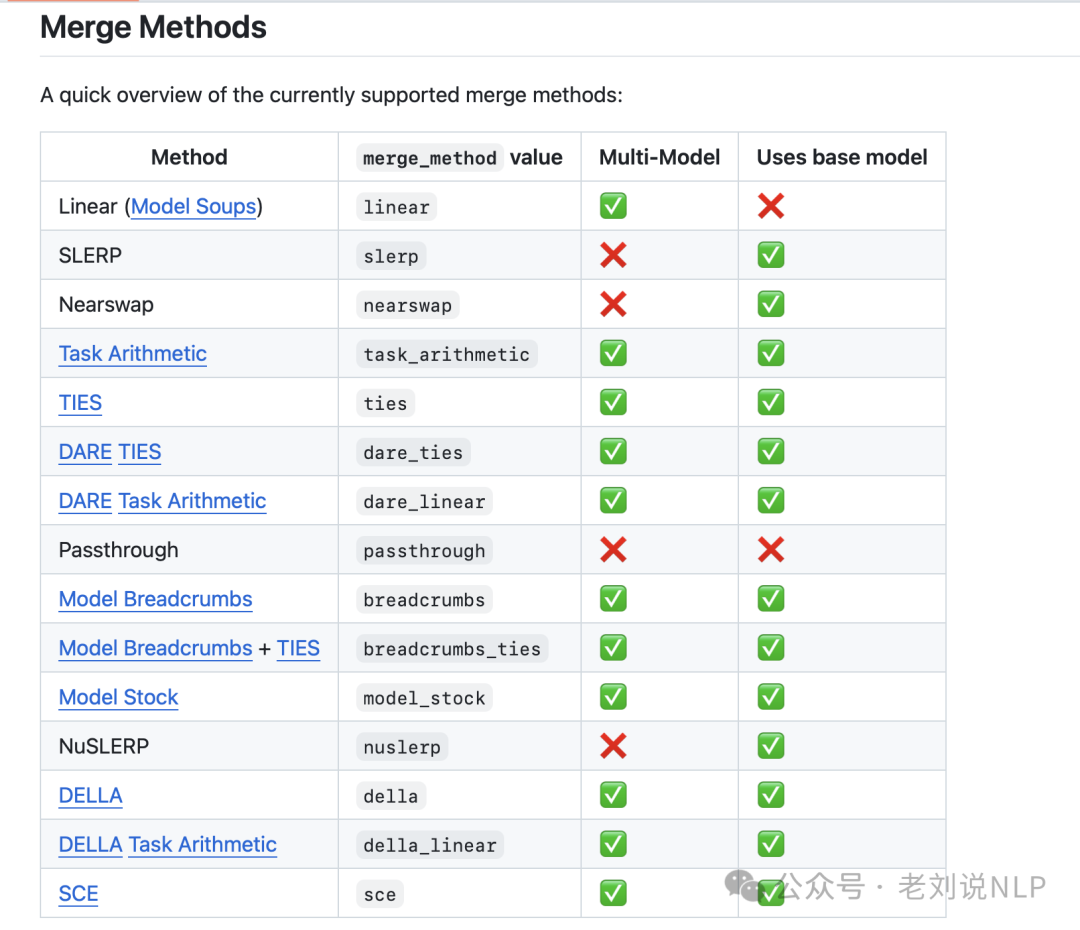
顺带的,针对模型融合这个话题,可以看一个技术总结,Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities,https://arxiv.org/pdf/2408.07666,https://github.com/EnnengYang/Awesome-Model-Merging-Methods-Theories-Applications
2、关于大模型的一些具象化理解
这位作者很maartengrootendorst很优秀,做了很多具象化的科普。
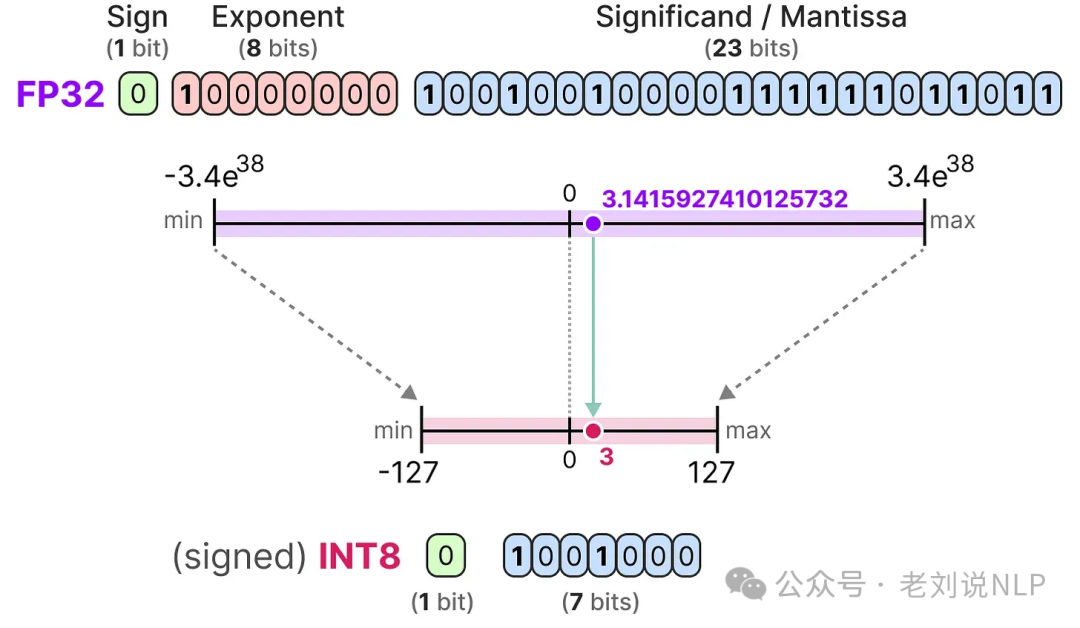
1)A Visual Guide to Quantization, https://substack.com/@maartengrootendorst/p-145531349;
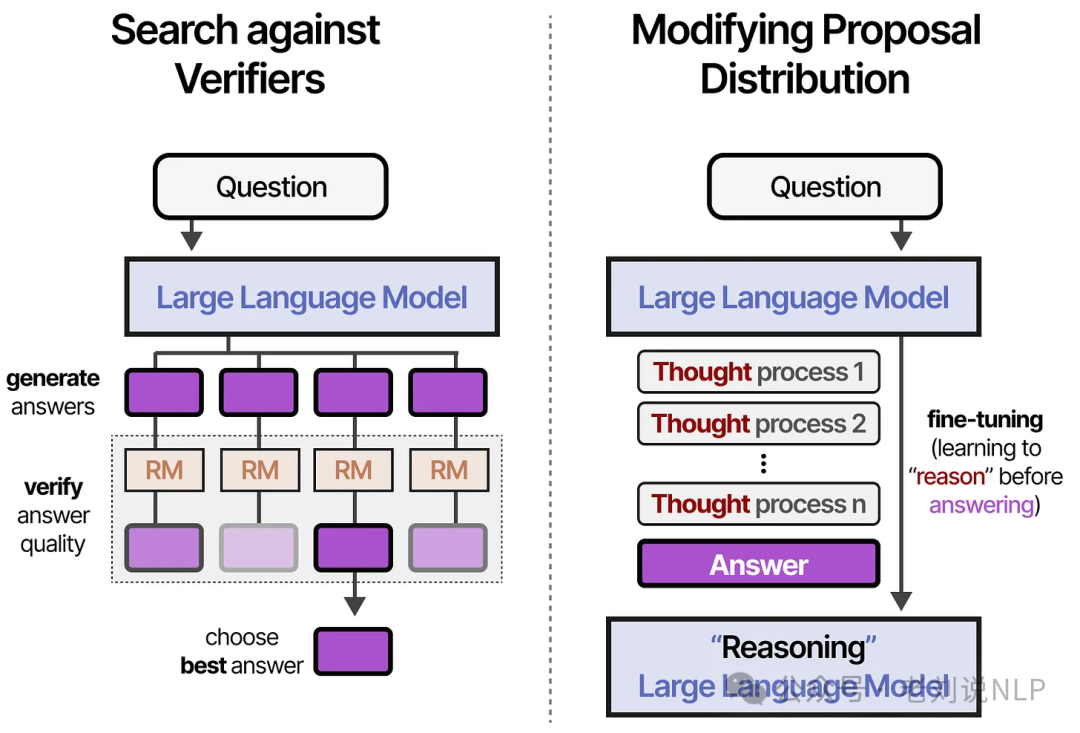
2)A Visual Guide to Reasoning LLMs,https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-reasoning-llms;
3)A Visual Guide to Mixture of Experts (MoE),https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts; https://files.mdnice.com/user/67015/db994526-1c19-4b69-860b-68d7c6e657b4.png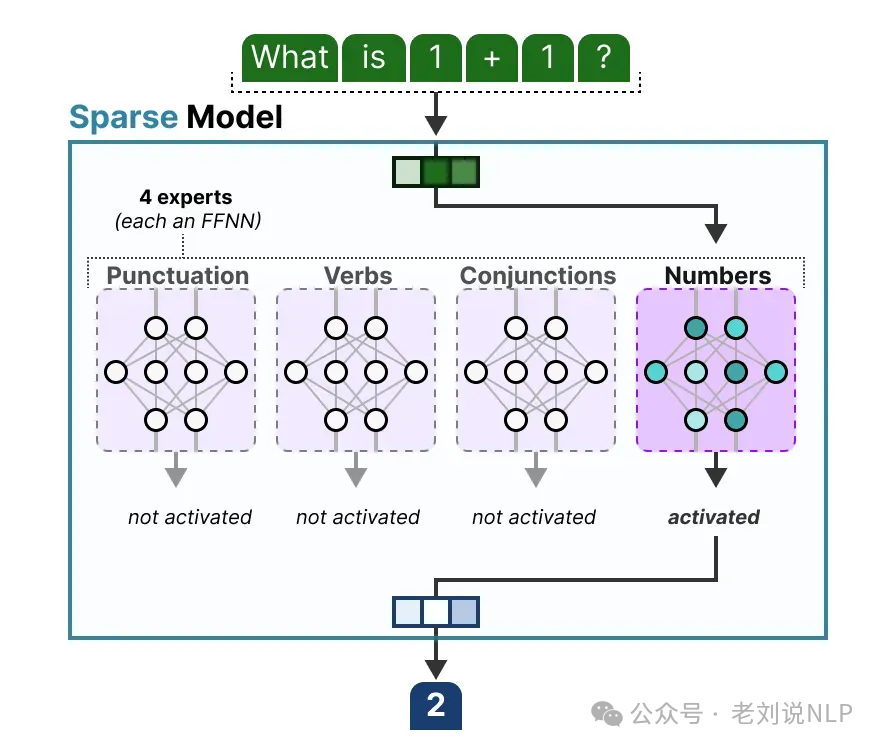
4)A Visual Guide to Mamba and State Space Models,https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mamba-and-state
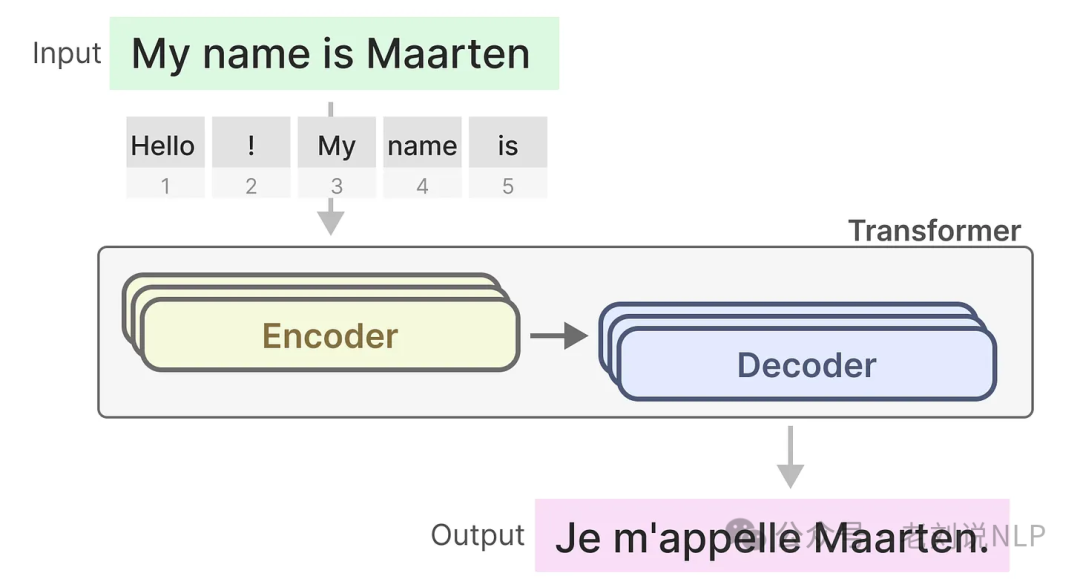
这些可视化增进大家对某个技术的理解是很有帮助的。
总结
本文主要围绕模型参数融合,MOE可视化图解,deepseek开源周总结,发展时间线等主题做了一些回顾性总结,很有意义。
大家可以多看看,仔细消化。
参考文献
1、https://github.com/deepseek-ai/open-infra-index
(文:老刘说NLP)