
GSM8K-RLVR:用强化学习提升语言模型的数学解题能力,让模型在GSM8K数据集上表现更出色。亮点:
-
不依赖预训练奖励模型,直接优化基础模型;
-
通过RLVR,模型准确率提升显著,如Qwen2.5-Math-1.5B模型准确率从70.66%提升至77.33%,提升6.67个百分点;
-
简化提示格式,无需复杂标签
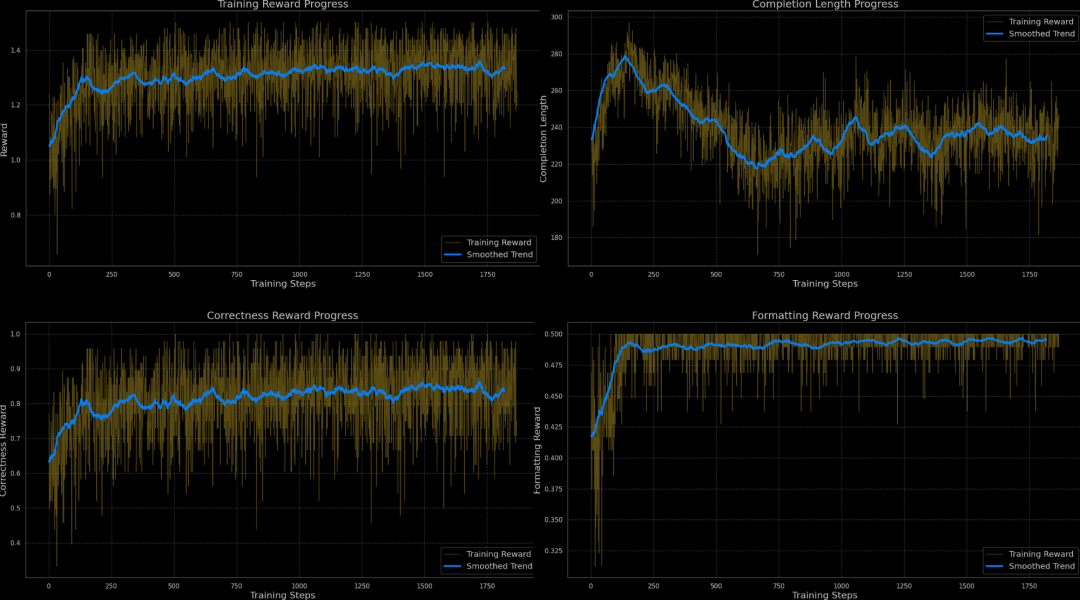
参考文献:
[1] http://github.com/Mohammadjafari80/GSM8K-RLVR
(文:NLP工程化)
GSM8K-RLVR:用强化学习提升语言模型的数学解题能力,让模型在GSM8K数据集上表现更出色。亮点:
不依赖预训练奖励模型,直接优化基础模型;
通过RLVR,模型准确率提升显著,如Qwen2.5-Math-1.5B模型准确率从70.66%提升至77.33%,提升6.67个百分点;
简化提示格式,无需复杂标签
参考文献:
[1] http://github.com/Mohammadjafari80/GSM8K-RLVR
(文:NLP工程化)