
这个项目的V1版本刚出来就给大家推荐过。
OmniParser V2这几天也发布了,在GitHub一天涨1800多个星星,真的挺生猛。
当然,相对于V1版本,V2的提升确实很大。
解析电脑屏幕是AI自动化操作电脑的基础,首先要理解屏幕内容,才能进行交互。
这其中有两个关键性的问题,1)要准确的识别到界面里可以交互的图标,2)理解屏幕中各种元素的语义并将预期操作与屏幕上相应的区域关联起来。
项目简介
OmniParser 是微软开发的一个GUI自动化工具,通过将 UI 截图中的像素空间转化为结构化的元素,使大模型能够理解和操作这些界面。该工具解决了传统 LLM 在图形界面中识别可交互元素的困难,并能根据解析出的元素进行下一个操作的预测。通过与LLM 的结合,OmniParser 提供了一种高效的跨平台自动化解决方案。
DEMO
V2版本的提升
提高准确性:在检测小型可交互元素方面,准确率得到了提高。
加快推理速度:通过优化算法,使得推理速度更快。
数据集扩展:使用了更大的交互元素检测数据集和图标功能描述数据集。
减少延迟:通过减小图标描述模型的图像大小,降低了60%的延迟。
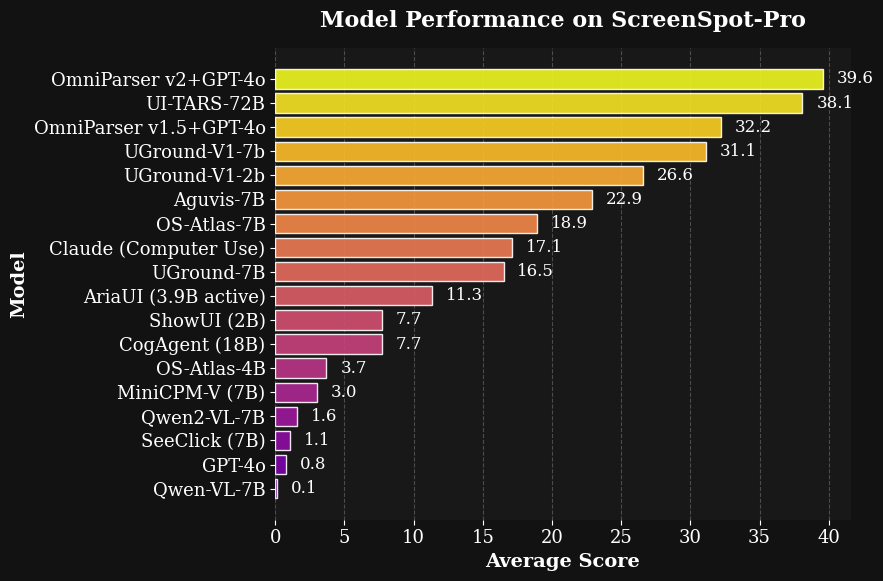
突破性成绩:在高分辨率屏幕和小目标图标基准测试 ScreenSpot Pro 上,与 GPT-4o 结合使用时,平均准确度达到了39.6,显著优于 GPT-4o 原始得分0.8。
技术特点
基于视觉的界面解析:OmniParser 通过分析 UI 截图中的像素,提取界面元素并将其转化为结构化数据,避免了依赖传统的元素标识符和代码注入方式。
支持大语言模型:该工具能够将任何 LLM 转换为计算机操作代理,使得 LLM 能理解并自动执行图形用户界面中的操作。
高效的图像解析:OmniParser 使用深度学习模型来识别和解析 UI 元素,提高了对复杂界面、按钮和文本框等小型元素的识别能力。
跨平台支持:该工具具有高度的跨平台兼容性,可以适用于多种操作系统和不同的应用程序界面。
自动化与自适应能力:OmniParser 能根据屏幕解析结果自动判断下一步操作,具有强大的自适应能力,能够处理不断变化的界面元素。
优化推理速度与精度:通过优化算法,OmniParser 在解析精度和推理速度上都有显著提升,能够高效处理复杂的 UI 任务。
与 LLM 的深度结合:通过与 OpenAI 等先进大语言模型的结合,OmniParser 提供了一个更强大且易于扩展的自动化操作平台,提升了 AI 在图形界面自动化中的表现。
项目链接
https://github.com/microsoft/OmniParser
关注「开源AI项目落地」公众号
(文:开源AI项目落地)