


本研究提出了一种基于辩论的弱监督对齐强模型方法,探索了结合 scalable oversight 和 weak-to-strong generalization 解决超级对齐问题的新范式。

论文标题:
论文作者:
收录会议:
论文链接:
-
提出结合 scalable oversight 和 weak-to-strong generalization 的新方法,在 OpenAI 的 weak-to-strong 数据集取得更好的对齐效果。
-
验证了辩论可更可靠从预训练大模型中抽取可信知识,并用于帮助训练弱监督模型。
-
验证了弱模型的 ensemble,可帮助获得更可靠的监督信号。

背景
目前 AI 对齐技术依赖于人类的标注数据,譬如用于 supervised finetuning 的 human demonstrations,亦或是用于 RLHF 和 DPO 的 human preferences。
未来超人模型(superhuman models)在一些领域会超越人类的能力,因此人类在对齐超人模型时只能提供弱监督信号。这可预期的人类监督信号的缺陷会影响未来 AI 系统的安全性。
Scalable oversight [1] 和 weak-to-strong generalization [2] 是解决上述超级对齐问题的两类方法 [3]。Scalable oversight 试图提高人类的提供监督信号的能力,使其可标注更准确的数据对齐超人模型;weak-to-strong generalization 试图微调预训练大模型,使其泛化的效果显著优于弱监督信号。
我们的工作试图结合 scalable oversight 和 weak-to-strong generalization 两类方法的优势,并更好的提升对齐效果。具体地,我们尝试用预训练大模型改善人类监督信号,并用改善的监督信号微调大模型。
为了获得可实验验证的进展,我们考虑了一个类似的设定:我们是否可以用强的大模型改善一个弱模型的监督信号,并用它监督对齐强模型?具体地,我们利用强的大模型帮助在真实标注中训练一个弱的小模型,然后利用弱模型生成的标签微调强模型。
我们发现辩论可以帮助弱模型从强模型中抽取可信的知识,这些知识可以帮助训练更好的弱模型。我们还发现弱模型的 ensemble 可以更好的利用强模型生成的辩论信息,并获得更可靠的监督信号。
在 OpenAI 的 weak-to-strong 数据集实验表明,我们的方法有更好的对齐效果。这进一步说明辩论对 weak-to-strong generalization 是有帮助的。

方法
我们提出一个新的 weak-to-strong generalization 框架,共包括以下 3 个步骤:
Step 1 通过辩论生成论点:
我们认为预训练大模型有广泛的世界知识,可以帮助很多任务。我们的目标是从不可信的强模型中,通过辩论的方式抽取可信的知识,并利用这些可信知识帮助训练更好的弱模型。
我们首先给出辩论的规则。给定一个问题以及它的两个答案候选(一个准确、一个错误),大模型的两个实例随机地被分配为这两个相反的答案争辩。
辩论基于多轮地辩手之间的文字交换。在达到辩论轮次后,辩论结束,并且辩手的论点被记录下来。在辩论过程中,每个辩手都尽力拿出证据支持自己的观点,并解释为什么对方的观点是错误的。

上图给出一个辩论的示例。我们观察到辩手 B 支持错误观点,并被激发表述错误论点。尽管如此,在下一轮,辩手A轻易的指出了辩手 B 论点的错误之处。该观察与假设“说谎比识别说谎更困难”一致 [4]。这些辩论的论点提供了有价值的信息说明了两个观点的优点和缺点,可被用于训练更好的弱模型。
Step 2 训练弱模型 Ensemble:
针对训练弱模型的每个样本,我们会额外附加上相应的辩论观点。我们在真实标注数据上利用这些增强的样本训练弱的小模型。我们注意到多轮辩论生成的论点数据会比较长,这会导致弱模型很难理解和处理。因此,我们训练了弱模型的 ensemble,使其生成的监督信号更鲁棒。
Step 3 利用弱模型 Ensemble 训练强模型:
我们最终利用弱模型 ensemble 构建的标签数据微调预训练大模型,从而获得一个对齐的强模型。具体地,我们利用弱模型 ensemble 中每个弱模型预测值的平均值构建标签数据。

实验
3.1 主实验
我们在 OpenAI 的 weak-to-strong 数据集实验,包括从 SciQ、BoolQ、CosmosQA 和AnthropicHH 转化而来的四个二分类任务。评测指标基于Accuracy 和 PGR(performance gap recovered)。
我们利用 Qwen/Qwen-7B 训练弱模型,利用 Qwen/Qwen-14B 训练强模型。如下表所示,我们的方法在四个测试集的两个指标均取得最好的效果,超过了利用 auxiliary confidence loss 的方法。

3.2 消融实验
3.2.1 Scalable oversight 方法
为了验证辩论从不可信强模型中抽取可信信息的能力,我们对比了其他两种不同的 Scalable oversight 方法:1. Consultancy;2. Market-Making。
Consultancy 只有一个预训练大模型的实例作为顾问,它被随机分配支持一个问题两个对立答案中的一个。Market-Making 只有一个预训练大模型的实例作为辩手,它支持未被弱模型选择的另一个答案。
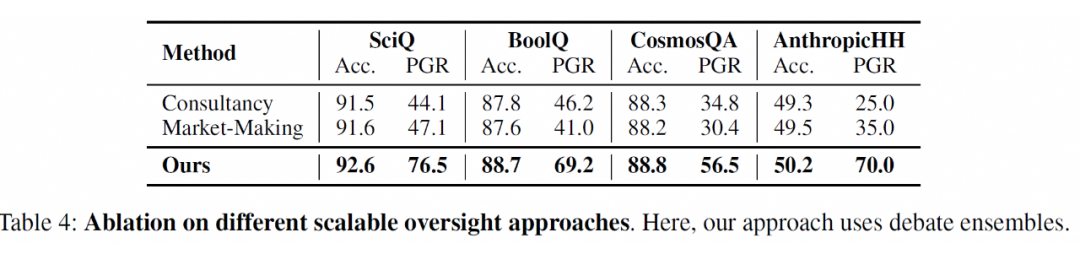
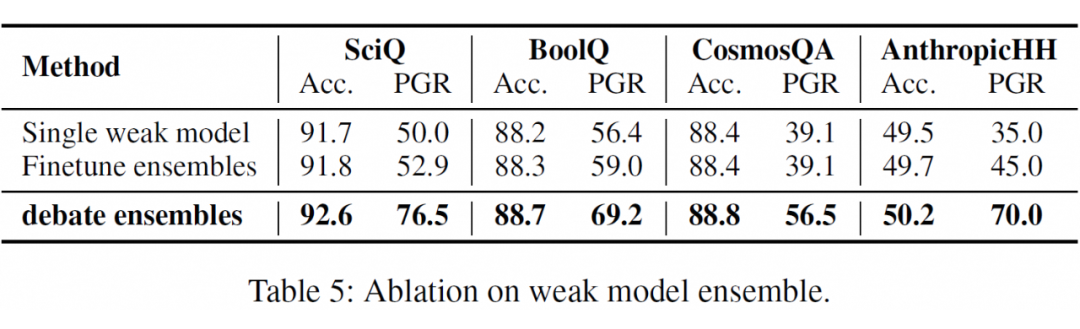
3.2.2 弱模型 ensemble
我们分析了弱模型 ensemble 在提高弱监督信号鲁棒性的作用。我们对比了其他两种弱模型方法:1. single model;2. finetune ensembles。顾名思义,single model 只训练一个弱模型。finetune ensembles 所有的弱模型成员共享一份辩论论点生成结果。

总结
本文提出一种基于辩论提高弱监督对齐强模型的方法。我们相信结合 scalable oversight 和 weak-to-strong generalization 各自的优势解决弱监督问题,一定是未来超级对齐的重要的研究方向。

(文:PaperWeekly)